文章目录
摘要
使用Deep Convolutional Neural Networks进行大规模人脸识别的特征学习的主要挑战之一是设计适当的损失函数来增强鉴别能力。Centre loss通过惩罚深层特征和它们对应类中心之间的欧氏距离,以实现类内紧凑性。SphereFace假设最后一个全连接层中的线性变换矩阵可以用作角空间中类中心的表示,并以乘法方式对深度特征及其相应权重之间的角度进行惩罚。最近,一个流行的研究方向是在已成熟的损失函数中加入margin,以最大化人脸类别的可分性。在本文中,我们提出了Additive Angular Margin Loss(ArcFace)来获得人脸识别的高分辨特征。由于与超球面上的测地距离精确对应,所提出的ArcFace具有清晰的几何解释。我们在10多个face recognition benchmarks上对所有SOTA人脸识别方法进行了最广泛的实验评估,包括一个新的具有万亿对级别的大规模图像数据库和一个大规模视频数据集。作者表明,ArcFace始终优于SOTA,并且在计算开销可以忽略不计的情况下轻松实现。
Introduction
使用Deep Convolutional Neural Network嵌入的人脸表示是人脸识别方案之一。典型地,在姿态标准化处理之后,DCNNs将人脸图像映射成具有小的类内距和大的类间距特征。训练用于人脸识别的DCNNs主要有两条研究路线。那些训练多分类的分类器可以分离训练集中的不同身份,例如通过使用softmax分类器,以及那些直接学习嵌入的分类器,如triplet loss。基于大规模训练数据和精心设计的DCNN结构,基于softmax loss和triplet loss的方法都可以在人脸识别上获得优异的性能。然而,softmax loss和triplet loss都有一些缺点。
对于softmax loss:
(1)线性变换矩阵的尺寸 W ∈ R d × n W∈{\mathbb{R}^{d \times n}} W∈Rd×n随 n n n线性增加;
(2)对于闭集分类问题,学习的特征是可分离的,但对于开集人脸识别问题,学习的特征并没有足够的区分度。
对于triplet loss:
(1)face triplets的数量存在组合爆炸,特别是对于大规模数据集,这导致迭代步骤数量显著增加;
(2)semi-hard样本挖掘对于有效的模型训练是一个相当困难的问题。
已经提出了几种变体来增强softmax loss的鉴别能力。Wen等人首创了centre loss,即每个特征向量与其类中心之间的欧氏距离,以获得类内紧性,而类间离散性由softmax loss的联合惩罚来保证。然而,在训练过程中更新实际的centres是极其困难的,因为最近可供训练的人脸类别的数量急剧增加。
通过观察在softmax损失上训练的分类DCNN的最后一个全连接层的权重与每个面部类别的中心具有概念上的相似性,一些文献中的工作提出了一种multiplicative angular margin惩罚,以同时加强额外的类内紧凑性和类间差异,从而使训练的模型具有更好的辨别能力。尽管Sphereface引入了angular margin的重要概念,但它们的损失函数需要一系列近似才能计算,这将导致网络的训练不稳定。为了稳定训练,他们提出了一个混合损失函数,其中包括标准的softmax loss。根据经验,softmax损失在训练过程中占主导地位,因为基于整数的multiplicative angular margin使目标logit曲线非常陡峭,从而阻碍收敛。CosFace直接向目标logit添加cosine margin惩罚,与SphereFace相比,它获得了更好的性能,但允许更容易的实现,并减轻了softmax损失对联合监督的需求。
在本文中,我们提出了一个Additive Angular Margin Loss(ArcFace)来进一步提高人脸识别模型的识别能力和稳定训练过程。如下图所示,DCNN特征和最后一个全连接层之间的点积等于特征和权重归一化后的余弦距离。我们利用arc-cosine来计算当前特征和目标重量之间的角度。然后,我们在目标角度上增加一个additive angular margin,并通过余弦函数再次得到目标logit。然后,我们通过一个固定的特征范数来重新缩放所有的逻辑,并且后续的步骤与softmax损失中的步骤完全相同。ArcFace的优势可总结如下:
Engaging:ArcFace通过在标准化的超球面中角度和弧之间的精确对应直接优化测地距离余量。我们通过分析特征和权重之间的角度统计来直观地说明在512-D空间中发生了什么。
Effective:ArcFace在包括大规模图像和视频数据集在内的十个人脸识别基准上实现了SOTA。

Easy:ArcFace只需要算法1中给出的几行代码,并且在基于计算图的深度学习框架中非常容易实现。此外,ArcFace不需要与其他损失函数相结合才能具有稳定的性能,并且可以容易地在任何训练数据集上收敛。
Efficient:ArcFace在训练过程中增加的计算复杂度可以忽略不计。目前的GPU可以轻松支持数百万个身份进行训练,模型并行策略可以轻松支持更多身份。
Proposed Approach
ArcFace
最广泛使用的分类损失函数softmax损失如下:
L 1 = − 1 N ∑ i = 1 N log e W y i T x i + b y i ∑ j = 1 n e W j T x i + b j {L_1} = - \frac{1}{N}\sum\limits_{i = 1}^N {\log \frac{ { {e^{W_{ {y_i}}^T{x_i} + {b_{ {y_i}}}}}}}{ {\sum\nolimits_{j = 1}^n { {e^{W_j^T{x_i} + {b_j}}}} }}} L1=−N1i=1∑Nlog∑j=1neWjTxi+bjeWyiTxi+byi
其中 x i ∈ R d x_i∈{\mathbb{R}^d} xi∈Rd表示属于第 y i y_i yi个类别的第 i i i个样本的深度特征,嵌入的特征维度d被设为 512 512 512, W j ∈ R d W_j∈{\mathbb{R}^d} Wj∈Rd表示权重 W ∈ R d × n W∈{\mathbb{R}^{d×n}} W∈Rd×n的第 j j j列, b j ∈ R n b_j∈{\mathbb{R}^n} bj∈Rn则是偏置项, N N N代表batchsize, n n n代表类别数。传统的softmax广泛应用于深度人脸识别。然而,softmax损失函数没有明确地优化特征嵌入,以加强类内样本的更高相似性和类间样本的多样性,这导致在大的类内外观变化(例如姿势变化和年龄差距)和大规模测试场景(例如百万对或万亿对)下深度人脸识别的性能差距。
为简单起见,固定 b j = 0 b_j=0 bj=0,使 W y i T x i = ∥ W j ∥ ∥ x i ∥ cos θ j {W_{
{y_i}}^T{x_i}}=\left\| {
{W_j}} \right\|\left\| {
{x_i}} \right\|\cos {\theta _j} WyiTxi=∥Wj∥∥xi∥cosθj,其中 θ j \theta _j θj是权重 W j W_j Wj与特征 x i x_i xi。利用 l 2 l_2 l2正则化,固定 ∥ W j ∥ = 1 \left\| {
{W_j}} \right\|=1 ∥Wj∥=1, ∥ x i ∥ = s \left\| {
{x_i}} \right\|=s ∥xi∥=s。在特征以及权重上的正则化步骤使得预测仅依赖于特征和权重之间的角度。因此,所学习的嵌入特征分布在半径为s的超球面上。
L 2 = − 1 N ∑ i = 1 N log e s cos θ y i e s cos θ y i + ∑ j = 1 , j ≠ y i n e s cos θ y i {L_2} = - \frac{1}{N}\sum\limits_{i = 1}^N {\log \frac{
