from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
import matplotlib as mpl
import numpy as np
import argparse
# 计算sigmoid函数
def sigmoid_activation(x):
return 1.0 / (1 + np.exp(-x))
# 根据激活函数得到的预测值然后进行阈值化到1和0
def predict(X, W):
preds = sigmoid_activation(X.dot(W))
preds[preds <= 0.5] = 0
preds[preds > 0] = 1
return preds
def next_batch(X, y, batchSize):
for i in np.arange(0, X.shape[0], batchSize):
yield (X[i:i+batchSize], y[i:i+batchSize])
def run_basicSGD():
# 命令行参数解析
ap = argparse.ArgumentParser()
ap.add_argument("-e", "--epochs", type=int, default=100, help="# of epochs")
ap.add_argument("-a", "--alpha", type=float, default=0.01, help="learning rate")
args = vars(ap.parse_args())
# 生成数据
(X, y) = make_blobs(n_samples=10000, n_features=2, centers=2, cluster_std=1.5, random_state=1)
y = y.reshape((y.shape[0], 1))
# bias trick将bias添加到W矩阵的另一列,这样整合W和b到一个矩阵进行参数学习
X = np.c_[X, np.ones((X.shape[0]))]
# 分割训练和测试数据
(trainX, testX, trainY, testY) = train_test_split(X, y, test_size=0.5, random_state=42)
print("[INFO] training...")
W = np.random.randn(X.shape[1], 1)
print("initialize W = \n", W)
losses = []
# 轮次迭代训练
for epoch in np.arange(0, args["epochs"]):
preds = sigmoid_activation(trainX.dot(W))
# 计算平方误差
error = preds - trainY
loss = np.sum(error ** 2)
losses.append(loss)
gradient = trainX.T.dot(error)
# 更新W的值
W += -args["alpha"] * gradient
if epoch == 0 or (epoch + 1) % 5 == 0:
print("[INFO] epoch={}, loss={:.7f}".format(int(epoch + 1), loss))
print("[INFO] evaluating...")
# 生成报告
preds = predict(testX, W)
print(classification_report(testY, preds))
# 可视化训练过程
plt.style.use("ggplot")
plt.figure()
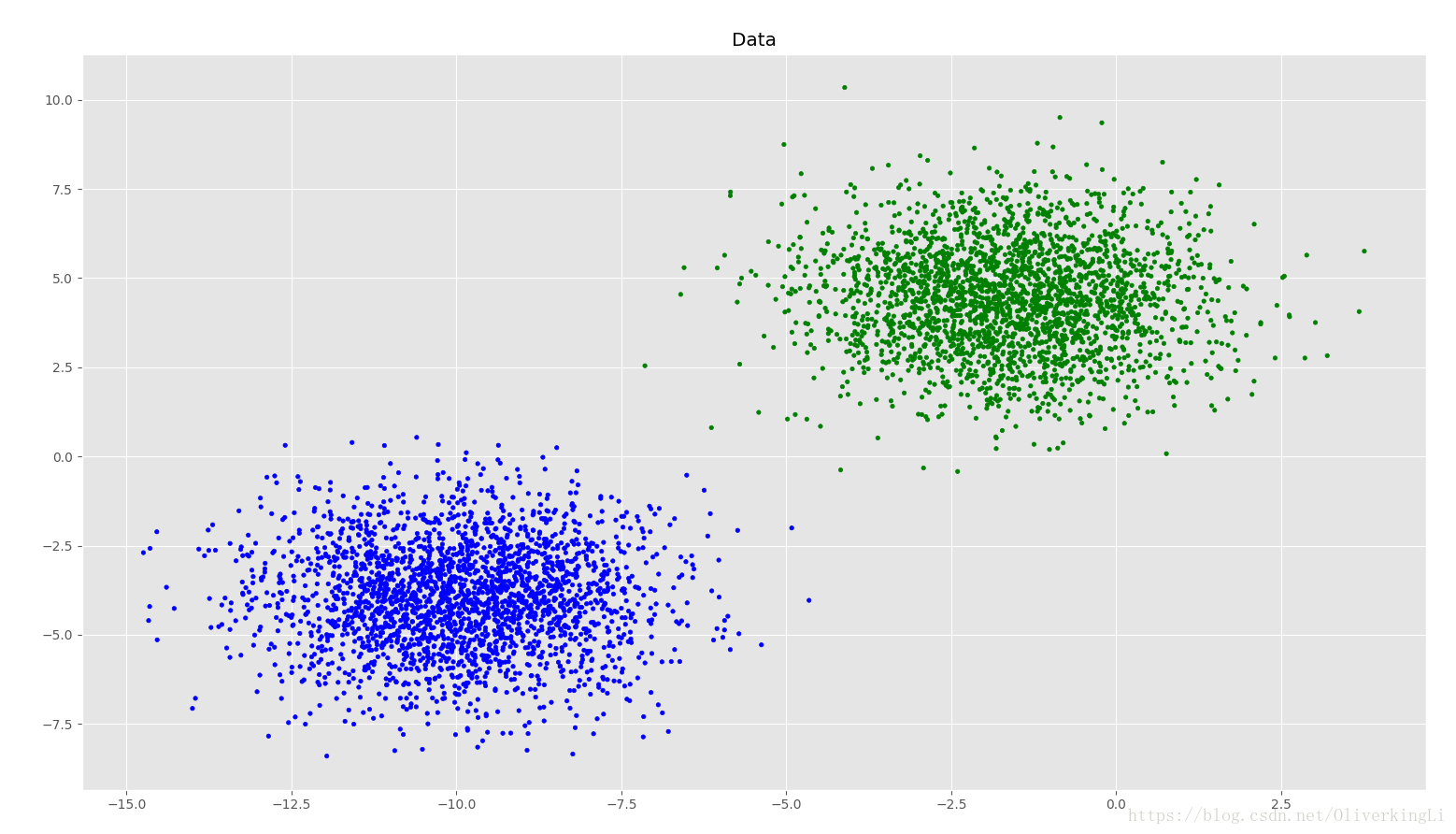
plt.title("Data")
cm_dark = mpl.colors.ListedColormap(['g', 'b'])
plt.scatter(testX[:, 0], testX[:, 1], marker="o", c=testY.ravel(), cmap=cm_dark, s=10)
# print(testY)
plt.style.use("ggplot")
plt.figure()
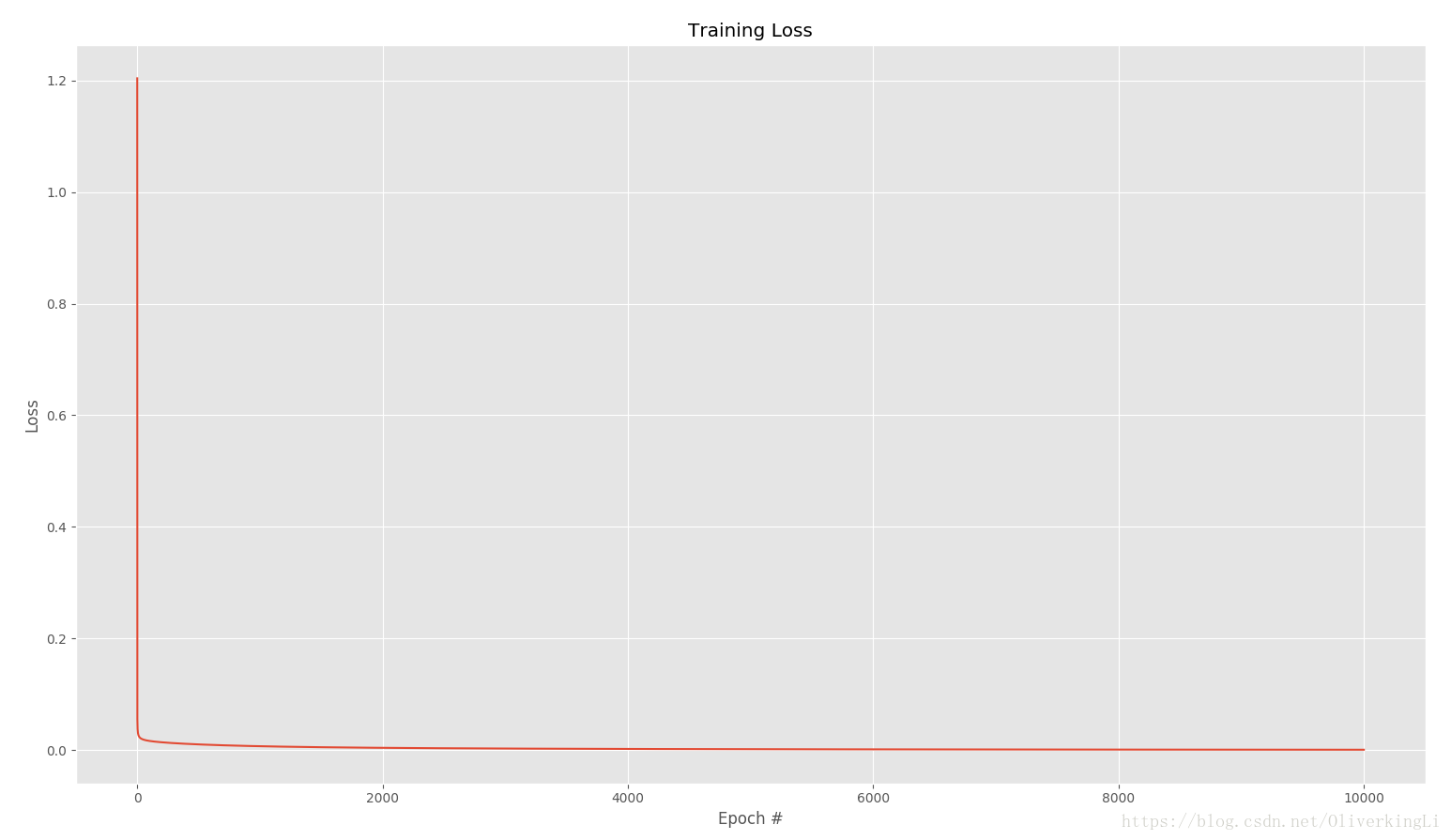
plt.plot(np.arange(0, args["epochs"]), losses)
plt.title("Training Loss")
plt.xlabel("Epoch #")
plt.ylabel("Loss")
plt.show()
print("W\n", W)
def run_minibatchSGD():
# 命令行参数解析
ap = argparse.ArgumentParser()
ap.add_argument("-e", "--epochs", type=int, default=100, help="# of epochs")
ap.add_argument("-a", "--alpha", type=float, default=0.01, help="learning rate")
ap.add_argument("-b", "--batch-size", type=int, default=32, help="size of the SGD mini-batches")
args = vars(ap.parse_args())
# 生成数据
(X, y) = make_blobs(n_samples=10000, n_features=2, centers=2, cluster_std=1.5, random_state=1)
y = y.reshape((y.shape[0], 1))
# bias trick将bias添加到W矩阵的另一列,这样整合W和b到一个矩阵进行参数学习
X = np.c_[X, np.ones((X.shape[0]))]
# 分割训练和测试数据
(trainX, testX, trainY, testY) = train_test_split(X, y, test_size=0.5, random_state=42)
print("[INFO] training...")
W = np.random.randn(X.shape[1], 1)
losses = []
# 轮次迭代训练
for epoch in np.arange(0, args["epochs"]):
epochLoss = []
for (batchX, batchY) in next_batch(X, y, args["batch_size"]):
preds = sigmoid_activation(batchX.dot(W))
error = preds - batchY
epochLoss.append(np.sum(error ** 2))
gradient = batchX.T.dot(error)
W += -args["alpha"] * gradient
loss = np.average(epochLoss)
losses.append(loss)
if epoch == 0 or (epoch+1) % 5 == 0:
print("[INFO] epoch={}, loss={:.7f}".format(int(epoch + 1), loss))
print("[INFO] evaluting...")
