接上一篇Python数据分析之--运动员数据揭秘(一),今天的分析主题:运动员身材揭秘
分析资料及工具:Spyder/Python3.6/Excle/奥运运动员数据.xlsx
声明:分析所用数据来自城市数据团(2016年的历史数据)
我也有用Excle对数据进行简单分析,结果见运动员数据分析结果
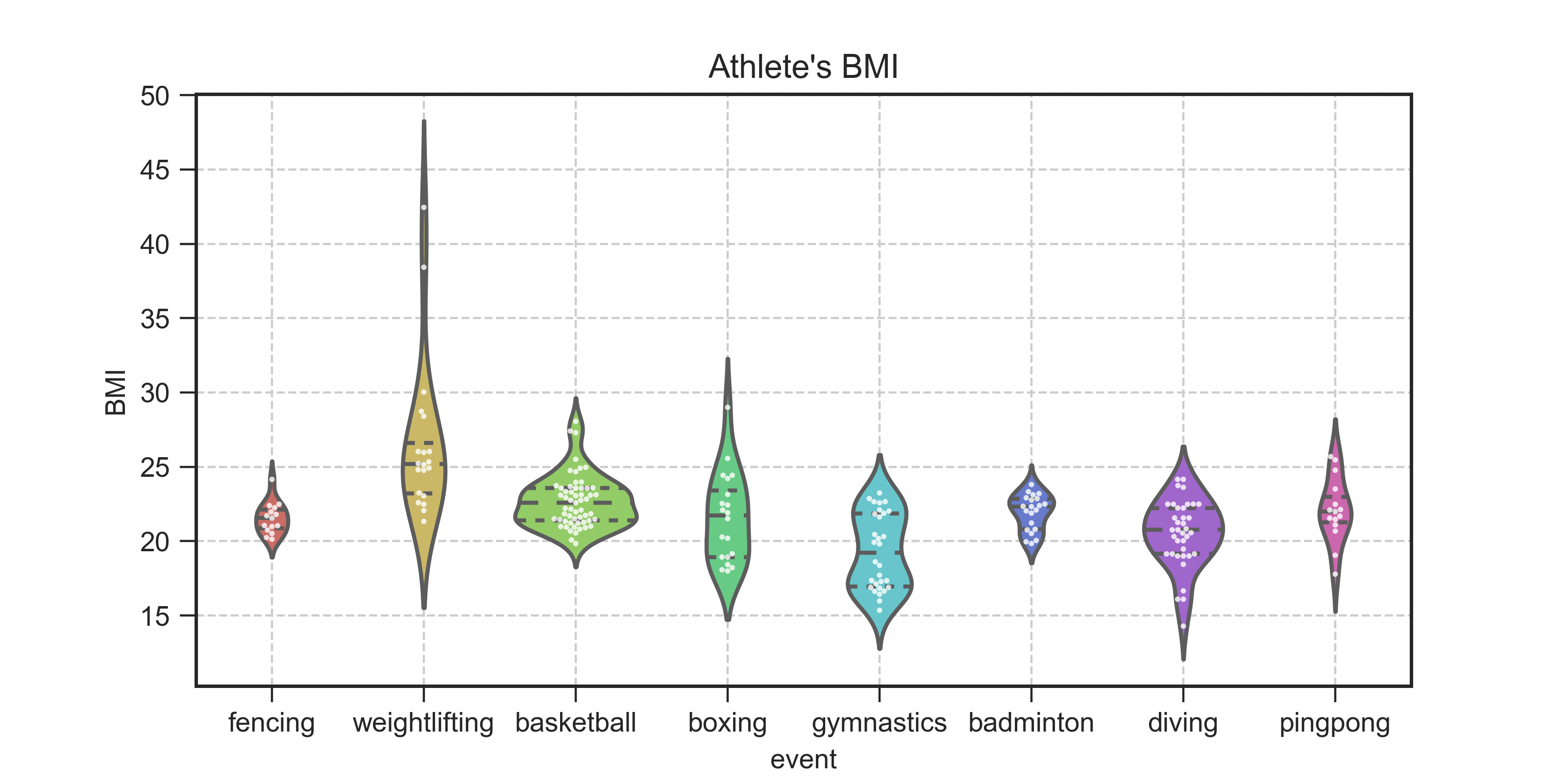
首先给大家看看,用python分析所绘制的结果图:
好了现在步入正题,打开Spyder新建文件,开启数据分析之旅。
首先导入相关工具包并创建好工作路径
import numpy as np # numpy - Python的数值计算扩展工具包 import pandas as pd # pandas - 基于Numpy的数据处理工具包 import matplotlib.pyplot as plt # matplotlib - Python的绘图工具包 import seaborn as sns # seaborn - matplotlib基础上的高级可视化工具包
import os
os.chdir('C:\\Users\\lenovo\\Desktop\\') # 创建工作路径
读取数据,查看基本信息
# 读取数据
df = pd.read_excel('奥运运动员数据.xlsx',sheetname=1)
df_length = len(df)
df_columns = df.columns.tolist()
因为要对运动员身材进行分析,所以基本的姓名、项目字段是需要的;因为采集的源数据里有身高和体重,所以采用BMI指数来作为身材的衡量指标。

数据筛选,选取姓名、项目、身高、体重这4个字段
data = df[['name','event','height','weight']]
在spyder里查看,发现有些项目人数太少(数据收集过程的问题),不具有代表意义,所以对远动员数量少于15人的项目,进行查找并筛除
# 查看数据样本中少于15人的项目 event_count = data['event'].value_counts() event_drop = event_count[event_count<15] #查看event_drop,只有 swim 项目 # 数据清洗, 去掉运动员少于15人的项目数据, 去掉个别缺失值 data2 = data[data['event'] != 'swim'] data2.dropna(inplace = True)
接下来要计算运动员BMI指数;BMI计算公式:体重(kg)/(身高*身高(m));由于源数据中身高的单位是cm,所以要对身高/100后再计算。
data2['BMI'] = data2['weight']/(data2['height']/100)**2
对数据进行可视化,绘图
sns.set_style("ticks") #图表风格设置
plt.figure(figsize = (8,4)) #画布大小设置
绘制小提琴图
sns.violinplot(x="event", y="BMI", data=data2,
scale = 'count', # 宽度以样本数量来显示,数据样本越多,小提琴图越宽
palette = "hls", # 设置调色盘颜色
inner = "quartile") # 内部显示为分位数
给小提琴图内部加上散点图,显示每项数据的具体分布情况
sns.swarmplot(x="event", y="BMI", data=data2, color="w", alpha=.8,s=2)
绘制图表细节,保存导出
plt.grid(linestyle = '--') # 添加网格线
plt.title("Athlete's BMI") # 设置标题
#plt.savefig('pic-2.png',dpi=400) # 图表导出
运行就得到了之前展示的图表:
这里根据运动员群体自身特点,不能按照标准的BMI指数来理解;所以将指数分为四挡:低于18.5纤瘦,18.5-23.9适中,24-27强壮,28-32极壮.
根据图我们可以看到,超过28的主要是举重、篮球、拳击这三个项目,也比较合理,因为这些项目本身对身体素质要求就很高;而低于18.5的主要是拳击、体操、游泳这三项,拳击主要是因为比赛有分不同的重量级,这部分是属于重量较轻的部分,而体操和游泳对身体灵敏度有要求,所以也有部分运动员比较纤瘦,这与我们平时的印象也相符;其他项目的运动员基本都处于适中状态;根据图的宽度,可以判断样本数量,本次分析中,运动员数量较多的是篮球、体操和游泳这三项;散点图表示各个运动员数据的整体分布情况。