VS2017 CUDA编程学习1:CUDA编程两变量加法运算
VS2017 CUDA编程学习2:在GPU上执行线程
VS2017 CUDA编程学习3:CUDA获取设备上属性信息
VS2017 CUDA编程学习4:CUDA并行处理初探 - 向量加法实现
VS2017 CUDA编程学习5:CUDA并行执行-线程
VS2017 CUDA编程学习6: GPU存储器架构
VS2017 CUDA编程学习7:线程同步-共享内存
VS2017 CUDA编程学习8:线程同步-原子操作
前言
这里继续CUDA编程的学习,今天学习了设备常量内存的使用,这里分享给大家!
1. 常量内存的理解
设备常量内存,个人理解,和CPU上常量内存作用相同,都是存储不可改变的变量,可以用来存储内核执行期间的常量数据,据说使用常量内存可以节省全局内存的访问带宽,这点个人还没有尝试。常量内存之所以可以节省全局内存的访问带宽和warp技术和常量内存自带的缓存相关,warp技术本人没有深究,这里就不细说了,等后面了解后再给大家分享吧。
2. C++ CUDA实现常量内存使用
常量内存定义使用关键字 _ _ c o n s t a n t _ _ \_\_constant\_\_ __constant__ 标记,常量数据拷贝使用函数 c u d a M e m c p y T o S y m b o l ( . . . ) cudaMemcpyToSymbol(...) cudaMemcpyToSymbol(...)实现。
#include <stdio.h>
#include <iostream>
#include <cuda.h>
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
//定义两个常量
__constant__ int constant_f;
__constant__ int constant_g;
#define N 5
//定义内核函数用来使用常量内存
__global__ void gpu_constant_memory(float* d_in, float* d_out)
{
//获取当前内核的线程索引
int tid = threadIdx.x;
d_out[tid] = constant_f * d_in[tid] + constant_g;
}
int main()
{
//定义主机变量
float h_in[N], h_out[N];
//定义设备指针
float* d_in, *d_out;
int h_f = 2;
int h_g = 20;
//为设备指针分配设备内存
cudaMalloc(&d_in, N * sizeof(float));
cudaMalloc(&d_out, N * sizeof(float));
//初始化主机数组
for (int i = 0; i < N; i++)
{
h_in[i] = i;
}
//将主机数据拷贝到设备指针中
cudaMemcpy(d_in, h_in, N * sizeof(float), cudaMemcpyHostToDevice);
//拷贝主机数据到设备常量内存中, 参数4表示写入目标的偏移量,参数5表示数据的传输方向
cudaMemcpyToSymbol(constant_f, &h_f, sizeof(int), 0, cudaMemcpyHostToDevice);
//参数4和5使用默认值
cudaMemcpyToSymbol(constant_g, &h_g, sizeof(int));
//调用内核函数,1个block, 每个block分配N个线程
gpu_constant_memory << <1, N >> > (d_in, d_out);
//拷贝设备数据到主机变量中
cudaMemcpy(h_out, d_out, N * sizeof(float), cudaMemcpyDeviceToHost);
//打印结果
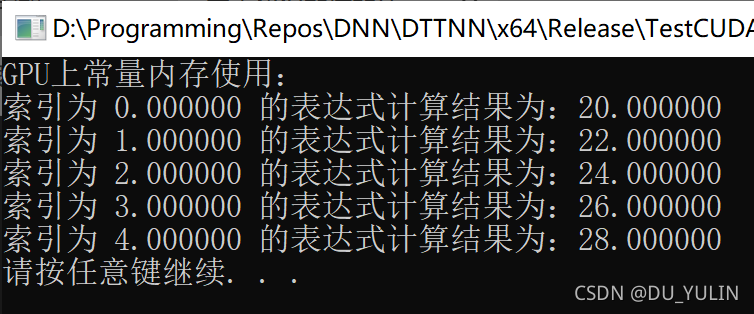
printf("GPU上常量内存使用:\n");
for (int i = 0; i < N; i++)
{
printf("索引为 %f 的表达式计算结果为:%f \n", h_in[i], h_out[i]);
}
//释放设备内存
cudaFree(d_in);
cudaFree(d_out);
system("pause");
return 0;
}
3. 执行结果
总结
今天又学习到了新的知识,每天进步一点点,感觉还是很好的!
学习资料
《基于GPU加速的计算机视觉编程》