VS2017 CUDA编程学习1:CUDA编程两变量加法运算
VS2017 CUDA编程学习2:在GPU上执行线程
VS2017 CUDA编程学习3:CUDA获取设备上属性信息
VS2017 CUDA编程学习4:CUDA并行处理初探 - 向量加法实现
VS2017 CUDA编程学习5:CUDA并行执行-线程
VS2017 CUDA编程学习6: GPU存储器架构
VS2017 CUDA编程学习7:线程同步-共享内存
前言
又到了学习CUDA编程的时刻,继续上一篇线程同步的学习,这次学习原子操作,这里做下笔记并分享给大家。
1. 原子操作的理解
我们都知道,多线程运行程序不可避免会出现数据竞态问题,即多个线程同一时刻读取-修改-写入同一变量数据,很明显这会出问题。举个例子,我的账户有5000元,我和我的朋友在不同的ATM机同时取4000元,这里的数据竞态问题就是ATM机就会分别吐给我和我的朋友4000元,但是我的账户只有5000元,确取出了8000元,看看,这就是有问题。
原子操作就可以避免多线程数据竞态问题,个人理解,原子操作就是不可多个线程同时读取-修改-写入同一变量数据。
2. C++ CUDA实现原子操作
这里以自增运算为例实现CUDA原子操作,即使用atomicAdd()函数,当然这里也会给出非原子操作结果,来证实上面我们所说的多线程数据竞态问题确实存在。
#include <stdio.h>
#include <cuda.h>
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#include <device_atomic_functions.h>
//#include <sm_20_atomic_functions.h>
#define NUM_THREADS 10000
#define SIZE 10
#define BLOCK_WIDTH 100
//内核函数:不使用原子操作的自增实现
__global__ void gpu_increment_without_atomic(int* d_a)
{
int tid = blockIdx.x*blockDim.x + threadIdx.x;
tid = tid % SIZE;
d_a[tid] += 1;
}
//内核函数:使用原子操作的自增实现
__global__ void gpu_increment_atomic(int* d_a)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
tid = tid % SIZE;
atomicAdd(&d_a[tid], 1);
}
int main()
{
printf("线程总数:%d, 块的数量:%d, 数组大小:%d\n",
NUM_THREADS, NUM_THREADS / BLOCK_WIDTH, SIZE);
//声明并分配主机(CPU)内存
int h_a[SIZE];
const int ARRAY_BYTES = SIZE * sizeof(int);
//声明并分配GPU内存
int *d_a;
cudaMalloc(&d_a, ARRAY_BYTES);
//初始化GPU内存
cudaMemset(d_a, 0, ARRAY_BYTES);
//调用内核函数
//gpu_increment_without_atomic << <NUM_THREADS / BLOCK_WIDTH, BLOCK_WIDTH >> > (d_a);
gpu_increment_atomic << <NUM_THREADS / BLOCK_WIDTH, BLOCK_WIDTH >> > (d_a);
//从GPU内存中拷贝数据到CPU内存中
cudaMemcpy(h_a, d_a, ARRAY_BYTES, cudaMemcpyDeviceToHost);
printf("未使用原子操作的累加计算结果(理论上每个数组索引累加1000次):\n");
for (int i = 0; i < SIZE; i++)
{
printf("数组索引:%d, 累加次数:%d\n", i, h_a[i]);
}
//释放GPU内存
cudaFree(d_a);
system("pause");
return 0;
}
3. 执行结果
未使用原子操作的自增结果:
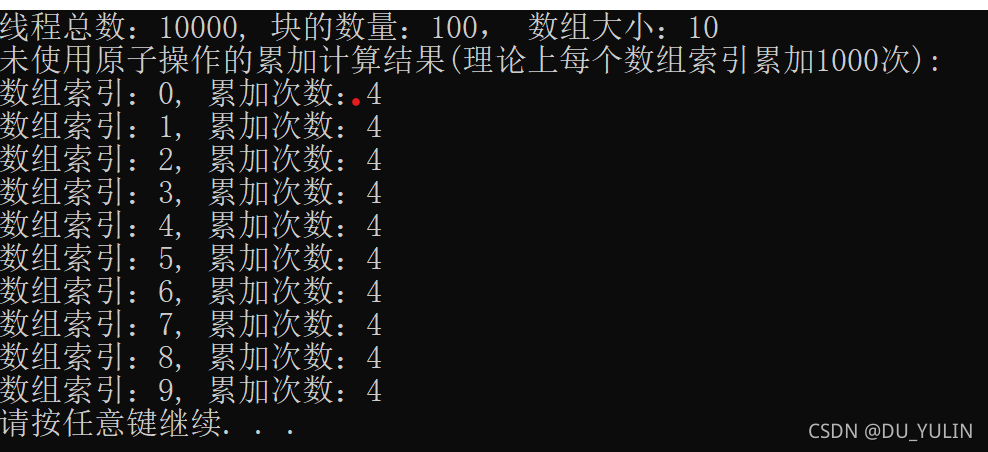 使用原子操作后的自增结果:
使用原子操作后的自增结果:
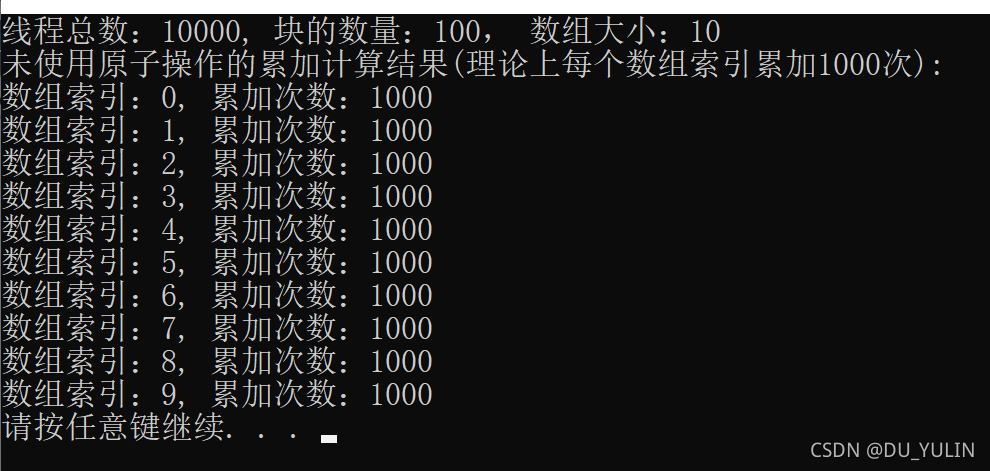
总结
从上述结果图可以知道,多线程数据竞态问题确实存在,使用原子操作也确实能够解决该问题,但是这也会增加运行时间,至于增加多少还要具体项目具体分析,这里就不细说了,本人也是菜鸟一枚,如有错误,希望指正,谢谢大家!
学习资料
《基于GPU加速的计算机视觉编程》