1 DeepFM
在线广告数据集: Criteo Labs
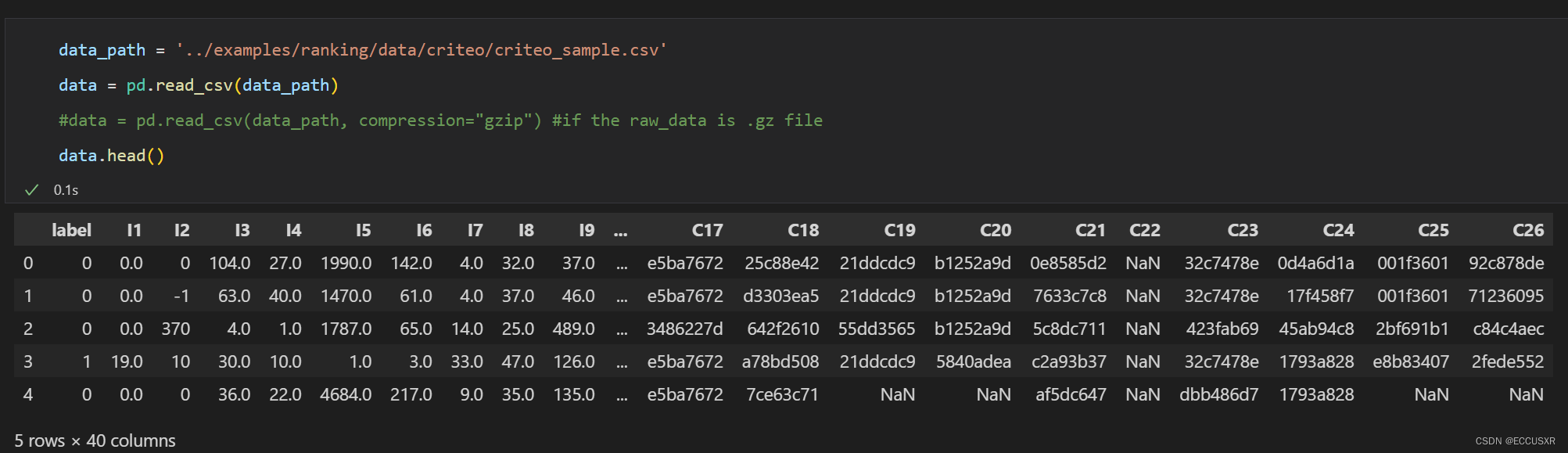
描述:包含数百万个展示广告的点击反馈记录,该数据可作为点击率(CTR)预测的基准。
数据集具有40个特征,第一列是标签,其中值1表示已点击广告,而值0表示未点击广告。 其他特征包含13个dense特征和26个sparse特征。
1.1 特征工程
- Dense特征:又称数值型特征,例如薪资、年龄。 本教程中对Dense特征进行两种操作:
- MinMaxScaler归一化,使其取值在[0,1]之间
- 将其离散化成新的Sparse特征
- Sparse特征:又称类别型特征,例如性别、学历。本教程中对Sparse特征直接进行LabelEncoder编码操作,将原始的类别字符串映射为数值,在模型中将为每一种取值生成Embedding向量。
1.2 Torch-RecHub框架
- Torch-RecHub框架主要基于PyTorch和sklearn,易使用易扩展、可复现业界实用的推荐模型,高度模块化,支持常见Layer,支持常见排序模型、召回模型、多任务学习;
- 使用方法:使用DataGenerator构建数据加载器,通过构建轻量级的模型,并基于统一的训练器进行模型训练,最后完成模型评估。
1.3 产生背景
DeepFM 是由华为诺亚方舟实验室在 2017 年提出的模型。