{
{e^{s\cos {\theta _{yi}}}}}}{
{
{e^{s\cos {\theta _{yi}}}} + \sum\nolimits_{j = 1,j \ne {y_i}}^n {
{e^{s\cos {\theta _{yi}}}}} }}} L2=−N1i=1∑Nlogescosθyi+∑j=1,j=yinescosθyiescosθyi
由于嵌入特征分布在超球面上的每个特征中心周围,我们在 W y i W_{y_i} Wyi和 x i x_i xi之间增加了一个additive angular margin惩罚 m m m以同时增强类内紧密度和类间差异。由于提出的additive angular margin惩罚等于在标准化超球面中geodesic distance margin惩罚,因此将提出的方法命名为ArcFace。
L 3 = − 1 N ∑ i = 1 N log e s ( cos ( θ y i + m ) ) e s ( cos ( θ y i + m ) ) + ∑ j = 1 , j ≠ y i n e s cos θ y i {L_3} = - \frac{1}{N}\sum\limits_{i = 1}^N {\log \frac{
{
{e^{s(\cos ({\theta _{
{y_i}}} + m))}}}}{
{
{e^{s(\cos ({\theta _{
{y_i}}} + m))}} + \sum\nolimits_{j = 1,j \ne {y_i}}^n {
{e^{s\cos {\theta _{
{y_i}}}}}} }}} L3=−N1i=1∑Nloges(cos(θyi+m))+∑j=1,j=yinescosθyies(cos(θyi+m))
我们从包含足够样本(约1500个图像/类)的8个不同身份中选择人脸图像,分别使用软softmax和ArcFace训练2D特征嵌入网络。如下午所示,softmax提供了粗糙的可分离的特征嵌入,在决策边界中则产生了明显的模糊性,而所提出的ArcFace显然可以在最相近的类之间形成更明显的差距。

SphereFace与CosFace的比较
Numerical Similarity: SphereFace、ArcFace和CosFace中,提出了三种不同的裕度惩罚(margin penalty),例如multiplicative angular margin m 1 m_1 m1、additive angular margin m 2 m_2 m2和additive cosine margin m 3 m_3 m3。从数值分析的角度来看,不同的裕度惩罚,无论是增加角度还是余弦空间,都通过惩罚目标logit来加强类内紧凑性和类间多样性。如下图所示,我们绘制了SphereFace、ArcFace和CosFace在最佳边距设置下的目标逻辑曲线。我们只在 [ 20 ° , 100 ° ] [20°,100°] [20°,100°]内显示这些目标逻辑曲线,因为在ArcFace训练期间, W y i W_{y_i} Wyi与 x i x_i xi之间的角度从大约 90 ° 90° 90°(随机初始化)开始,并在大约 30 ° 30° 30°结束。直觉上,目标logit曲线中有三个因素会影响性能,即起点、终点和斜率。

通过结合所有的margin penalties,我们在一个统一的框架中实现了SphereFace、ArcFace和CosFace,其中 m 1 m_1 m1、 m 2 m_2 m2和 m 3 m_3 m3是超参数。
