python与pytorch中需要注意的点
python对象的复制
python中有一个专门用于复制的包copy, 这个包的出现其实就暗示了我们平时使用等式来复制对象有可能是不对的,且根据python中可变数据类型与不可变数据类型的差异,推知不同的数据类型复制方式不同。
python可变数据类型有list, dict, set, 而不可变数据类型有int, float,str,tuple。对于可变数据类型来说,直接使用等号就是建立了一个引用,相当于浅复制,如果要实现深复制则需要使用copy包中的deepcopy方法
假如python对象中既含有可变数据类型,又包含不可变数据类型,那么不同的复制方法会有不同的区别
import copy
from copy import deepcopy
class Model:
def __init__(self) -> None:
self.params = {
'a': 1, 'b': 2}
self.len = 3
self.names = ['conv', 'norm', 'act']
model = Model()
model_eq = model # 赋值
model_copy = copy.copy(model) # copy复制
model_deepcopy = deepcopy(model) # deepcopy复制
print(model.names)
model.names[2] = 'relu'
print(model_eq.names) # 可以看到赋值为浅复制
print(model_copy.names) # 普通copy为浅复制
print(model_deepcopy.names)
print('-'*50)
print(model.len)
model.len = 5
print(model_eq.len) # 可以看到赋值为直接引用,但原对象属性值变化时,不可变对象也会随之改变
print(model_copy.len) # 普通copy为浅复制,不可变对象不会改变
print(model_deepcopy.len)
运行结果如下
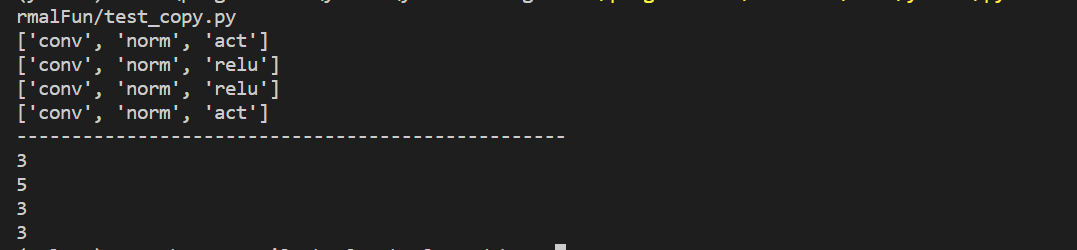
可以看到copy函数对于可变数据类型与不可变数据类型会有不同的操作结果
pytorch结果复现
一般pytorch中模型的参数都是通过随机数取的,为了能复现以前的训练结果,需要固定随机数种子,以便每次训练时,参数初始化都取到一样的值,那么如何固定种子呢,那就需要下面的代码
def init_seeds(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
此外经作者实验发现,仅有上面部分是不够的,在训练时梯度反向传播时需要采用使用torch.use_deterministic_algorithm(True),保证使用确定性的算法。这一行代码需要添加的位置如下
# Backward
torch.use_deterministic_algorithms(True)
scaler.scale(loss).backward()
pytorch断点续训
设想一下如果模型训练时机器突然因为某些原因关机了,那么下次训练时是不是必须从头开始,重新训练呢?答案是否定的,对于一个结构已知的模型来说,参数确定了,那这个模型也就确定了,从这个角度出发,我们只需要保存下模型的参数,就可以供下次训练时使用。因为模型参数的更新需要用optimizer,在保存模型参数的时候同时也应当把优化器的参数保存下来,具体操作的关键代码如下。
# 保存断点,使用torch.save()保存为.pt文件
ckpt = {
'epoch': epoch,
'model': deepcopy(model).half(),
'optimizer': optimizer.state_dict(),
}
torch.save(ckpt, 'last.pt')
# 加载模型参数和优化器参数
model.load_state_dict(ckpt['model'].float().state_dict(), strict=False) # load
optimizer.load_state_dict(ckpt['optimizer'])
其实到有了这些也不一定能保证续训结果能完全复现,即epoch0-1的结果与epoch0-中断-续训-1的结果不一样。什么原因呢,算法中使用了scheduler调节学习率,但是续训后没有恢复到中断前的状态,有些参数,如scheduler.last_epoch就显然不一样,因此断点续训的代码应如下
# 保存断点,使用torch.save()保存为.pt文件
ckpt = {
'epoch': epoch,
'model': deepcopy(model).half(),
'optimizer': optimizer.state_dict(),
'lr_scheduler': scheduler.state_dict(),
}
torch.save(ckpt, 'last.pt')
# 加载模型参数和优化器参数
model.load_state_dict(ckpt['model'].float().state_dict(), strict=False) # load
optimizer.load_state_dict(ckpt['optimizer'])
scheduler.load_state_dict(ckpt['lr_scheduler'])
令人遗憾的是,即使这样,也不能使得断点续训的数据与直接训练一模一样,因为加载数据集时采用了随机数,断点续训后,加载器又会从头开始加载数据,而不是从中断前一轮开始加载。其实此时我们已经知道,这里无法复现的原因是random模块的状态没有与上一轮相同,而是直接重新开始了。
举个例子:
# 直接训练过程
第一步:设置random模块种子为0(可以是任意一个)
第二步:开始训练且第一轮随机数为4, 第二轮随机数为6, 第三轮随机数为1
# 断点训练过程
第一步:设置random模块种子为0(与直接训练过程设置的种子保持一致)
第二步:开始训练且第一轮随机数为4,完成第一轮,且在第二轮训练过程中中断
第三步:中断续训,此时重新设置random模块种子为0
第四步:开始第二轮训练,但是此时随机数取值是4而不是直接训练过程中第二轮的6
因此,在训练时如果使用了random模块,则需要保存random的状态才能真正复现整个算法。下面是保存和加载随机状态的代码
def save_random_state(generator):
random_state = random.getstate()
np_state = np.random.get_state()
torch_state = torch.get_rng_state()
cuda_state = torch.cuda.get_rng_state()
torch_gene = generator.get_state()
return [random_state, np_state, torch_state, cuda_state, torch_gene]
def load_random_state(states):
random.setstate(states[0])
np.random.set_state(states[1])
torch.set_rng_state(states[2])
torch.cuda.set_rng_state(states[3])
return torch.Generator().set_state(states[4])
torch.Generator()的状态需要另外读取载入,因此作为了一个输入,最后来看最终的代码
# 保存相关参数
ckpt = {
'epoch': epoch,
'model': deepcopy(model).half(),
'optimizer': optimizer.state_dict(),
'lr_scheduler': scheduler.state_dict(),
'random_states': save_random_state(generator),
}
# 加载相关参数
start_epoch = ckpt['epoch'] + 1
optimizer.load_state_dict(ckpt['optimizer'])
scheduler.load_state_dict(ckpt['lr_scheduler'])
generator = load_random_state(ckpt['random_states'])