FM(Factorization Machines,因子分解机)拟解决在稀疏数据的场景下模型参数难以训练的问题。FM 作为推荐算法广泛应用于推荐系统及计算广告领域,通常用于预测点击率 CTR(click-through rate)和转化率 CVR(conversion rate)。
https://zhuanlan.zhihu.com/p/342803984
- 解决DNN(全连接神经网络)局限性:网络参数过大,将One Hot特征转换为Dense Vector
- FNN(前馈神经网络)和PNN(概率神经网络):使用预训练好的FM模块,连接到DNN上形成FNN模型,后又在Embedding layer和hidden layer1之间增加一个product层,使用product layer替换FM预训练层,形成PNN模型 (不懂)
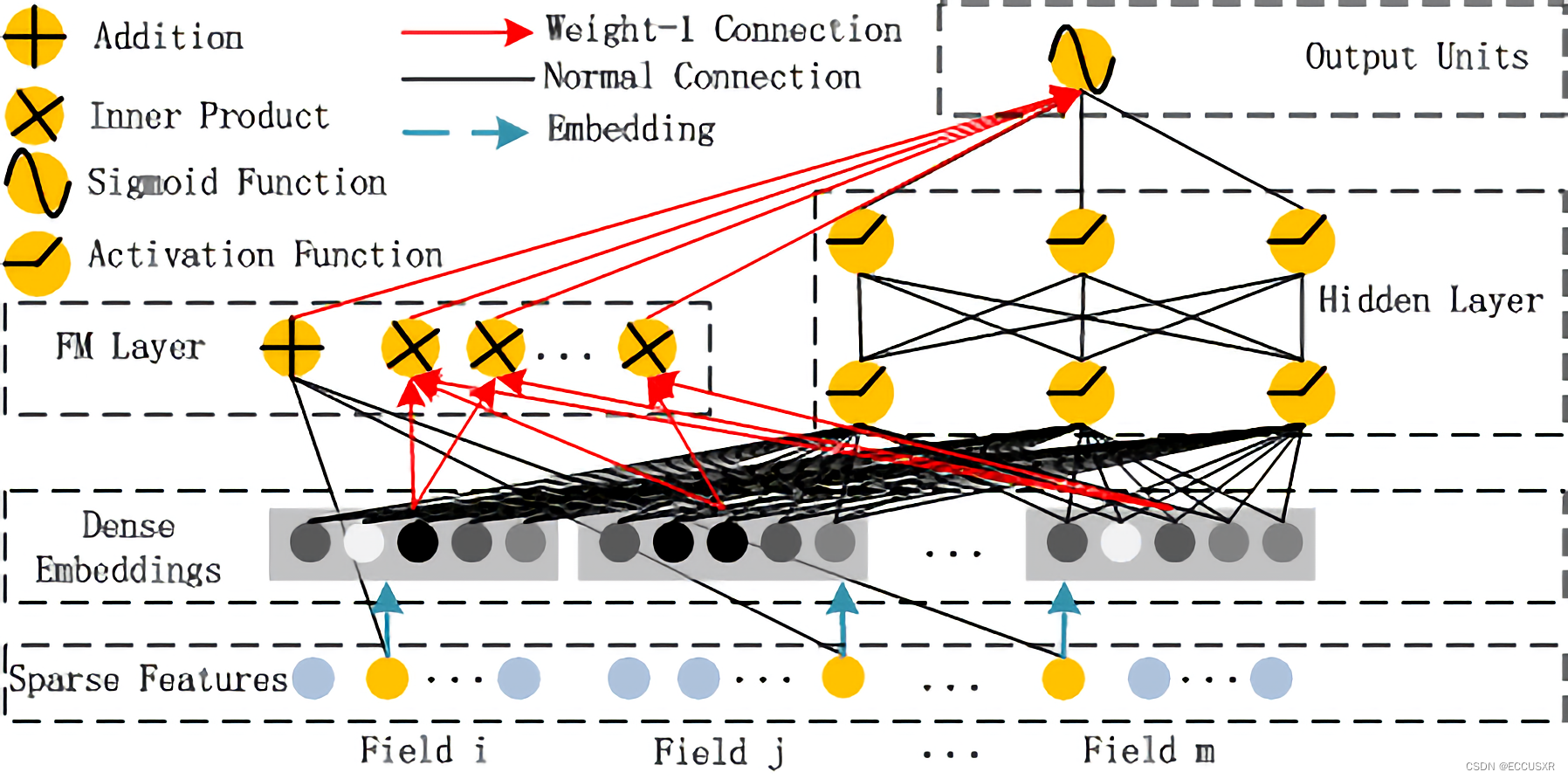
2 FM 部分
-
FM Layer主要是由一阶特征和二阶特征组合,再经过Sigmoid得到 logitcs
-
模型公式:
-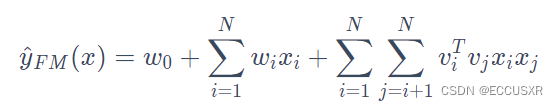
FM的模型公式是一个通用的拟合方程,可以采用不同的损失函数用于解决regression、classification等问题,FM可以在线性时间对新样本作出预测.