L 4 = − 1 N ∑ i = 1 N log e s ( cos ( m 1 θ y i + m 2 ) − m 3 ) e s ( cos ( m 1 θ y i + m 2 ) − m 3 ) + ∑ j = 1 , j ≠ y i n e s cos θ j {L_4} = - \frac{1}{N}\sum\limits_{i = 1}^N {\log \frac{
{
{e^{s(\cos ({m_1}{\theta _{
{y_i}}} + {m_2}) - {m_3})}}}}{
{
{e^{s(\cos ({m_1}{\theta _{
{y_i}}} + {m_2}) - {m_3})}} + \sum\nolimits_{j = 1,j \ne {y_i}}^n {
{e^{s\cos {\theta _j}}}} }}} L4=−N1i=1∑Nloges(cos(m1θyi+m2)−m3)+∑j=1,j=yinescosθjes(cos(m1θyi+m2)−m3)
如上图(b)所示,通过组合上述所有margins ( c o s ( m 1 θ + m 2 ) − m 3 ) (cos(m_1θ+m_2)-m_3) (cos(m1θ+m2)−m3),我们可以很容易地得到一些其他j具有很高性能的目标logit曲线。
Geometric Difference: 尽管ArcFace和以前的工作在数值上有相似之处,但所提出的additive angular margin具有更好的几何属性,因为additive angular margin与测地距离有精确的对应关系。如下图所示,我们比较了二分类情况下的决策边界。所提出的ArcFace在整个区间内具有恒定的linear angular margin。相比之下,SphereFace和CosFace只有一个nonlinear angular margin。

margin设计的微小差异会对模型训练产生“蝴蝶效应”。例如,最初的SphereFace采用了退火优化策略。为了避免训练开始时的发散,在SphereFace中使用softmax的联合监督来削弱multiplicative margin惩罚。通过应用反余弦函数,而不是使用复杂的双角度公式,我们实现了一个不需要在margin上使用整数的SphereFace。在我们的实现中,我们发现 m = 1.35 m=1.35 m=1.35可以获得与原始SphereFace相似的性能且没有任何收敛困难。
与其它损失函数比较
其他损失函数可以基于特征和权重向量的角度表示来设计。例如,我们可以设计一个损失来加强超球面上的类内紧性和类间差异。如下图所示,我们比较了其它三种损失。
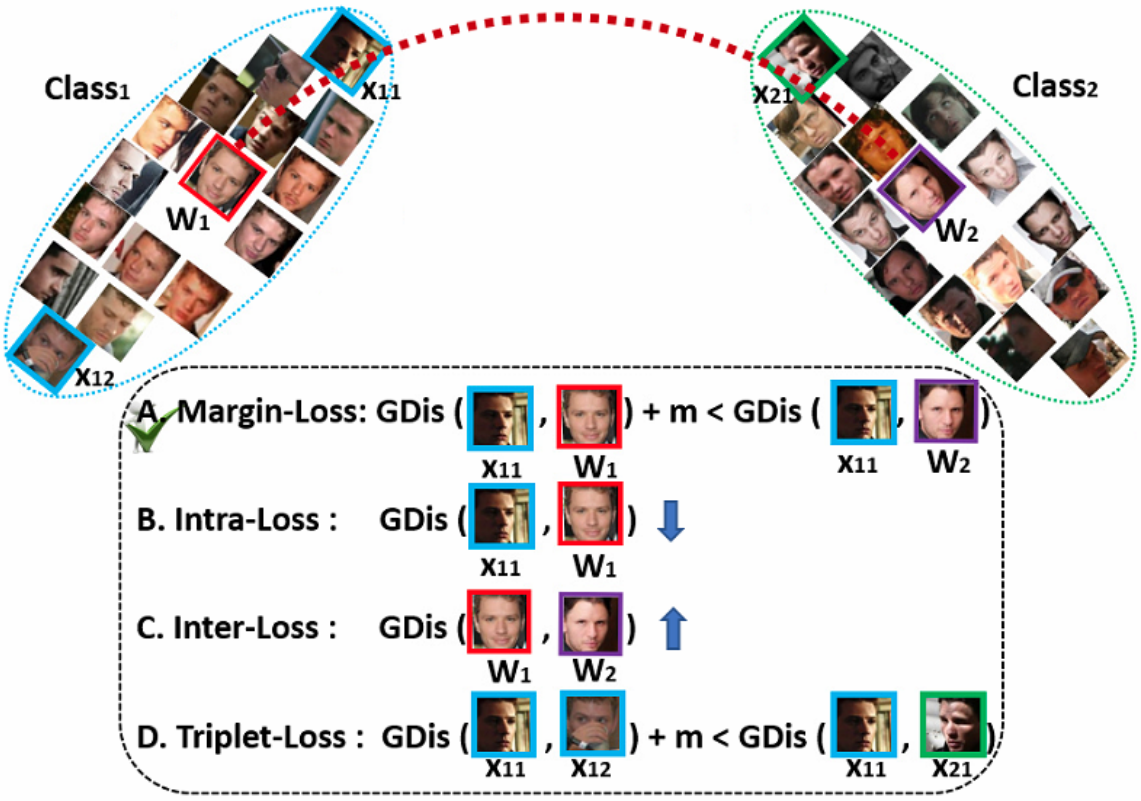
Intra-Loss: 旨在通过减小样本和地面真实中心之间的角度/弧度来提高类内紧密度。
L 5 = L 2 + 1 π N ∑ i = 1 N θ y i {L_5} = {L_2} + \frac{1}{
{\pi N}}\sum\limits_{i = 1}^N {
{\theta _{
{y_i}}}} L5=L2+πN1i=1∑Nθyi
Inter-Loss: 目标是通过增加不同中心之间的角度/弧度来增强类间差异。
L 6 = L 2 − 1 π N ( n − 1 ) ∑ i = 1 N ∑ j = 1 , j ≠ y i n arccos ( W y i T W j ) {L_6} = {L_2} - \frac{1}{
{\pi N(n - 1)}}\sum\limits_{i = 1}^N {\sum\limits_{j = 1,j \ne {y_i}}^n {\arccos (W_{
{y_i}}^T{W_j})} } L6=L2−πN(n−1)1i=1∑Nj=1,j=yi∑narccos(WyiTWj)
这里的Inter-Loss是Minimum Hyper-spherical Energy(MHE)方法的一个特例。在这个特例中,隐藏层和输出层都由MHE正则化。在MHE论文中,还提出了一个特殊的损失函数的例子,它在网络最后一层将SphereFace损失和的MHE损失结合起来。
