以下文章来源于程序员小富 ,作者程序员内点事
一、Sharding-JDBC 简介
Sharding-JDBC 最早是当当网内部使用的一款分库分表框架,到2017年的时候才开始对外开源,这几年在大量社区贡献者的不断迭代下,功能也逐渐完善,现已更名为 ShardingSphere,2020年4⽉16⽇正式成为 Apache 软件基⾦会的顶级项⽬。随着版本的不断更迭 ShardingSphere 的核心功能也变得多元化起来。从最开始 Sharding-JDBC 1.0 版本只有数据分片,到 Sharding-JDBC 2.0 版本开始支持数据库治理(注册中心、配置中心等等),再到 Sharding-JDBC 3.0版本又加分布式事务 (支持 Atomikos、Narayana、Bitronix、Seata),如今已经迭代到了 Sharding-JDBC 4.0 版本。

现在的 ShardingSphere 不单单是指某个框架而是一个生态圈,这个生态圈 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar 这三款开源的分布式数据库中间件解决方案所构成。ShardingSphere 的前身就是 Sharding-JDBC,所以它是整个框架中最为经典、成熟的组件,我们先从 Sharding-JDBC 框架入手学习分库分表。
二、核心概念
在开始 Sharding-JDBC分库分表具体实战之前,我们有必要先了解分库分表的一些核心概念。
分片
一般我们在提到分库分表的时候,大多是以水平切分模式(水平分库、分表)为基础来说的,数据分片将原本一张数据量较大的表 t_order 拆分生成数个表结构完全一致的小数据量表 t_order_0、t_order_1、···、t_order_n,每张表只存储原大表中的一部分数据,当执行一条SQL时会通过 分库策略、分片策略 将数据分散到不同的数据库、表内。

数据节点
数据节点是分库分表中一个不可再分的最小数据单元(表),它由数据源名称和数据表组成,例如上图中 order_db_1.t_order_0、order_db_2.t_order_1 就表示一个数据节点。
逻辑表
逻辑表是指一组具有相同逻辑和数据结构表的总称。比如我们将订单表t_order 拆分成 t_order_0 ··· t_order_9 等 10张表。此时我们会发现分库分表以后数据库中已不在有 t_order 这张表,取而代之的是 t_order_n,但我们在代码中写 SQL 依然按 t_order 来写。此时 t_order 就是这些拆分表的逻辑表。
真实表
真实表也就是上边提到的 t_order_n 数据库中真实存在的物理表。
分片键
用于分片的数据库字段。我们将 t_order 表分片以后,当执行一条SQL时,通过对字段 order_id 取模的方式来决定,这条数据该在哪个数据库中的哪个表中执行,此时 order_id 字段就是 t_order 表的分片健。
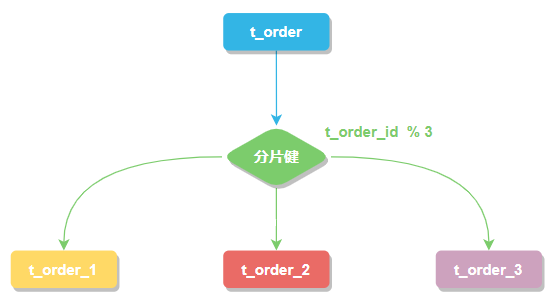
这样以来同一个订单的相关数据就会存在同一个数据库表中,大幅提升数据检索的性能,不仅如此 sharding-jdbc 还支持根据多个字段作为分片健进行分片。
分片算法
上边我们提到可以用分片健取模的规则分片,但这只是比较简单的一种,在实际开发中我们还希望用 >=、<=、>、<、BETWEEN 和 IN 等条件作为分片规则,自定义分片逻辑,这时就需要用到分片策略与分片算法。从执行 SQL 的角度来看,分库分表可以看作是一种路由机制,把 SQL 语句路由到我们期望的数据库或数据表中并获取数据,分片算法可以理解成一种路由规则。咱们先捋一下它们之间的关系,分片策略只是抽象出的概念,它是由分片算法和分片健组合而成,分片算法做具体的数据分片逻辑。
分库、分表的分片策略配置是相对独立的,可以各自使用不同的策略与算法,每种策略中可以是多个分片算法的组合,每个分片算法可以对多个分片健做逻辑判断。注意:sharding-jdbc 并没有直接提供分片算法的实现,需要开发者根据业务自行实现。

