数据标注的思维导图
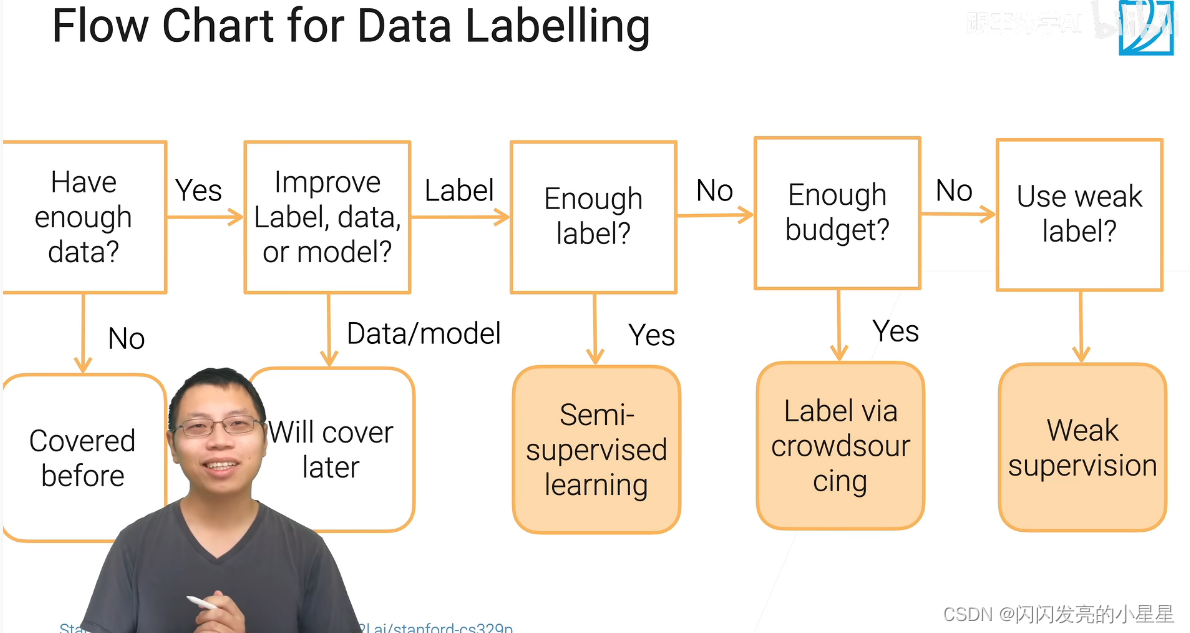
目标:是提升模型还是提升标注,本小节讨论提升标准,提升模型后面介绍。
如果有足够标注:使用半监督学习
没有足够标注,有足够预算:请人标注
没有足够预算:使用弱监督学习
问题: 什么是弱监督学习器
半监督学习
Semi-Supervised Learning(SSL)
有标注数据和未标注数据要满足以下假设:
假设1: 连续性假设:如果两个样本特征相似,则这两个样本很有可能有相同的标号
假设2:聚类的假设:数据内在具有比较好的聚类效果,类内的数据可能有相同的标号
假设3:流形假设:虽然收集到的数据维度高,但是数据本质上可能是低维的,数据复杂度远比看到的低,可以通过降维实现。
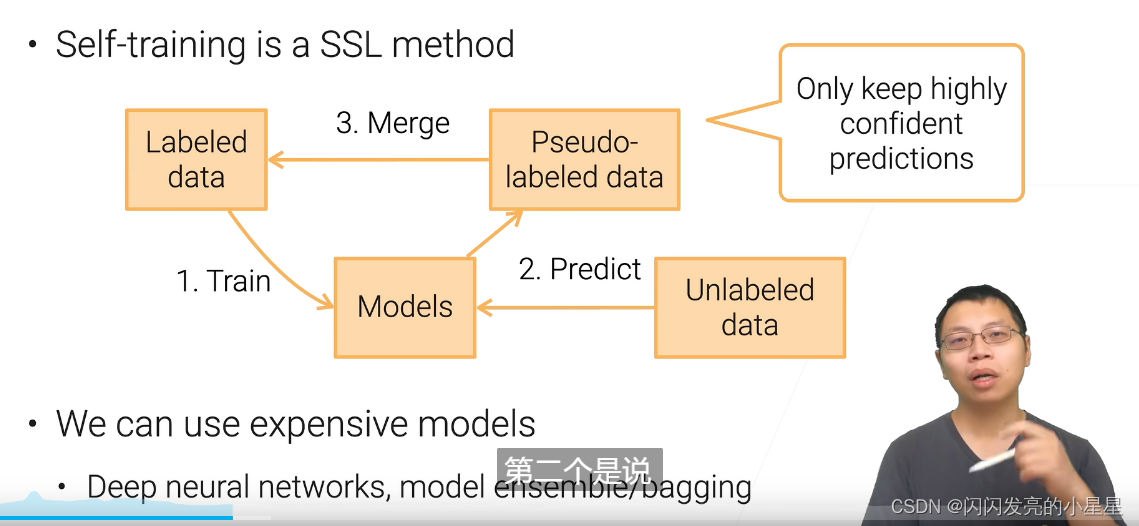
Self-training (自学习)
一种最基本的半监督学习
- 进行训练
- 对未标号的数据进行预测,得到label (伪标号)
- 将标号数据与伪标号数据进行融合
- 重复
ps: 只将概率很高的确信的结果留下加入新一轮训练中,不确信的留在后面。
众包

其他技术
如MIT place 365
是或不是

主动学习
与半监督学习相似,已有一些标号,还有一些没有。 主动是指人的主动
选择最有趣的样本去打标。
- 不确定采样 ,将最不确定的样本进行人工采样
- 与半监督学习类似,使用贵的模型,训练多种模型,实行投票制,确认类别。

主动学习 与 自学习
一开始有部分已标好的数据,进行训练得到一个模型,对其样本进行预测,对最置信的样本放进标号样本里,如果不确认,将样本反馈给人工进行标注。不断重复。

质量控制
发给多个标注工

若监督学习
- 半自动生成标号。

- 数据编程。用启发式算法去标号。
-
关键词搜索 模式匹配 第三方模型 - 总结一些规律,辅助打标
比如判断YouTube 的评论是正常的还是机器或者广告。通过规律,如果 check out in x .lower. 如果情绪值大于0.9等。
总结
1 自训练
2 众包
数据编程 如启发式编程