-
优点:
- 通过向量内积作为交叉特征的权重,可以在数据非常稀疏的情况下,有效地训练出交叉特征的权重(因为不需要两个特征同时不为零)
- 可以通过公式上的优化,得到 O(nk) 的计算复杂度,计算效率非常高
- 尽管推荐场景下的总体特征空间非常大,但是FM的训练和预测只需要处理样本中的非零特征,这也提升了模型训练和线上预测的速度.
- 由于模型的计算效率高,并且在稀疏场景下可以自动挖掘长尾低频物料,可适用于召回、粗排和精排三个阶段。应用在不同阶段时,样本构造、拟合目标及线上服务都有所不同“
-
缺点:只能显示的做特征的二阶交叉,对于更高阶的交叉无能为力。
3 Deep 部分
-
模型构成:
- 使用全连接的方式将Dense Embedding输入到Hidden Layer,解决DNN中的参数爆炸问题
- Embedding层的输出是将所有id类特征对应的embedding向量连接到一起,并输入到DNN中
-
模型公式:
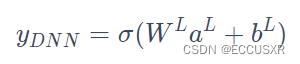
4 YoutubeDNN
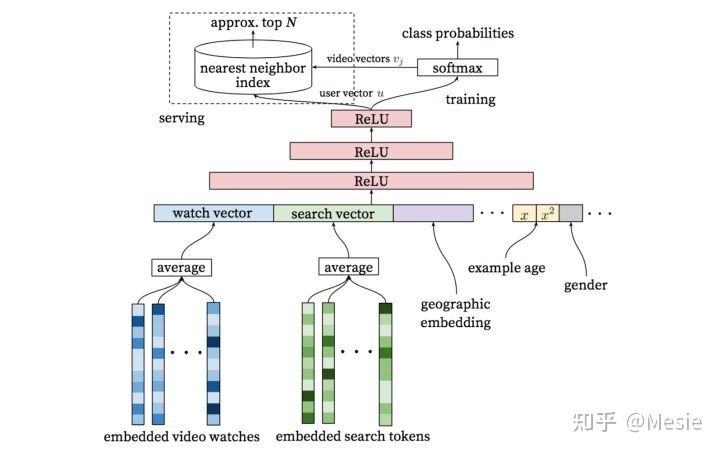
根据 User embedding和item imbedding使用nearest neighbor search 的方法召回,在softmax采用负采样。
输入数据高度稀疏,使用embeding和average pooling处理,得到用户的观看/搜索兴趣