Triplet-loss: 旨在扩大三个样本之间的角度/弧度余量。在FaceNet中,Euclidean margin被应用于归一化的特征。在这里,我们采用triplet-loss作为特征的角度表示 arccos ( x i p o s x i ) + m ⩽ arccos ( x i n e g x i ) \arccos (x_i^{pos}{x_i}) + m \leqslant \arccos (x_i^{neg}{x_i}) arccos(xiposxi)+m⩽arccos(xinegxi)
实验
Implementation Details
Datasets:
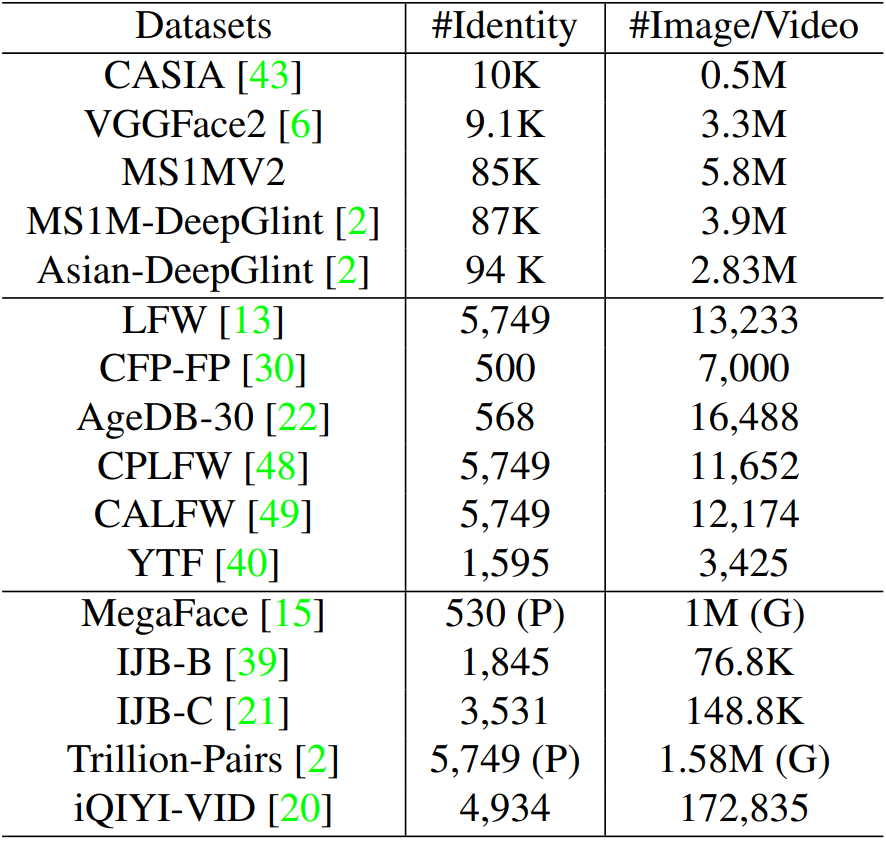
如下表所示,我们分别采用CASIA、VGGFace2、MS1MV2和DeepGlint-Face(包括MS1M-DeepGlint和Asian-DeepGlint)作为我们的训练数据,以便与其他方法进行公平的比较。请注意,所提出的MS1MV2是一个semi-automatic refinedversion。据我们所知,我们是第一个使用种族特定的注释器进行大规模人脸图像注释,因为如果注释器不熟悉身份,边界情况(例如hard samples和noisy samples)很难区分,在训练过程中,我们探索有效的人脸验证数据集(如LFW,CFP-FP,AgeDB-30),以检查不同设置的改进。除了最广泛使用的LFW和YTF数据集之外,我们还报告了ArcFace在最近的大规模姿态和大范围年龄数据集(例如CPLFW和CALFW)上的性能。我们还在大规模图像数据集(如megafface、IJB-B、IJB-C和万亿对)和视频数据集(iQIYI-VID)上广泛测试了所提出的ArcFace。
Experimental Settings:
对于数据预处理,我们利用五个facial points来生成归一化的面部裁剪区域。对于嵌入网络,我们采用广泛使用的CNN架构,ResNet50和ResNet100。在最后一个卷积层,我们探索BN-dropped-FC-BN结构以获得最终的512-D嵌入特征。在本文中,我们使用([训练集,网络结构,损失])来促进对实验设置的理解。
我们将特征比例 s s s设置为 64 64 64,并选择ArcFace的角度裕度 m m m为 0.5 0.5 0.5。采用MXNet框架实现,其中batchsize为512,并在四个NVIDIA Tesla P40(24GB)GPU上训练模型。在CASIA上,学习率从 0.1 0.1 0.1开始,在 20 K 20K 20K, 28 K 28K 28K迭代时除以10。训练过程在 32 K 32K 32K次迭代中完成。在MS1MV2上,我们在 100 K 100K 100K、 160 K 160K 160K迭代时划分学习率,在 180 K 180K 180K迭代时结束。我们将momentum设置为0.9,weight decay为 5 e − 4 5e-4 5e−4。在测试过程中,我们只保留没有完全连接层的特征嵌入网络(对于ResNet50为 160 M B 160MB 160MB,对于ResNet100为 250 M B 250MB 250MB),并为每个归一化的人脸提取 512 D 512D 512D特征(对于ResNet50为8.9 ms/face,对于ResNet100为15.4 ms/face)。为了获得模板(例如IJB-B和IJB-C)或视频(例如YTF和iQIYI-VID)的嵌入特征,我们简单地计算来自模板的所有图像或来自视频的所有帧的特征中心。请注意,为了进行严格的评估,训练集和测试集之间的重叠标识被移除,并且我们只对所有测试使用单个裁剪。
损失函数上的消融研究