sharding-jdbc 提供了4种分片算法:
1、精确分片算法
精确分片算法(PreciseShardingAlgorithm)用于单个字段作为分片键,SQL中有 = 与 IN 等条件的分片,需要在标准分片策略(StandardShardingStrategy )下使用。
2、范围分片算法
范围分片算法(RangeShardingAlgorithm)用于单个字段作为分片键,SQL中有 BETWEEN AND、>、<、>=、<= 等条件的分片,需要在标准分片策略(StandardShardingStrategy )下使用。
3、复合分片算法
复合分片算法(ComplexKeysShardingAlgorithm)用于多个字段作为分片键的分片操作,同时获取到多个分片健的值,根据多个字段处理业务逻辑。需要在复合分片策略(ComplexShardingStrategy )下使用。
4、Hint分片算法
Hint分片算法(HintShardingAlgorithm)稍有不同,上边的算法中我们都是解析SQL 语句提取分片键,并设置分片策略进行分片。但有些时候我们并没有使用任何的分片键和分片策略,可还想将 SQL 路由到目标数据库和表,就需要通过手动干预指定SQL的目标数据库和表信息,这也叫强制路由。
分片策略
上边讲分片算法的时候已经说过,分片策略是一种抽象的概念,实际分片操作的是由分片算法和分片健来完成的。
1、标准分片策略
标准分片策略适用于单分片键,此策略支持 PreciseShardingAlgorithm 和 RangeShardingAlgorithm 两个分片算法。
其中 PreciseShardingAlgorithm 是必选的,用于处理 = 和 IN 的分片。RangeShardingAlgorithm 是可选的,用于处理BETWEEN AND, >, <,>=,<= 条件分片,如果不配置RangeShardingAlgorithm,SQL中的条件等将按照全库路由处理。
2、复合分片策略
复合分片策略,同样支持对 SQL语句中的 =,>, <, >=, <=,IN和 BETWEEN AND 的分片操作。不同的是它支持多分片键,具体分配片细节完全由应用开发者实现。
3、行表达式分片策略
行表达式分片策略,支持对 SQL语句中的 = 和 IN 的分片操作,但只支持单分片键。这种策略通常用于简单的分片,不需要自定义分片算法,可以直接在配置文件中接着写规则。
t_order_$->{t_order_id % 4} 代表 t_order 对其字段 t_order_id取模,拆分成4张表,而表名分别是t_order_0 到 t_order_3。
4、Hint分片策略
Hint分片策略,对应上边的Hint分片算法,通过指定分片健而非从 SQL中提取分片健的方式进行分片的策略。
分布式主键
数据分⽚后,不同数据节点⽣成全局唯⼀主键是⾮常棘⼿的问题,同⼀个逻辑表(t_order)内的不同真实表(t_order_n)之间的⾃增键由于⽆法互相感知而产⽣重复主键。尽管可通过设置⾃增主键初始值和步长的⽅式避免ID碰撞,但这样会使维护成本加大,乏完整性和可扩展性。如果后去需要增加分片表的数量,要逐一修改分片表的步长,运维成本非常高,所以不建议这种方式。实现分布式主键⽣成器的方式很多。为了让上手更加简单,ApacheShardingSphere 内置了UUID、SNOWFLAKE 两种分布式主键⽣成器,默认使⽤雪花算法(snowflake)⽣成64bit的⻓整型数据。不仅如此它还抽离出分布式主键⽣成器的接口,⽅便我们实现⾃定义的⾃增主键⽣成算法。
广播表
广播表:存在于所有的分片数据源中的表,表结构和表中的数据在每个数据库中均完全一致。一般是为字典表或者配置表 t_config,某个表一旦被配置为广播表,只要修改某个数据库的广播表,所有数据源中广播表的数据都会跟着同步。
绑定表
绑定表:那些分片规则一致的主表和子表。比如:t_order 订单表和 t_order_item 订单服务项目表,都是按 order_id 字段分片,因此两张表互为绑定表关系。那绑定表存在的意义是啥呢?通常在我们的业务中都会使用 t_order 和 t_order_item 等表进行多表联合查询,但由于分库分表以后这些表被拆分成N多个子表。如果不配置绑定表关系,会出现笛卡尔积关联查询,将产生如下四条SQL。
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id
SELECT * FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id
SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id

而配置绑定表关系后再进行关联查询时,只要对应表分片规则一致产生的数据就会落到同一个库中,那么只需 t_order_0 和 t_order_item_0 表关联即可。
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id

在关联查询时 t_order 它作为整个联合查询的主表。所有相关的路由计算都只使用主表的策略,t_order_item 表的分片相关的计算也会使用 t_order 的条件,所以要保证绑定表之间的分片键要完全相同。