原创文章,转载请说明来自《老饼讲解神经网络》:bp.bbbdata.com
关于《老饼讲解神经网络》:
本网结构化讲解神经网络的知识,原理和代码。
重现matlab神经网络工具箱的算法,是学习神经网络的好助手。
目录
本文第一部分先介绍BP神经网络的模型结构和数学表达式,
第二部分介绍用梯度下降法求解BP神经网络的具体实例和代码(不依赖任何第三方包)。
排版凌乱,不再调整,需要的可直接上原网查看
一、BP模型介绍
01.BP的结构与仿生思路
BP的思路是模仿人的大脑工作原理,构造的一个数学模型,
它的仿生结构如下(也称为BP神经网络拓扑图)

结构
它的 结构包含三层,最靠前的是输入层,中间是隐层(可以有多个隐层,每层隐层可以有多个神经元),最后是输出层。
工作流程
(1) 输入层负责接收输入,在输入层接收到输入后,每个输入神经元会把值加权传递到各个隐层神经元,
(2) 各个隐神经元接收到输入神经元传递过来的值后,与自身的基础阈值b汇总求和,经过一个激活函数(通常激活函数是tansig函数),然后加权传给输出层。
(3) 输出神经元把各个隐神经元传过来的值与自身阈值b求和(求和后也可以再经过一层转换),即是输出值。
仿生原理
在眼睛看到符号“5”的后,大脑将判别出它是5。BP正是要模仿这个行为。把这个行为过程简单拆分为:
(1) 眼睛接受了输入
(2) 把输入信号传给其它脑神经元
(3) 脑神经元综合处理后,输出结果为5
我们都知道, 神经元与神经元之间是以神经冲动的模式进行传值,信号到了神经元,都是以电信号的形式存在,
当电信号在神经元积累到超过阈值时,就会触发神经冲动,将电信号传给其它神经元。
根据这一原理,就构造出了以上的神经网络结构。
02. 常用的BP结构
上面是通用结构,隐层个数、激活函数都是未确定的
最常用的,是设一个隐层,
隐层神经元的激活函数设为tansig函数,
输出层的激活函数设为purelin
如此一来,结构就如下图所示:
其中,
tansig函数为S型函数:
purelin 为恒等线性映射函数:
PASS:
1、输出层设为purelin,也即相当于输出层没有激活函数.
2、 隐层激活函数也可以设为logsig :,它和tansig没有太多质的区别。区别在于,logsig的取值范围是【0,1】,而tansig是【-1,1】。
03. BP的数学结构(表达式)
在这里,我们不提供通用的数学结构,
仅以一个简单例子,讲述它的数学结构,这样更为具体和易理解些
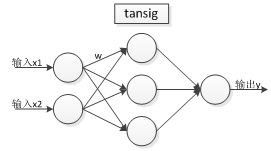
现有一个BP神经网络,它的结构如下:
- 一个输入层,一个隐层,一个输出层, 输入层、隐层、输出层的节点个数分别为 [2 ,3,1]。
- 传递函数设置:隐层( tansig函数)。输出层(purelin函数)。
模型拓扑图如下:
可以根据模型写出数学表达式如下:
PASS: 表达式中参数很多,但实际只有两类参数:权重w和阈值b。
代表这个权值是第2层的第2个节点到第3层的第1个节点的权值。
代表这个阈值是第2层的第1个节点的阈值。
备注:权重矩阵w的下标,一般由后层到前层,这样在矩阵表述时更为简洁

二、梯度下降法求解BP神经网络
01 . 问题
现有如下数据:
y实际是由
生成
现在,我们需要训练一个神经网络,对其进行拟合,最后,我们再与

02. 建模思路
设置神经网络结构
这里我们设为一个隐层,3个隐神经元,隐层激活函数为tansig,
则我们的网络拓扑如下:
对应的模型数学表达式为:

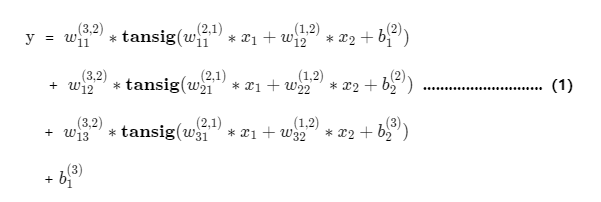
损失函数与梯度
损失函数为:

隐层-->输出层的权重、输出层阈值梯度为:


其中,为隐层的激活值,
为输出层的节点梯度:

隐层-->输出层的权重、隐层的阈值梯度为:


其中,为隐层的节点梯度:

