本文是对深度学习中的注意力机制做的笔记,并附上注意力机制应用的部分例子。
首先,从其功能感受下注意力机制的作用。
注意力机制让神经网络在执行预测任务时可以更多关注输入中的相关部分,更少关注不相关的部分从上述表达提取出两个关键字段:更多关注和相关部分,两者的实现直接对应着attention机制的权重如何进行分配。具体的,原文通过Encoder-Decoder模式的计算过程进行阐明。

|

|
| 图片来自这里 |
上图展示了引入attention后框架的变化:由固定的语义编码C变为根据输出不断变化的。
的计算公式如下,其中,
表示输入原句子的长度,
对应原句子中第j个单词的attention权重分配值,
对应原句第j个单词的语义编码。
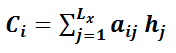
公式中的计算过程就是我们需要重点关注的注意力概率分配的处理逻辑, 下图直观展示了其计算过程:计算所有的输入语义编码
和前一时刻隐节点状态
的相似程度(图中
函数的作用),然后归一化后(图中的Softmax)即可获得每个输入单词的注意力概率分配值。

抽象为更一般的模型如下:相似度计算(阶段1)、相似度的归一化(阶段2)、计算attention值(阶段3)

由上可知,注意力机制的关键在于:计算的对象,对象间的相似度函数,归一化函数。
最后,附上几个相关的实现教程
- 基于注意力机制,机器之心带你理解与训练机器翻译系统
- Attention is all you need: A Pytorch Implementation
- 基于Attention的图片生成、分类和字符识别
扫描二维码关注公众号,回复:
5845730 查看本文章

参考文献: