Nvidia Maxine 精讲(一)AR-SDK安装使用——BodyTrack功能演示
Nvidia Maxine 精讲
动机-2022/10/10 看到这个SDK20天前更新了
这是我上半年尝试了一下英伟达的几个SDK以及应用,今天补更给大家,当时看的是Nvidia何工的csdn说明,Maxine系列的SDK ,这里分三个系列的SDK(NVIDIA Video Effects SDK\NVIDIA AUDIO Effects SDK\Augment Reality SDK),这些SDK提供了高性能的音视频AI交互式服务(视频会议、AI视频分析等业务) 。因为上手简单,故借此来分享下maxine这个SDK的基础使用,后续omniverse(这个比较复杂的应用)也会慢慢分享,我的理解是这套SDK的意义对于工程或者有直接应用需求的人确实很有帮助,但正是由于它过于简单且高度封装,没有算法源码训练部分不利于研究人员,所以有利就有弊,想要两全其美,对于我个人来说这个可能是一套开发方案:需要对这个SDK进行二次开发,将api标准熟悉后,使用这个框架去自己构建新的模型转成trt完成解析和部署,这样其实难度和工作量倍增,所以还是看你要干什么。。不多废话了,开始!

二、软硬件环境要求详细说明
1.安装简介
点击nvidia的maxine下载地址:https://developer.nvidia.com/maxine#ar-sdk
我之前用的是0.7版本,现在已经0.8+了
在下图中点击NVIDIA MAXINE系列中的Augmented Reality SDK, 这篇文章只针对这个SDK进行说明,我们可以在旁边的Key features观看这个SDK实现的算法功能,以及更新的消息。
我们可以从图中看到这个SDK提供了人脸检测追踪,人脸关键点检测和跟踪,人脸的mesh,人体的关键点检测,其中目前这个SDK看来是经历了更新,新增加了视线跟踪,并且关键点支持了3D的landmarks预测,而表情其实貌似加入了blendshape的计算,这里说下之前版本的表情是通过mesh使用3DMM拟合预测了一些表情的demo,这个功能后续我下好新版本的SDK顺便看下。 另外现在应该是支持linux了,大概半年前还是只支持Windows,这里我建议选择 windows,后面会给出原因
(需要在英伟达注册账户才可以下载,填完资料后进入到NGC后就可以点击下载)
具体使用我们可以点击使用文档,这里以windows的sdk为例子,AR SDK的linux版本需要官方填写资料后批准才行,因为早期这三个SDK的系列都是为只支持windows的sdk,其余两个video\audio的sdk是双平台都支持的,今天我们主要是讲ar 这个SDK的使用,故个人建议有条件优先使用windows系统,具体想更深入了解的,使用说明可以点击下方官方文档以及刚才下载的sdk提供的手册进行使用.
https://docs.nvidia.com/deeplearning/maxine/ar-sdk-system-guide/index.html
2.环境具体说明
本机windows10(64bit)配置:(win10以上,ubuntu18以上,Centos7以上即可)
- 需要你有Nvidia的显卡,图灵架构、安培、最新的Ada Lovelace架构,话说40系显卡估计大手笔公司都会冲吧?(所以这里,你要不是RTX20 \30系列\40系或者中高端计算卡 ,那么这个SDK没法用了,以架构区分即可 比如10系的帕斯卡架构就没法用 )
- CMakegui 3.24 (3.12以上即可)
- vs2022 (2015以上即可)
- Nvidia图形驱动 516 (511.65 以上即可)
- cuda 11.7 (cuda 11.0+)
3.编译运行
3.1 版本对比说明 ——助你更好理解
之前我用过0.7的版本 改动不算很大,除了之前添加的eye-contact和表情拟合,其实表情拟合这部分做了一个扩展优化,这部分对比我放在后面的文章讲现在主要说下一些文件目录结构:

这里除了新版本添加的2个demo,0.7版本只有Face和Body两个,然后Face部分的Demo被英伟达在官方版本进行了优化,之前需要做3DMM的拟合(使用工具和下载模型最后去拟合mesh效果,新版本进行了删减和优化 不需要额外去下载模型,你可以在bin\models\下找到所有的引擎模型),这部分是新旧版本的三方库对比,新版本可能用到了更多GUI的功能,额外引进了JSON、OPENGL的库,如图:

其余的就是各个应用源码的微改动,这里做个叙述吧,算是个插曲。
3.2 编译sdk
我们下载后的sdk是zip压缩包,需要连续解压到你指定的目录路径下(经过两次解压,第二次解压要指定目录,不要解压当前)。新下载的SDK解压后SDK目录如下图:

- 打开CMAKE-GUI,将Sdk的根目录路径输入到gui的第一行 source code下
- 新建build文件夹,然后输入到 where to build the binaries 的选项中
- 点击confugure,然后点击Generate完成。

3.3 BodyTrack 使用详细解说
打开根目录下的 samples\,我们可以看到几个应用的demo,我们可以点击第一个BodyTrack文件夹,我们找到run_local.bat命令的两个脚本,用哪个都可以的:这个是打开OPENCV的摄像头,只要你链接了摄像头就可以;下面那个带offline的是离线是给视频文件的形式,本质没区别就是参数不同而已,不信 我们打开看下就行:
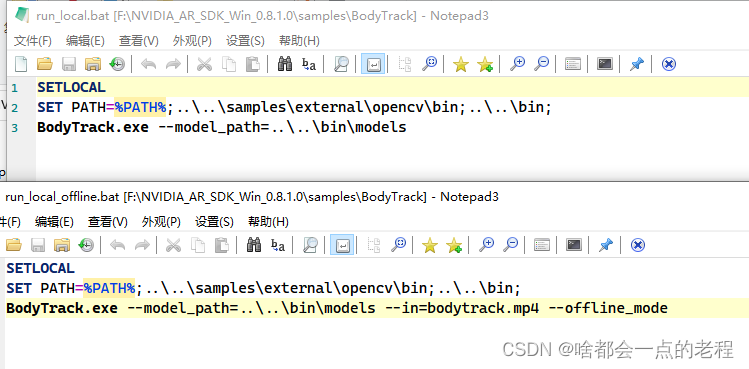
只是调用windows编译好的程序命令而已,这里示范下offline 文件形式好了,如果你没有摄像头,可以网上下载虚拟摄像头也可以,这里我就用下offline的文件形式就行,双击即可,然后推理的是脚本中的“bodytrack.mp4”,你也可以修改这个换成你想检测的视频文件。
这里我使用离线模型就会是直接输出成MP4了,如下图
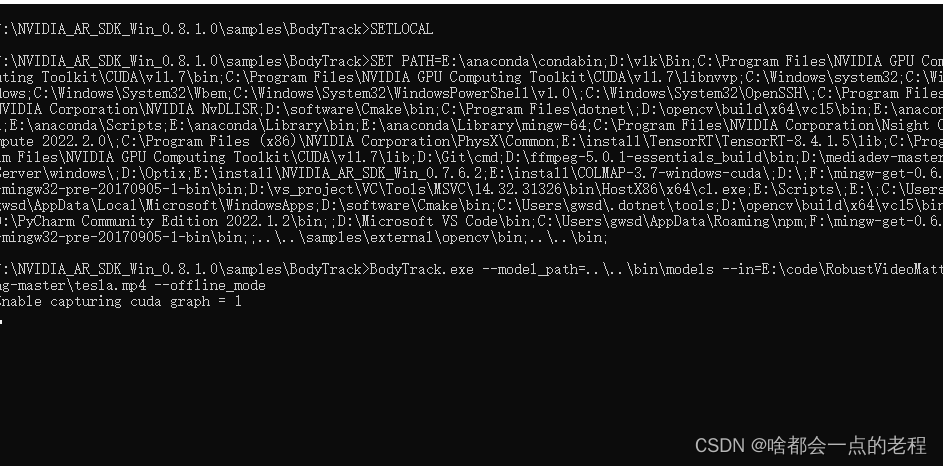
等待上面的窗口关闭就是OFFLINE推理结束,生成的MP4会放在你输入文件的路径内,所以最好先把MP4放在当前程序的目录下命名为xxxx_pose.mp4,便于验证,看下效果。

我们可以看到检测结果可视化,但是这里我们发现只能检测一个人,一般这里是内部代码控制的逻辑,且也可以看出大概率这个关键点检测算法是top-down的类型,性能就是实时毕竟N家自制。
细心的朋友可以发现现在新版本支持了3D,这个需要我们在代码里看一下各种参数项,我们打开F:\NVIDIA_AR_SDK_Win_0.8.1.0\samples\BodyTrack\BodyTrack.cpp,可以看到选择的参数功能,如果你想了解的非常深入,这里我简要汇总下!可以直接看官方的文档:nvidia system guide
程序命令行参数选项

程序键盘控制参数选项

4 .代码部分
回到SDK根目录的build文件下(F:\NVIDIA_AR_SDK_Win_0.8.1.0\build\ALL_BUILD.vcxproj),使用VS2022打开解决方案ALL_BUILD.vcxproj,可以看到这个SDK下面的4个功能:BodyTrack\eXPRESS\facetrack\GazeRedirect,今天我们主要说整个sdk的基本使用和BodyTrack这个功能
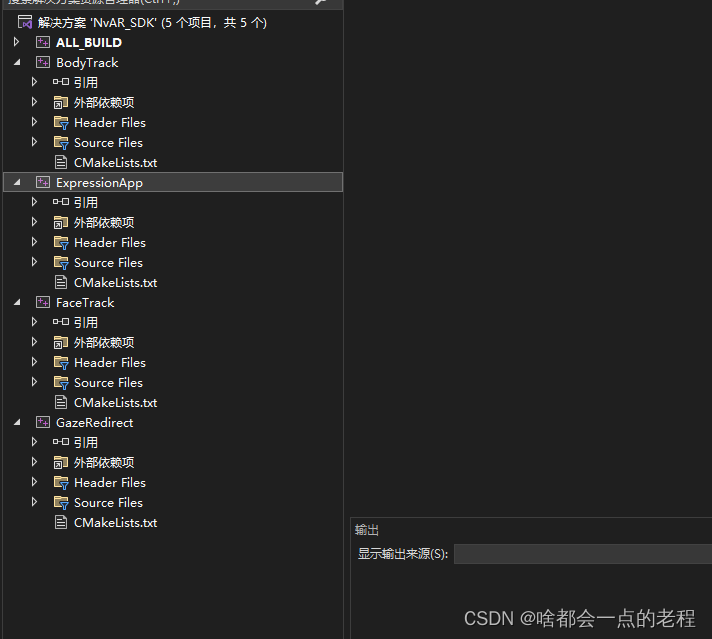
我们可以修改下BodyTranck代码进行二次开发, 把代码修改后可以点击重新生成解决方案即可,此时注意我们生成的新的EXE执行文件是在build\Release\下的exe,然后你可以在这个路径下建一个bat文件去运行,具体就写之前的内容调用即可:
实时在线使用命令
``
SETLOCAL
SET PATH=%PATH%;..\..\samples\external\opencv\bin;..\..\bin;
BodyTrack.exe --model_path=..\..\bin\models // 后面的参数可以根据代码里的参数说明进行自由调整 ,如果不给文件,这个默认是打开摄像头了
离线文件使用:
```cpp
SETLOCAL
SET PATH=%PATH%;..\..\samples\external\opencv\bin;..\..\bin;
BodyTrack.exe --model_path=..\..\bin\models --in=《换成你的文件》 --offline_mode //后面参数自行看代码选
我们直接看Bodytrack的主函数逻辑,这里简单过一下:
int main(int argc, char **argv) {
// Parse the arguments
if (0 != ParseMyArgs(argc, argv)) return -100;
DoApp app;
DoApp::Err doErr = DoApp::Err::errNone;
app.body_ar_engine.setAppMode(BodyEngine::mode(FLAG_appMode)); // --app_mode[=(0 | 1)] App mode. 0: Body detection, 1 : Keypoint detection "
app.body_ar_engine.setMode(FLAG_mode); //选择模式 参考上面参数列表
if (FLAG_verbose) printf("Enable temporal optimizations in detecting body and keypoints = %d\n", FLAG_temporal);
app.body_ar_engine.setBodyStabilization(FLAG_temporal);
if (FLAG_useCudaGraph) printf("Enable capturing cuda graph = %d\n", FLAG_useCudaGraph);
app.body_ar_engine.useCudaGraph(FLAG_useCudaGraph);
#if NV_MULTI_OBJECT_TRACKER
app.body_ar_engine.enablePeopleTracking(FLAG_enablePeopleTracking, FLAG_shadowTrackingAge, FLAG_probationAge, FLAG_maxTargetsTracked);
#endif
doErr = DoApp::errBodyModelInit;
if (FLAG_modelPath.empty()) {
printf("WARNING: Model path not specified. Please set --model_path=/path/to/trt/and/body/models, "
"SDK will attempt to load the models from NVAR_MODEL_DIR environment variable, "
"please restart your application after the SDK Installation. \n");
}
if (!FLAG_bodyModel.empty())
app.body_ar_engine.setBodyModel(FLAG_bodyModel.c_str());
if (FLAG_offlineMode) {
//离线文件模型
if (FLAG_inFile.empty()) {
doErr = DoApp::errMissing;
printf("ERROR: %s, please specify input file using --in_file or --in \n", app.errorStringFromCode(doErr));
goto bail;
}
doErr = app.initOfflineMode(FLAG_inFile.c_str(), FLAG_outFile.c_str());
} else {
doErr = app.initCamera(FLAG_camRes.c_str()); //实时相机模式
}
BAIL_IF_ERR(doErr);
doErr = app.initBodyEngine(FLAG_modelPath.c_str()); //读取TRT引擎 加载模型