离散型数据可使用embeding处理,连续型数据可使用归一化或分桶方式处理
-
skip-gram:采用中心词预测上下文词的方式训练词向量,模型的输入是中心词,采用滑动窗口的形式获取序列样本,得到中心单词之后,根据词向量的矩阵乘法,得到中心词的词向量,然后与上下文矩阵相乘,得到中心单词与每个单词的相似度,通过softmax得到相似概率,并选择概率最大的index输出。
将一个单词转换成one-hot向量与嵌入矩阵相乘得到嵌入向量,送进softmax得到预测结果。
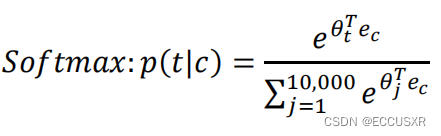
构建损失函数(假设维度有10000个):
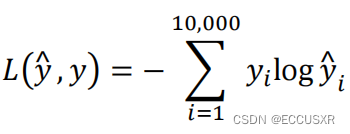
- YoutubeDNN training:右边部分类似于skip-gram,但是中心词是直接使用embedding得到,左边部分将用户的各特征向量拼接成一个大向量之后进行DNN降维
5 DSSM
Deep Structured Semantic Models 双塔模型
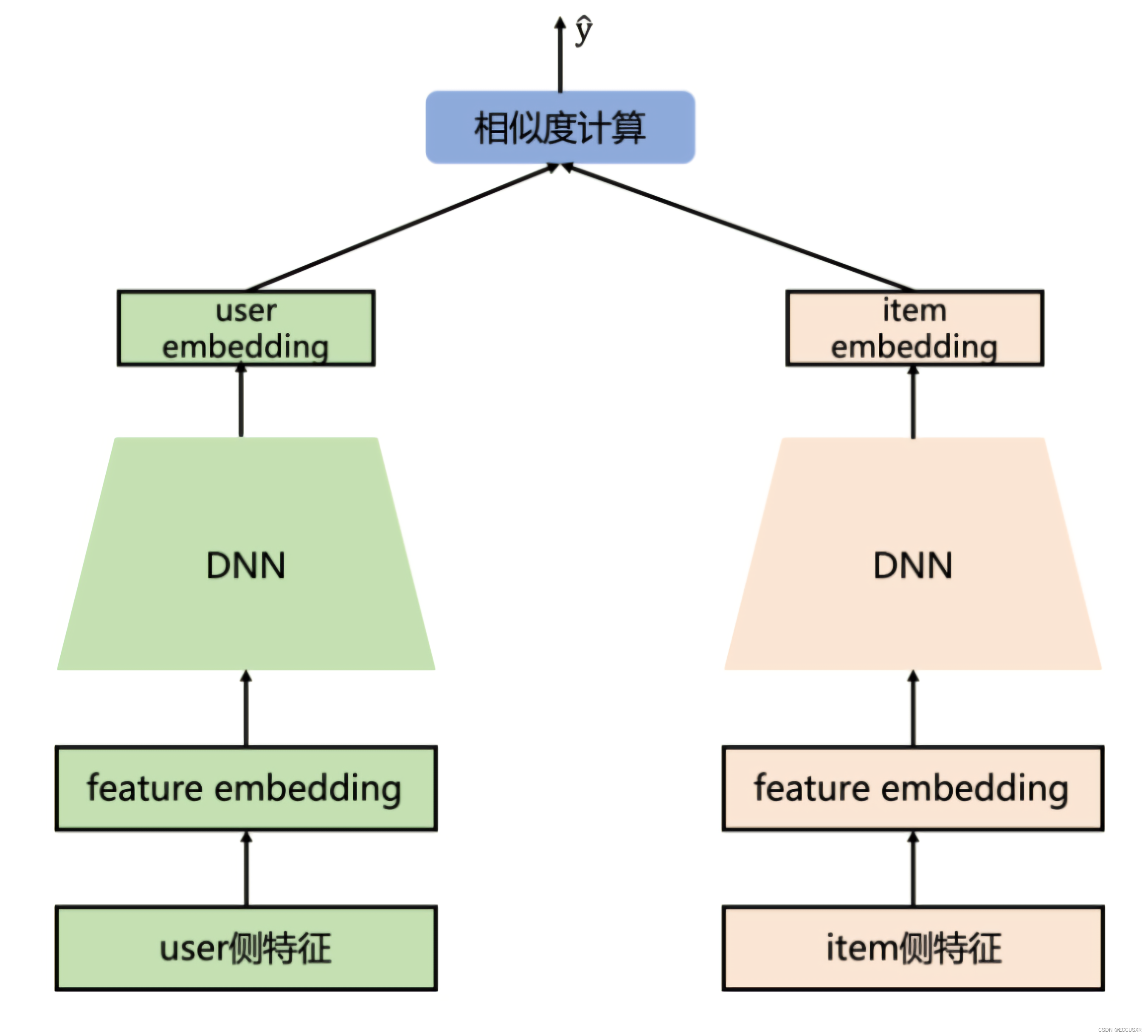
在NLP中负采样就是在不是target中采样。k一般取5-20,不能是均匀采样,均匀采样会拿到很多频率高的词,可以用下面这种方式:
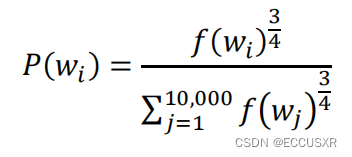
6 多任务概念
首先什么是多任务学习?