如下表所示,我们首先用ResNet50在CASIA数据集上探索ArcFace的角度裕度设置。在我们的实验中观察到的最佳差值是 0.5 0.5 0.5。使用我们在上述所提出的框架、更容易设置SphereFace和CosFace的余量,我们发现当分别设置为 1.35 1.35 1.35和 0.35 0.35 0.35时,它们具有最佳性能。我们对SphereFace和CosFace的实现可以带来出色的性能,而不会在收敛方面遇到任何困难。所提出的ArcFace在所有三个测试集上都达到了最高的验证精度。此外,我们在上图中的目标logit曲线的指导下,对组合margin framework进行了大量实验(CM1( 1 , 0.3 , 0.2 1,0.3,0.2 1,0.3,0.2)和CM2 ( 0.9 , 0.4 , 0.15 0.9,0.4,0.15 0.9,0.4,0.15)观察到了一些最佳表现)。组合的margin framework比单个的SphereFace和CosFace的性能更好,但上限为ArcFace的性能表现。
除了与基于margin的方法进行比较之外,我们还对ArcFace和其他旨在加强类内紧凑性和类间差异性的损失进行了进一步的比较。作为基线,我们选择了softmax,并观察到CFP-FP和AgeDB-30在权重和特征后性能下降。通过将softmax与类内损失相结合,性能在CFP-FP和AgeDB-30上有所提高。然而,将softmax与类间损失相结合只会略微提高精度。事实上,Triplet-loss优于Norm-Softmax损失表明了margin在提高性能方面的重要性。然而,在三元组样本中使用边距惩罚不如在样本和中心之间插入边距有效,如在弧面中。最后,我们将类内损失、类间损失和Triplet-loss纳入ArcFace,但没有观察到任何改进,这使我们相信ArcFace已经在加强类内紧密性、类间差异和分类裕度。
为了更好地了解Arcface的优势,我们在表3中的不同损失下提供了关于培训数据(CASIA)和测试数据(LFW)的详细角度统计数据。我们发现对于ArcFace
(1) W j W_j Wj与嵌入特征中心几乎同步的Arcface( 14.2 9 ◦ 14.29^◦ 14.29◦),但对于Norm-Softmax,在 W j W_j Wj和嵌入特征中心之间存在明显的偏差( 44.26 ˚ 44.26˚ 44.26˚)。因此, W j W_j Wj之间的角度不能绝对代表训练数据的类间差异。或者,由训练网络计算的嵌入特征中心更具代表性。
(2)类内损失可以有效地压缩类内变化,但也带来了较小的类间角度。
(3)类间损失可以略微增加 W W W(直接)和嵌入网络(间接)的类间差异,但也提高了类内角度。
(4)ArcFace已经具有非常良好的类内紧凑性和类间差异。
(5)Triplet-Loss与ArcFace相比,有类似的类内紧凑性,较差的类间差异。此外,在测试集上ArcFace具有比Triplet-Loss更明显的边距,如下图所示。

评估结果
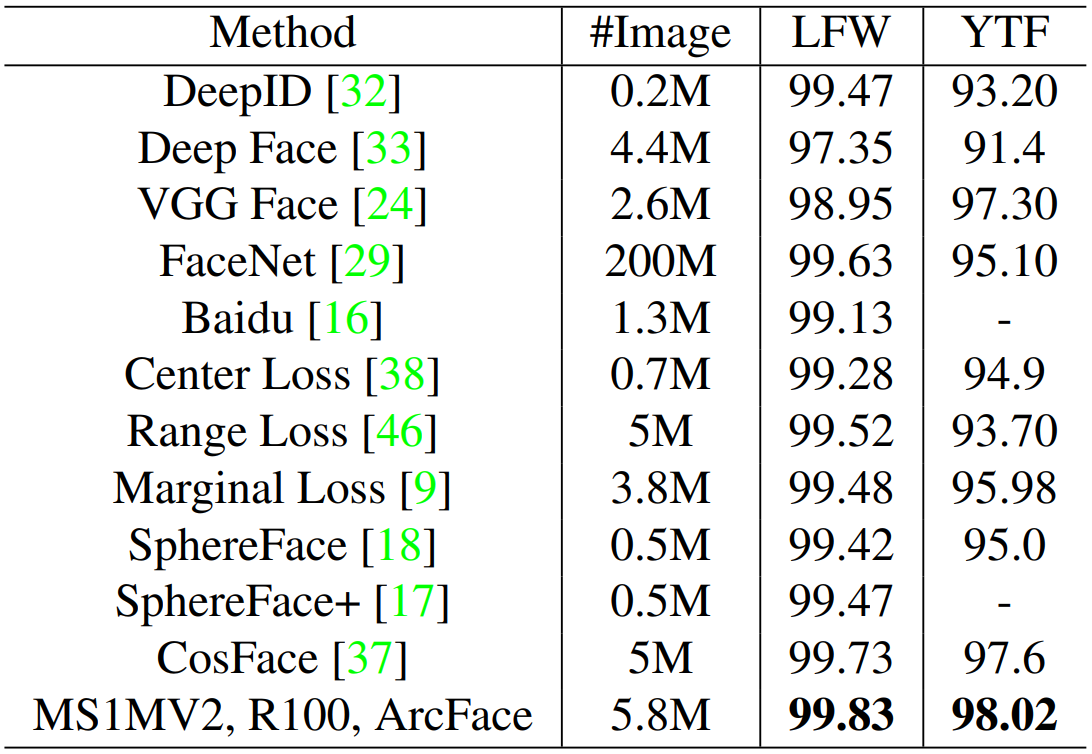
Results on LFW, YTF, CALFW and CPLFW: LFW和YTF数据集是在图像和视频上不受约束面部验证最广泛使用的基准。如下表所示,在MS1MV2上使用Resnet100培训的ArcFace在LFW和YTF以显著的margin击败了baseline(Sphereface和Cosface),这表明additive angular margin惩罚可以显着提高深度学习特征的辨别力,这展示ArcFace的有效性。
除了LFW和YTF数据集外,我们还报告了最近引入的数据集(例如CPLFW和CALFW)上ArcFace的性能,其显示了与LFW相同身份的更广泛的姿态和年龄变化。如下表所示,在所有开源面部识别模型中,ArcFace模型以优于同行明显的·margin·被评估为顶级人脸识别模型。

如下图所示,我们说明了在LFW、CFP-FP、AgeDB-30、YTF、CPLFW和CALFW上正负对的角度分布(由在MS1MV2数据集上使用ResNet100训练的ArcFace模型进行预测)。我们可以清楚地发现,由于姿态和年龄间隔引起的帧内方差显着增加了正对之间的角度,从而使得面部验证的最佳阈值增加并且在直方图上产生更多的混乱区域。

Results on MegaFace.
MegaFace DataSet包括 1 M 1M 1M张图像,其中包含 690 k 690k 690k独特个体作为gallery set,来自Facescrub的 530 530 530独特个体的 100 k 100k 100k照片作为probe set。在Megaface上,在两个协议(大型或小型训练集)下有两个测试场景(识别和验证)。如果它包含超过0.5米的图像,则定义训练集。对于公平的比较,我们分别在小型协议和大协议下培训CAISA和MS1MV2的ArcFace。在表6中,Casia培训的ArcFace培训了最佳的单模识别和验证性能,不仅超越了强的基线(例如,Sphereface [18]和Cosface [37]),还优于其他公开的方法[38,17]。两个协议(大/小训练集)下有两个测试场景( 识别 和 验证 )。如果训练集包含超过 0.5 M 0.5M 0.5M图像则被定为 大数据集。为了公平的比较,我们分别在小协议和大协议下在CAISA和MS1MV2上训练ArcFace。在下表中,CAISA上训练的ArcFace实现了最佳的单模识别和验证性能,不仅超越了强大的基线(Sphereface和Cosface),还优于其他公开的方法。

由于我们在识别和验证之间观察到明显的性能差距,我们在整个MegaFace数据集中进行了彻底的手动检查,并发现了许多具有错误标签的面部图像,这将明显影响测试性能。因此,我们手动改进了整个MegaFace数据集,并在MegaFace上报告了ArcFace的正确表现。在数据清洗后的MegaFace,ArcFace仍然显著优于CosFace并实现了验证和识别方面的最佳性能。
在大协议下,ArcFace通过明确的margin超越Faceget,与CosFace相比,在识别上获得了可比较的结果,在验证上获得了更好的结果。由于CosFace采用私人的训练数据,我们在MS1MV2数据集上将CosFace联合Resnet100重新训练。在公平比较下,ArcFace在CosFace上显示出优越性,并在识别和验证场景下形成压倒性优势,如下图所示。

Results on IJB-B and IJB-C: IJB-B数据集包含 1 , 845 1,845 1,845个主题,共有 21.8 K 21.8K 21.8K静止图像和来自 7 , 011 7,011 7,011个视频的 55 K 55K 55K帧。总共有 12 , 115 12,115 12,115个模板,具有 10 , 270 个 10,270个 10,270个真实匹配和 8 M 8M 8M的冒名匹配。IJB-C数据集是IJB-B的另一个延伸,具有 3 , 531 3,531 3,531个受试者,具有 31.3 k 31.3k 31.3k静态图像和 117.5 k 117.5k 117.5k帧,来自 11 , 779 11,779 11,779个视频。总共有 23 , 124 23,124 23,124个模板, 19 , 557 19,557 19,557个真实匹配和 15 , 639 K 15,639K 15,639K冒名匹配。
在IJB-B和IJB-C数据集上,我们使用VGG2数据集作为训练数据,Reset50作为嵌入式网络来训练ArcFace,以便与最近的方法进行公平比较。在下表中,我们将ArcFace的 T A R TAR TAR( @ F A R = 1 E − 4 @ FAR = 1E-4 @FAR=1E−4)与先前的最先进模型进行比较。 ArcFace可以显然提高IJB-B和IJB-C(约 3 〜 5 % 3〜5% 3〜5%的性能,这是错误的显着减少)。从更多训练数据(MS1MV2)和更深的神经网络(Resnet100)中,ArcFace可以在IJB-B和IJBC上进一步将 T A R TAR TAR( @ F A R = 1 E − 4 @ FAR = 1E-4 @FAR=1E−4)改善为 94.2 % 94.2% 94.2%和 95.6 % 95.6% 95.6%。在下图中,我们在IJB-B和IJB-C上显示了所提出的ArcFace完整ROC曲线,即使在FAR= 1E-6,ArcFace也可以实现令人印象深刻的性能并设置一个新的baseline。