算 法 流 程
先初始化W,b,
(1) 按照梯度公式算出梯度
(2) 将W往负梯度方向调整
不断循环(1)和(2),直到达到终止条件(例如达到最大迭代次数,或误差足够小)
03. 代码实现
close all;clear all;
%-----------数据----------------------
x1 = [-3,-2.7,-2.4,-2.1,-1.8,-1.5,-1.2,-0.9,-0.6,-0.3,0,0.3,0.6,0.9,1.2,1.5,1.8];% x1:x1 = -3:0.3:2;
x2 = [-2,-1.8,-1.6,-1.4,-1.2,-1,-0.8,-0.6,-0.4,-0.2,-2.2204,0.2,0.4,0.6,0.8,1,1.2]; % x2:x2 = -2:0.2:1.2;
X = [x1;x2]; % 将x1,x2作为输入数据
y = [0.6589,0.2206,-0.1635,-0.4712,-0.6858,-0.7975,-0.8040,...
-0.7113,-0.5326,-0.2875 ,0.9860,0.3035,0.5966,0.8553,1.0600,1.1975,1.2618]; % y: y = sin(x1)+0.2*x2.*x2;
%--------参数设置与常量计算-------------
setdemorandstream(88);
hide_num = 3;
lr = 0.05;
[in_num,sample_num] = size(X);
[out_num,~] = size(y);
%--------初始化w,b和预测结果-----------
w_ho = rand(out_num,hide_num); % 隐层到输出层的权重
b_o = rand(out_num,1); % 输出层阈值
w_ih = rand(hide_num,in_num); % 输入层到隐层权重
b_h = rand(hide_num,1); % 隐层阈值
simy = w_ho*tansig(w_ih*X+repmat(b_h,1,size(X,2)))+repmat(b_o,1,size(X,2)); % 预测结果
mse_record = [sum(sum((simy - y ).^2))/(sample_num*out_num)]; % 预测误差记录
% ---------用梯度下降训练------------------
for i = 1:5000
%计算梯度
hide_Ac = tansig(w_ih*X+repmat(b_h,1,sample_num)); % 隐节点激活值
dNo = 2*(simy - y )/(sample_num*out_num); % 输出层节点梯度
dw_ho = dNo*hide_Ac'; % 隐层-输出层权重梯度
db_o = sum(dNo,2); % 输出层阈值梯度
dNh = (w_ho'*dNo).*(1-hide_Ac.^2); % 隐层节点梯度
dw_ih = dNh*X'; % 输入层-隐层权重梯度
db_h = sum(dNh,2); % 隐层阈值梯度
%往负梯度更新w,b
w_ho = w_ho - lr*dw_ho; % 更新隐层-输出层权重
b_o = b_o - lr*db_o; % 更新输出层阈值
w_ih = w_ih - lr*dw_ih; % 更新输入层-隐层权重
b_h = b_h - lr*db_h; % 更新隐层阈值
% 计算网络预测结果与记录误差
simy = w_ho*tansig(w_ih*X+repmat(b_h,1,size(X,2)))+repmat(b_o,1,size(X,2));
mse_record =[mse_record, sum(sum((simy - y ).^2))/(sample_num*out_num)];
end
% -------------绘制训练结果与打印模型参数-----------------------------
h = figure;
subplot(1,2,1)
plot(mse_record)
subplot(1,2,2)
plot(1:sample_num,y);
hold on
plot(1:sample_num,simy,'-r');
set(h,'units','normalized','position',[0.1 0.1 0.8 0.5]);
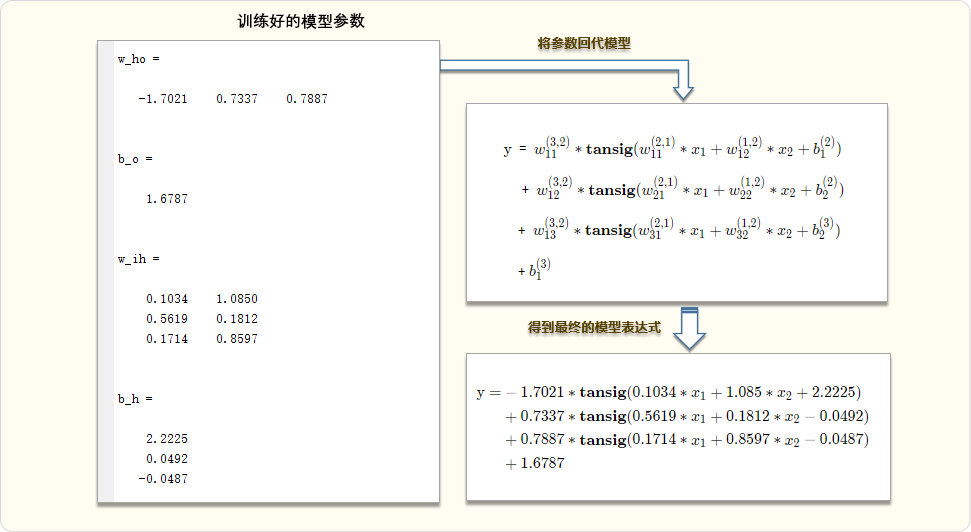
%--模型参数--
w_ho % 隐层到输出层的权重
b_o % 输出层阈值
w_ih % 输入层到隐层权重
b_h % 隐层阈值04. 运行结果

05. 检验模型效果
使用x =[0.5,0.5]进行测试,
模型预测结果

将 x =[0.5,0.5] 代入以上网络模型表达式,得到 0.6241
真实结果
将 x =[0.5,0.5] 代入真实的关系中得到0.5294 .
预测结果分析
网络的预测值0.6241与真实值0.5294 误差0.0946。
这个误差不算太大,但也不算小。
整体来说,模型训练具有一定的效果,说明算法是可行的。
PASS:为什么训练数据这么好,而预测值仍然有这么大的差距?读者们能想明白吗?能改善吗?要怎么才能改善?
特别声明:以上梯度下降法整个求解过程的实现,是非常粗糙的,仅是作为入门参考。
相关文章