论文直达
原理架构说明
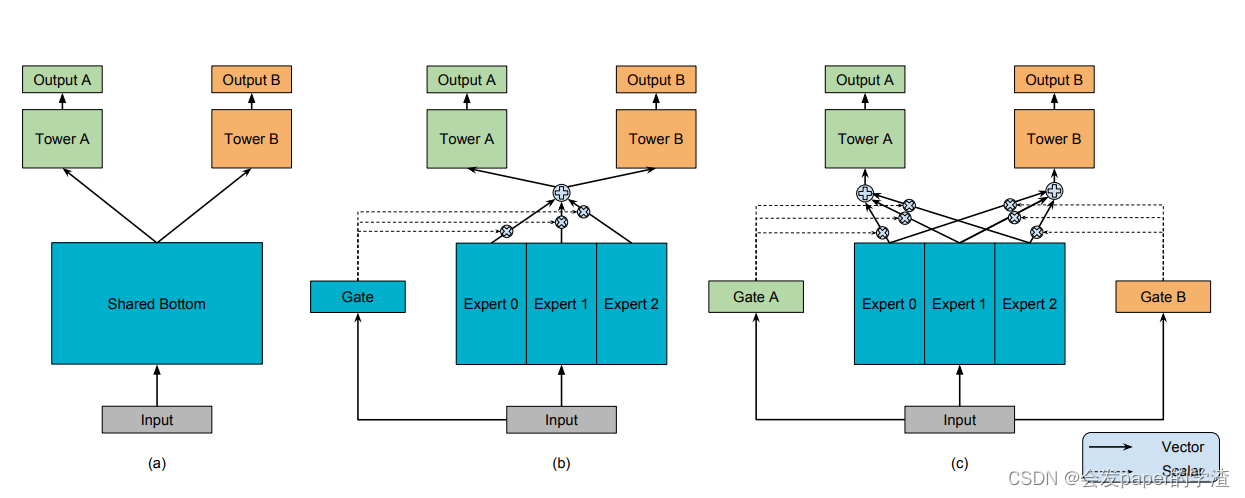
如图是作者给出一个架构图,其中的c就是本文提到的MMOE。
a)为共享参数的模型架构
b)为OMOE模型架构
c)在OMOE的基础上,为每一个任务分贝设置一个gate,对不同的任务使用不同的gate与共享参数进行点乘,作为不同任务的基础输出。
作为2018年的论文,gate更加像是一种attention机制的雏形,论文相对简单。在任务相关度很低的情况下,则OMoE的效果相对于MMoE明显下降,说明MMoE中的multi-gate的结构对于任务差异带来的冲突有一定的缓解作用
代码部分
模型整体
'''
# Time : 2021/12/9 14:47
# Authur : junchaoli
# File : model.py
'''
from layer import mmoe_layer, tower_layer
import tensorflow as tf
from tensorflow.keras import Model
class MMOE(Model):
def __init__(self, mmoe_hidden_units, num_experts, num_tasks,
tower_hidden_units, output_dim, activation='relu',
use_expert_bias=True, use_gate_bias=True,
**kwargs):
super(MMOE, self).__init__()
self.mmoe_layer = mmoe_layer(mmoe_hidden_units,
num_experts,
num_tasks,
use_expert_bias,
use_gate_bias)
# 每个任务对应一个tower_layer
self.tower_layer = [
tower_layer(tower_hidden_units, output_dim, activation)
for _ in range(num_tasks)
]
def call(self, inputs):
mmoe_outputs = self.mmoe_layer(inputs) # list: num_tasks x [None, hidden_units]
outputs = []
for i, layer in enumerate(self.tower_layer):
out = layer(mmoe_outputs[i])
outputs.append(out)
return outputs # list: num_tasks x [None, output_dim]
layer部分
import tensorflow as tf
from tensorflow.keras.layers import Layer
from tensorflow.keras.layers import Dense
import tensorflow.keras.backend as K
class mmoe_layer(Layer):
def __init__(self, hidden_units, num_experts, num_tasks,
use_expert_bias=True, use_gate_bias=True,
**kwargs):
super(mmoe_layer, self).__init__()
self.hidden_units = hidden_units # expert输出维度
self.num_experts = num_experts # expert数量
self.num_tasks = num_tasks # task数量
self.use_expert_bias = use_expert_bias
self.use_gate_bias = use_gate_bias
def build(self, input_shape):
if len(input_shape) != 2:
raise ValueError("The dim of inputs should be 2, not %d" % (len(input_shape)))
# expert 网络, 形状为 [input_shape[-1], hidden_units, num_experts]
# 每个 expert 将输入维度从 input_shape[-1] 映射到 hidden_units
self.expert_matrix = self.add_weight(
name='expert_matrix',
shape=(input_shape[-1], self.hidden_units, self.num_experts),
trainable=True,
initializer=tf.random_normal_initializer(),
regularizer=tf.keras.regularizers.l2(1e-4)
)
# expert网络偏置项, 形状为 [hidden_units, num_experts]
if self.use_expert_bias:
self.expert_bias = self.add_weight(
name='expert_bias',
shape=(self.hidden_units, self.num_experts),
trainable=True,
initializer=tf.random_normal_initializer(),
regularizer=tf.keras.regularizers.l2(1e-4)
)
# gate网络, 每个gate形状为[input_shape[-1], num_experts]
# 总共num_tasks个gate,每个对应一个任务
self.gate_matrix = [self.add_weight(
name='gate_matrix'+str(i),
shape=(input_shape[-1], self.num_experts),
trainable=True,
initializer=tf.random_normal_initializer(),
regularizer=tf.keras.regularizers.l2(1e-4)
) for i in range(self.num_tasks)]
# gate网络偏置项,形状为[num_experts],总共num_tasks个
if self.use_gate_bias:
self.gate_bias = [self.add_weight(
name='gate_bias'+str(i),
shape=(self.num_experts,),
trainable=True,
initializer=tf.random_normal_initializer(),
regularizer=tf.keras.regularizers.l2(1e-4)
) for i in range(self.num_tasks)]
def call(self, inputs, **kwargs):
if K.ndim(inputs) != 2:
raise ValueError("The dim of inputs should be 2, not %d" % (K.ndim(inputs)))
# inputs x expert = [None,input_shape[-1]] x [input_shape[-1],hidden_units,num_experts]
# 得到[None, hidden_units, num_experts]
expert_output = []
for i in range(self.num_experts):
expert_out = tf.matmul(inputs, self.expert_matrix[:, :, i]) # [None, hidden_units]
expert_output.append(expert_out)
expert_output = tf.transpose(tf.convert_to_tensor(expert_output),
[1, 2, 0]) # [None, hidden_units, num_experts]
# 加偏置,形状保持不变
if self.use_expert_bias:
expert_output += self.expert_bias
expert_output = tf.nn.relu(expert_output)
# inputs x gate = [None,input_shape[-1]] x [input_shape[-1],num_experts]
# num_tasks个gate得到输出列表 num_tasks x [None, num_experts]
gate_outputs = []
for i, gate in enumerate(self.gate_matrix):
gate_out = tf.matmul(inputs, gate) # [None, num_experts]
if self.use_gate_bias:
gate_out += self.gate_bias[i]
gate_out = tf.nn.softmax(gate_out)
gate_outputs.append(gate_out) # list: num_tasks x [None, num_experts]
# gate与expert的输出相乘
outputs = []
for gate_out in gate_outputs:
gate_out = tf.expand_dims(gate_out, axis=1) # 维度扩展 [None, 1, num_experts]
gate_out = tf.tile(gate_out, [1, self.hidden_units, 1]) # 维度复制 [None, hidden_units, num_experts]
out = tf.multiply(gate_out, expert_output) # 元素乘 [None, hidden_units, num_experts]
out = tf.reduce_sum(out, axis=-1) # 取平均 [None, hidden_units]
outputs.append(out)
return outputs # list: num_tasks x [None, hidden_units]
class tower_layer(Layer):
def __init__(self, hidden_units, output_dim, activation='relu'):
super(tower_layer, self).__init__()
self.hidden_layer = [Dense(i, activation=activation) for i in hidden_units]
self.output_layer = Dense(output_dim, activation=None)
def call(self, inputs, **kwargs):
if K.ndim(inputs) != 2:
raise ValueError("The dim of inputs should be 2, not %d" % (K.ndim(inputs)))
x = inputs
for layer in self.hidden_layer:
x = layer(x)
output = self.output_layer(x)
return output