标题1、深度学习模型参数
参数(parameters):模型根据输入数据自动学习出来的量,如神经网络中的权重
超参数(hyper-parameter):人通过经验人为设定的量 如学习率,网络层数
深度学习参数查看方法:
标题2、epoch batch batch iteration
1)epoch:使用训练集的全部数据对模型进行一次完整训练
为什么要使用多于一个epoch?
神经网络中传递完整的数据集一次,epoch的个数相当于模型迭代寻找最优参数的迭代次数 迭代次数在一定范围内 越高 越容易得到理想状态下的值
梯度下降与batchsize的关系?
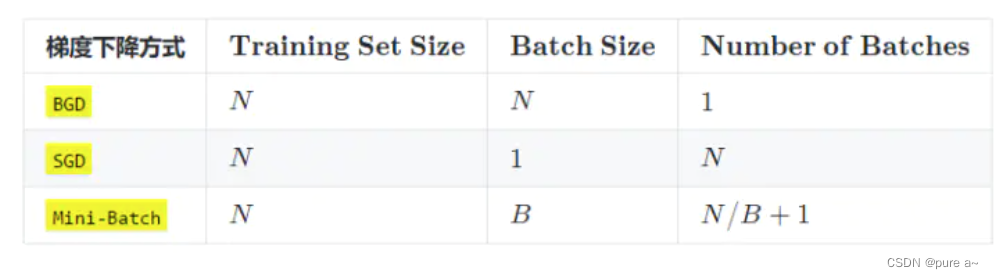
GD(Gradient Descent):没有batchsize 基于整个数据库得到梯度 梯度准确 但数据量大时 非常耗时
SGD(Stochastic Gradient Descent) 就是batchsize=1 每次计算一个样本 梯度不准确 所以学习率要降低
mini-batch SGD :选择合适的batchsize的SGD算法 mini-batch利用噪声梯度 一定程度上缓解了GD算法直接掉进初始点附近局部最优值 同时梯度准确了 学习率要加大
batch:使用训练集中的一小部分样本对模型权重进行一次反向传播的参数更新(如何参数更新?)这一小部分数据被称为batch
为什么要使用batch?->避免模型在训练时 需要把所有数据一次性输入网络 引起内存的爆炸。具体来说,在没有batch的时候模型会将所有的数据输入网络得到网络的估计输出 y_pred然后将输出与真实样本做损失得出一个平均值求出梯度。前面斜体的这句话理解的不对,输入模型的数据一般是(Batch,channel,width,height)深度学习进行的是向量运算,所以如果数据量多的话 并不是还将数据一个一个进行处理再输出平均值 而是直接当做一个整体 数据量为(Batchchannelwidth*height)进行计算 所以输入数据的数量 如果过多的话 会导致最后的数据量非常大的。
这种情况求出的梯度最能表征当前模型对数据的情况。但问题在于数据量过多,每次求梯度更新都会耗费较多时间。但如果采取单个数据进行更新的话 由于一个数据不能很好的反应整体样本的情况,所以会导致梯度不稳定。所以采取了折中的办法,使用整体数据的部分数据batch作为更新参数的数据量。这样既能保证较快更新 又能较充分的反应数据的形式。使用所有的数据作为梯度更新的数据也可以叫做 full batch 使用一个数据进行更新也可以叫做batch size=1
选择合适batchsize的意义?
batch可以通过并行化提高内存的利用率 尽量让GPU满载运行 提高训练速度
单个epoch的迭代次数少了 参数调整的慢了 如果想要达到相同的识别精度 需要更多的epoch
适当的batchsize使得梯度下降的方向更加准确
问题:一个batch的数据是如何同时输入到网络中的?
batchsize对模型训练结果的影响?
没有batchsize,梯度准确 只适用于小样本数据
batchsize=1 梯度变来变去 非常不准确 网络难收敛
batchsize增大 梯度已经非常准确 再增加batchsize没有意义,因为batchsize增大了 要想达到相同的准确度 就要增大epoch
iteration:使用一个batch对模型进行一次参数更新的过程
参考文章:
https://www.zhihu.com/question/32673260
https://community.eolink.com/d/32206-mini-batch
https://zhuanlan.zhihu.com/p/46500585
标题3、梯度爆炸 梯度消失
为什么会产生梯度爆炸 梯度消失
误差梯度在网络训练时被用来得到网络参数更新的方向和幅度,进而在正确的方向上以合适的幅度更新网络参数。
在深层网络或递归神经网络中,误差梯度在更新中累积得到一个非常大的梯度 这样的梯度会大幅度更新网络参数 进而导致网络不稳定 在极端情况下 权重的值特别大以至于结果溢出(NaN值,无穷与非数值)
产生梯度爆炸 梯度消失的表现是什么
明显特征
模型无法再训练数据上收敛 (损失函数的值非常大)
模型不稳定 在更新的时候 损失由较大变化
模型的损失函数值在训练过程变成NaN值
不太明显迹象:
模型在训练中 权重变化非常大
模型在训练中 权重变成NaN值
每层的每个节点在训练时 其误差梯度值一直是大于1.0
如何解决梯度爆炸
重现设计网络模型-》减少网络模型的层数
修正线性激活函数
在RNN情况下 使用LSTM
使用梯度裁剪-》在深度多层感知网络中 当有大批量数据以及LSTM是用于很长时间序列时 梯度爆炸仍然会发生 当梯度爆炸发生时 可以在网络训练时检查并限制梯度大小 这种方式是梯度裁剪
度裁剪是处理梯度爆炸问题的一个简单但非常有效的解决方案,如果梯度值大于某个阈值,我们就进行梯度裁剪
使用权重正则化:对网络权重大小进行校验 对大权重的损失函数增添一项惩罚项 也被称为权重正则化
梯度爆炸,解决方法:调学习率、梯度剪裁、归一化
参考文章:https://zhuanlan.zhihu.com/p/32154263
标题4、随机初始化权重的标准差 学习率对最后模型学习效果的影响
1)如何根据损失曲线来调整学习率
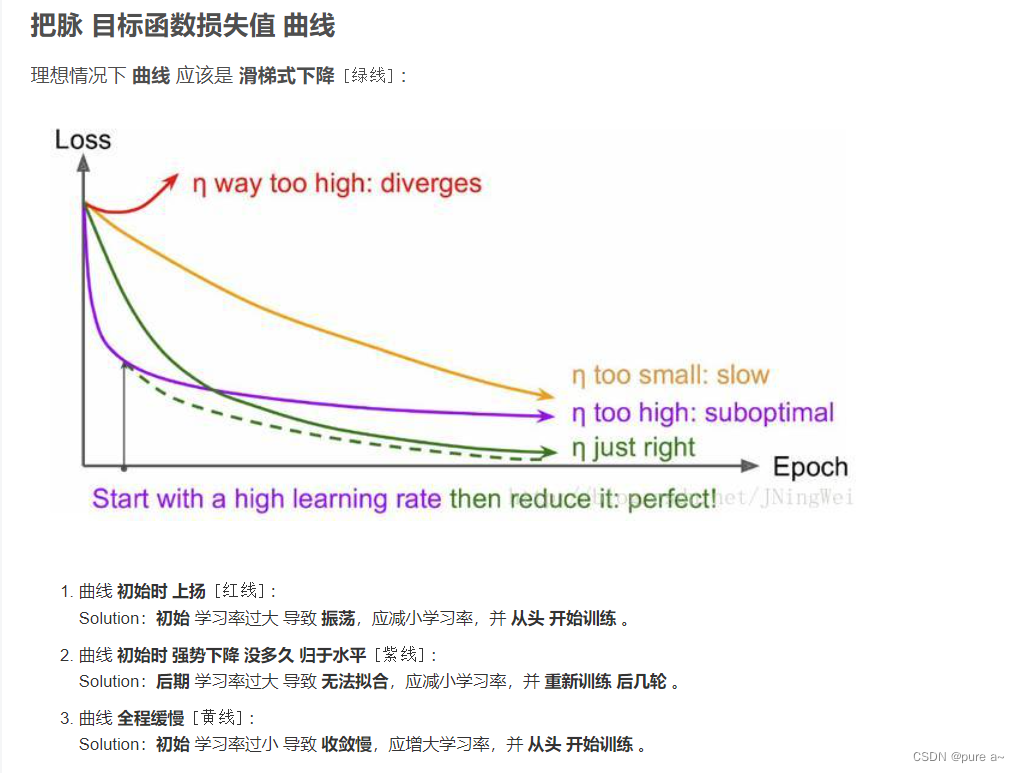
调参方法