std::cout << doErr << std::endl;
BAIL_IF_ERR(doErr);
//前面都是写参数和模型建立
//run 是opecv解码然后推理再show的核心逻辑 里面的函数每一步都做了高度封装
doErr = app.run();
BAIL_IF_ERR(doErr);
bail:
if(doErr)
printf("ERROR: %s\n", app.errorStringFromCode(doErr));
app.stop();
return (int)doErr;
}
补充内容
可能还是有些细节没有补充到,后面会在这部分里加,感谢阅读~
模型算法解密(本人猜测版本:非官方介绍)
由于BodyTrack这个功能 Nvidia并不会给出算法模型,恰巧我去年做deepstream时候发现英伟达的LAB上开源过一个部署方案(当然也没有算法模型代码,你如果自己训练的话,需要在官网提供的TAO Tooklit 的工具包在线训练,不过这种人脸检测器类型的倒是也没关系。不过我部署后发现和现在这个maxine的算法输出等很相似,然后我追溯到了之前这个模型:BodyPose3Dnet这是早期英伟达训练的一个3D关键点实时检测的模型 恰巧TOP-DOWN算法,那么我好奇心就来了,找到了如下资料和比对信息 )
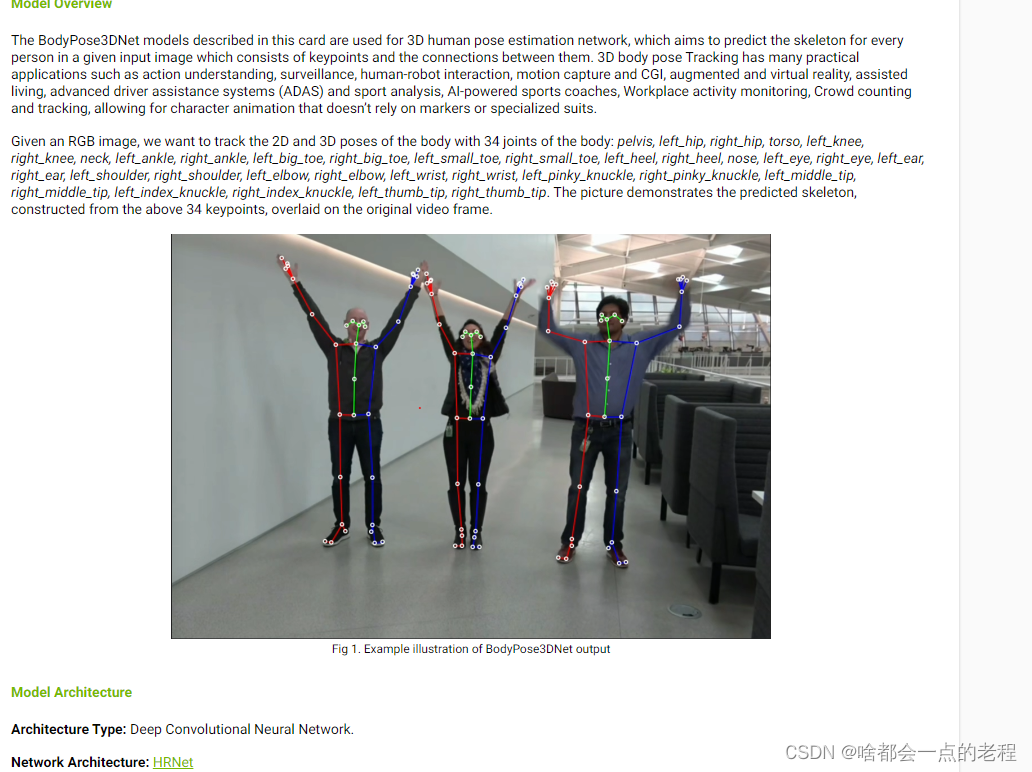
这是NGC官网中给出的资料,也是当时deepstream使用pose的一些链接才查到的,后面2021年的时候英伟达把该方法发表论文为:
KAMA:3D Keypoint Aware Body Mesh Articulation,据我了解这篇论文是参考Nvidia自家出的CVPR的弱监督通过多视角2D图像 学习的3D人体关键点检测以及HRnet的骨干结合。这里说一下这个论文的贡献:
无需3D的标注,只需要多视角相机的参数,提出了2个LOSS,一个是多时间图像预测的3D位姿可以通过相机外参去比对在同一坐标系下,理论应当是一致的;
另一个LOSS:预测的3D位姿重投影回2D作L2范式的思路。 其次,HRnet的第一个版本就是TOP-down方法。
- 算法都是top-down,别被这个图片蒙蔽,这里下面写的很清楚,这只能检测一个人,应该是做了多次人体检测后分别进行的landmarks检测。
??小疑问:这里有个冲突就是英伟达这个KAMA论文中:声称的是26个点,但是实际应用中不管是maxine还是Ds中提供的都是34个人体关键点。

2. 再让我们看关键点的定义,不论是deepstream中内置的 还是maxine内置的都是一套关键点定义,34个名称一模一样,不过 这仍旧不能证明是一样的算法。
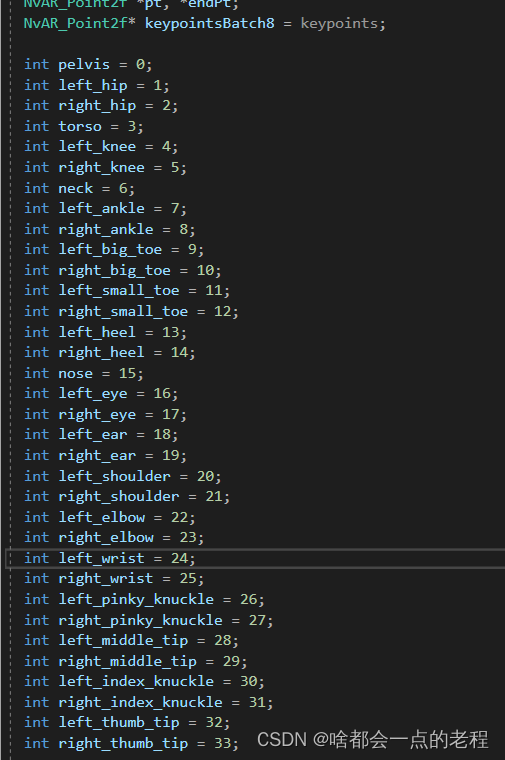
我的个人结论:就是可能使用了类似的思路去构造的模型,不过并不是完全一样的,比如把输入的训练分辨率了一些微改动把,仅个人猜测。。
预告
介绍了基本的使用和关键点检测的功能和代码使用,再细节就是bodytrack.cpp里的各个参数功能,下篇我们讲功能比较多的FaceTrack和Mesh!