在常规分类任务中,通常每个实例都对应一个label。如下图所示。 第 i 个实例仅对应于第二个类。
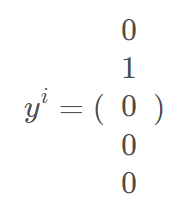
然而,在多分类学习中,一个实例会对应多个label。
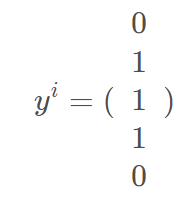
损失函数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JR9CDPYb-1656385819493)(C:\Users\96212\AppData\Roaming\Typora\typora-user-images\image-20220628104734434.png)]
-
m为样本数
-
j为第j个lable
-
多任务学习会共享相同的低阶特征
-
对于多任务学习,我们可以尝试一个足够大的神经网络来处理所有任务
7 MMOE
多门专家混合多任务学习中的任务关系建模
论文 https://dl.acm.org/doi/10.1145/3219819.3220007
MMOE模型的信息:
-
视频简介的youtube地址:https://www.youtube.com/watch?v=Dweg47Tswxw
-
keras框架实现的开源地址:https://github.com/drawbridge/k
- 多任务模型:在不同任务之间学习共性以及差异性,能够提高建模的质量以及效率。
- 多任务模型设计模式:
- Hard Parameter Sharing方法:底层是共享的隐藏层,学习各个任务的共同模式,上层用一些特定的全连接层学习特定任务模式
- Soft Parameter Sharing方法:底层不使用共享的shared bottom,而是有多个tower,给不同的tower分配不同的权重
- 任务序列依赖关系建模:这种适合于不同任务之间有一定的序列依赖关系
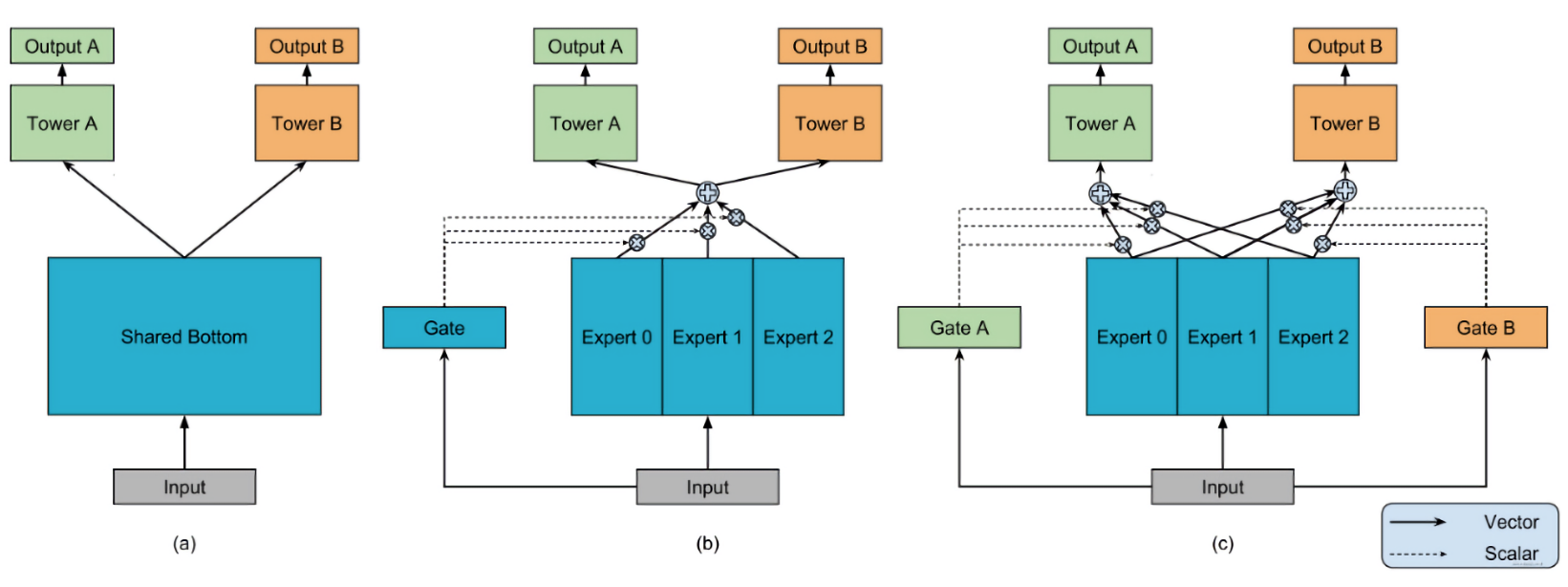
混合专家系统(MoE)是一种神经网络,也属于一种combine的模型。适用于数据集中的数据产生方式不同。不同于一般的神经网络的是它根据数据进行分离训练多个模型,各个模型被称为专家,而门控模块用于选择使用哪个专家,模型的实际输出为各个模型的输出与门控模型的权重组合。各个专家模型可采用不同的函数(各种线性或非线性函数)。混合专家系统就是将多个模型整合到一个单独的任务中。
混合专家系统有两种架构:competitive MoE 和cooperative MoE。competitive MoE中数据的局部区域被强制集中在数据的各离散空间,而cooperative MoE没有进行强制限制。
-
MoE 模型原理:基于多个
Expert汇总输出,通过门控网络机制(注意力网络)得到每个Expert的权重 -
基于OMOE模型,每个
Expert任务都有一个门控网络 -
特性:
- 避免任务冲突,根据不同的门控进行调整,选择出对当前任务有帮助的
Expert组合 - 建立任务之间的关系
- 参数共享灵活
- 训练时模型能够快速收敛
- 避免任务冲突,根据不同的门控进行调整,选择出对当前任务有帮助的