Results on Trillion-Pairs. Trillion-Pairs数据集提供了来自Flickr的 1.58 M 1.58M 1.58M图像作为gallery set以及来自于 5.7 k 5.7k 5.7kLFW身份的 274 K 274K 274K图像作为probe set。gallery set和probe set之间的每一对都用于评估(总共0.4万亿对)。在下表中,我们比较了在不同数据集上训练的ArcFace性能。与CASIA相比,所提出的MS1MV2数据集明显提高了性能,甚至略优于具有双身份的DeepGlint-Face数据集。当结合MS1MV2和DeepGlint的亚洲名人的所有身份时,ArcFace实现了 84.840 84.840% 84.840( @ F P R = 1 e − 3 @FPR=1e-3 @FPR=1e−3)的最佳识别性能,并且其验证性能能够与lead-board最新提交(CIGIT IRSEC)不相上下。

Results on iQIYI-VID.:
iQIYI-VID挑战赛包含来自爱奇艺综艺节目、电影和电视剧的 4934 4934 4934个身份的 565 , 372 565,372 565,372个视频剪辑(训练集 219 , 677 219,677 219,677、验证集 172 , 860 172,860 172,860和测试集 172 , 835 172,835 172,835)。每个视频的长度从 1 1 1到 30 30 30秒不等。该数据集提供了多模态线索,包括人脸、布料、声音、步态和字幕,用于字符识别。iQIYI-VID数据集采用 M A P @ 100 MAP@100 MAP@100作为评价指标。 M A P MAP MAP (Mean Average Precision)指的是总体平均准确率,是测试集中检索到的人物ID对应视频对训练集中每个人物ID(作为查询)的平均准确率的均值。
如下表所示,在MS1MV2和Asian数据集上使用ResNet100训练的ArcFace设置了一个高baseline( M A P = ( 79.80 MAP=(79.80%) MAP=(79.80))。基于每个训练视频的嵌入特征,我们训练了一个附加的三层全连通网络,该网络带有一个分类损失,以获得iQIYI-VID数据集上的自定义特征描述符。MLP在iQIYI-VID训练集上的学习显著提高了 6.60 6.60% 6.60的平均成绩。借助模型集成的支持和现成的对象和场景分类器的上下文特征,我们的最终结果明显优于亚军( 0.99 % 0.99\% 0.99%))。

Conclusions
在本文中,我们提出了一个Additive Angular Margin损失函数,对于人脸识别,可以有效增强通过DCNN学习的特征嵌入的判别能力, 在文献报道的最全面的实验中,证明了我们的方法始终优于最先进的方法。
资源文件
ArcFace-Paddle-GitHub
ArcFace-MXNet-GitHub
ArcFace-Pytorch-GitHub
关于作者

| 姓名 | 郭权浩 |
|---|---|
| 学校 | 电子科技大学研2020级 |
| 研究方向 | 计算机视觉 |
| 主页 | Deep Hao的主页 |
| 如有错误,请及时留言纠正,非常蟹蟹! | |
| 后续会有更多论文复现系列推出,欢迎大家有问题留言交流学习,共同进步成长! |