preds = predict(testX, W)
print(classification_report(testY, preds))
# 可视化训练过程
plt.style.use("ggplot")
plt.figure()
plt.title("Data")
cm_dark = mpl.colors.ListedColormap(['g', 'b'])
plt.scatter(testX[:, 0], testX[:, 1], marker="o", c=testY.ravel(), cmap=cm_dark, s=10)
# print(testY)
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, args["epochs"]), losses)
plt.title("Training Loss")
plt.xlabel("Epoch #")
plt.ylabel("Loss")
plt.show()
print("W\n", W)
if __name__ == '__main__':
run_basicSGD()
# run_minibatchSGD()
标准SGD:

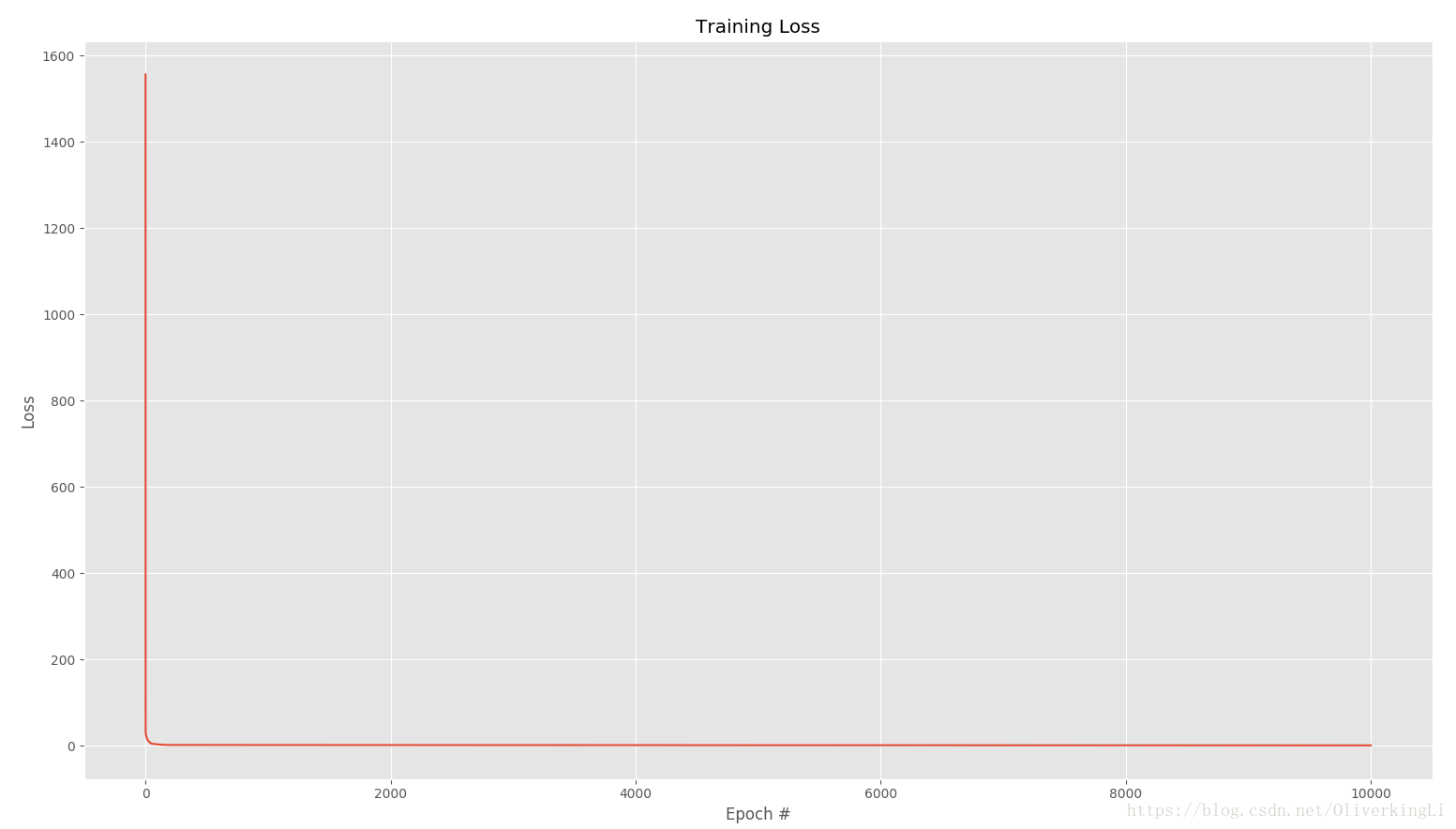
mini-batch SGD: