前言
参考资料:
高升博客
《CUDA C编程权威指南》
以及 CUDA官方文档
CUDA编程:基础与实践 樊哲勇
文章、讲解视频同步更新公众《AI知识物语》,B站:出门吃三碗饭
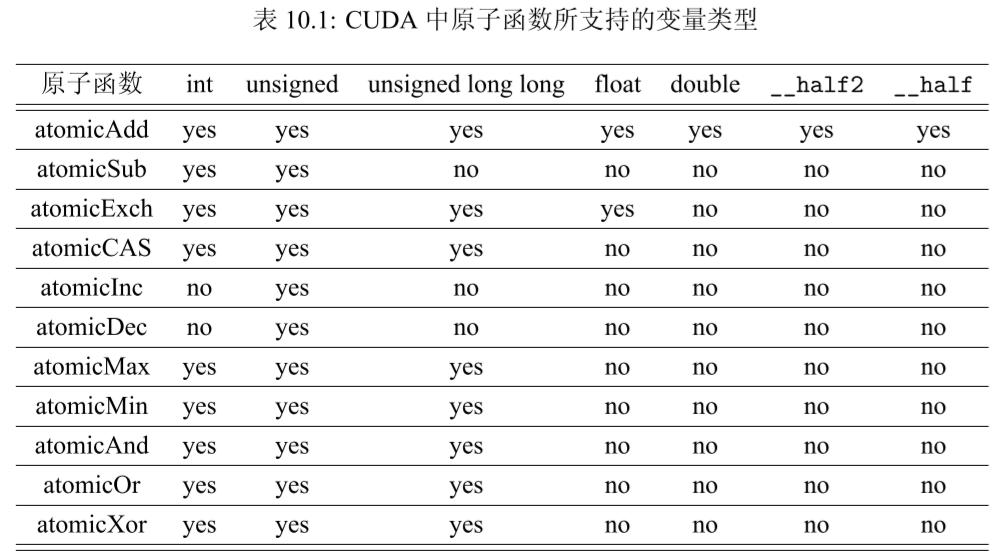
1:原子函数
原子操作(atomic operation)的函数,简称为原子函数。
在CUDA中,一个线程的原子操作可以在不受其他线程的 任何操作的影响下完成对某个(全局内存或共享内存中的)数据的一套“读-改-写”操作。
该套操作也可以说是不可分的。
2:原子函数与归约计算
归约计算参考上一章节(第9)的介绍。
前面几个章节的归约计算,核函数并没有做全部的计算,即没有全部在GPU执行,而只是将一个长 一些的数组 d_x 变成了一个短一些的数组 d_y,后者中的每个元素为前者中若干元素的和。在调用核函数之后,将短一些的数组复制到主机,然后在主机中完成了余下的求和。
有两种方法能够在GPU中 得到最终结果,
一是用另一个核函数将较短的数组进一步归约,得到最终的结果(一个数 值);
二是在先前的核函数的末尾利用原子函数进行归约,直接得到最终结果。
本文讨论第2种方法
//第9章归约核 函数的最后几行
//if 语句块的作用是将每一个线程块中归约的结果从共享内存 s_y[0] 复制到全
//局内 存d_y[bid]。为了将不同线程块的部分和s_y[0]累加起来,存放到一个全局
//内存地址
if (tid == 0)
{
d_y[bid] = s_y[0];
}
//使用原子函数
if (tid == 0)
{
//第一个参数是待累加变量的地址address,第二个 参数是累加的值val
//该函数的作用是将地址address中的旧值old读出,计算old + val, 然后将计算的值存入地址address。
//这些操作在一次原子事务(atomic transaction)中完成,不会被别的线程中的原子操作所干扰。
atomicAdd(&d_y[0], s_y[0]);
}
原子函数对它的第一个参数指向的数据进行一次**“读-改-写”的原子操作**。第一个参数可以指向全局内存,也可以指向共享内存。对所有参与的 线程来说,该“读-改-写”的原子操作是一个线程一个线程轮流做的,但没有明确的次序。另外,原子函数没有同步功能。
原子函数的原型
1. 加法:T atomicAdd(T *address, T val); 功能:new = old + val。
2. 减法:T atomicSub(T *address, T val); 功能:new = old - val。
3. 交换:T atomicExch(T *address, T val); 功能:new = val。
4. 最小值:T atomicMin(T *address, T val); 功能:new = (old < val) ? old : val。
5. 最大值:T atomicMax(T *address, T val);
功能:new = (old > val) ? old : val。
6. 自增:T atomicInc(T *address, T val); 功能:new = (old >= val) ? 0 : (old + 1)。
7. 自减:T atomicDec(T *address, T val); 功能:new = ((old == 0) || (old > val)) ? val : (old - 1)。
8. 比较-交换(Compare And Swap):T atomicCAS(T *address, T compare, T val); 功能:new = (old == compare) ? val : old。
9. 按位与:T atomicAnd(T *address, T val); 功能:new = old & val。
10. 按位或:T atomicOr(T *address, T val); 功能:new = old | val。
11. 按位异或:T atomicXor(T *address, T val);
功能:new = old ^ val。
原子函数–归约计算
#include<stdint.h>
#include<cuda.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <math.h>
#include <stdio.h>
#define CHECK(call) \
do \
{
\
const cudaError_t error_code = call; \
if (error_code != cudaSuccess) \
{
\
printf("CUDA Error:\n"); \
printf(" File: %s\n", __FILE__); \
printf(" Line: %d\n", __LINE__); \
printf(" Error code: %d\n", error_code); \
printf(" Error text: %s\n", \
cudaGetErrorString(error_code)); \
exit(1); \
} \
} while (0)
#ifdef USE_DP
typedef double real;
#else
typedef float real;
#endif
const int NUM_REPEATS = 100;
const int N = 100000000;
const int M = sizeof(real) * N;
const int BLOCK_SIZE = 128;
void timing(const real* d_x);
int main(void)
{
real* h_x = (real*)malloc(M);
for (int n = 0; n < N; ++n)
{
h_x[n] = 1.23;
}
real* d_x;
CHECK(cudaMalloc(&d_x, M));
CHECK(cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice));
printf("\nusing atomicAdd:\n");
timing(d_x);
free(h_x);
CHECK(cudaFree(d_x));
return 0;
}
void __global__ reduce(const real* d_x, real* d_y, const int N)
{
const int tid = threadIdx.x;
const int bid = blockIdx.x;
const int n = bid * blockDim.x + tid;
extern __shared__ real s_y[];
s_y[tid] = (n < N) ? d_x[n] : 0.0;
__syncthreads();
for (int offset = blockDim.x >> 1; offset > 0; offset >>= 1)
{
if (tid < offset)
{
s_y[tid] += s_y[tid + offset];
}
__syncthreads();
}
if (tid == 0)
{
atomicAdd(d_y, s_y[0]);
}
}
real reduce(const real* d_x)
{
const int grid_size = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;
const int smem = sizeof(real) * BLOCK_SIZE;
real h_y[1] = {
0 };
real* d_y;
CHECK(cudaMalloc(&d_y, sizeof(real)));
CHECK(cudaMemcpy(d_y, h_y, sizeof(real), cudaMemcpyHostToDevice));
reduce << <grid_size, BLOCK_SIZE, smem >> > (d_x, d_y, N);
CHECK(cudaMemcpy(h_y, d_y, sizeof(real), cudaMemcpyDeviceToHost));
CHECK(cudaFree(d_y));
return h_y[0];
}
void timing(const real* d_x)
{
real sum = 0;
for (int repeat = 0; repeat < NUM_REPEATS; ++repeat)
{
cudaEvent_t start, stop;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
CHECK(cudaEventRecord(start));
cudaEventQuery(start);
sum = reduce(d_x);
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time);
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
}
printf("sum = %f.\n", sum);
}
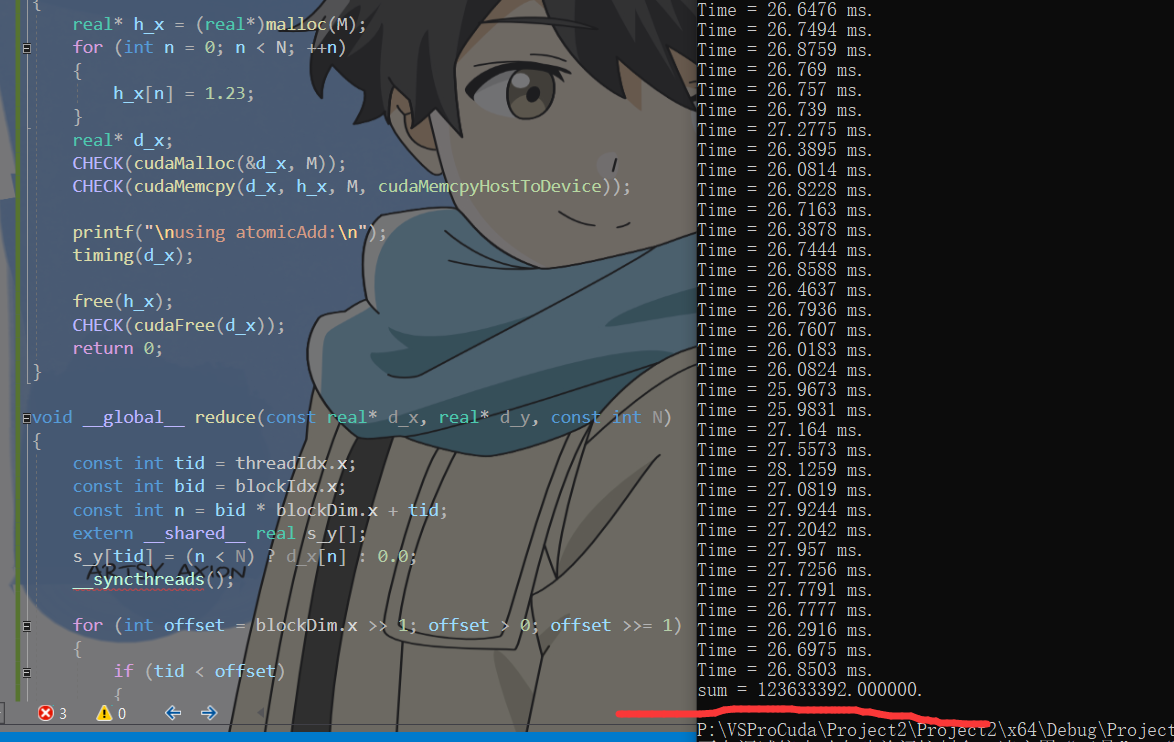
相比于第9篇文章使用共享内存29ms,有了稍微的性能提升