论文阅读笔记:SphereFace: Deep Hypersphere Embedding for Face Recognition
本文主要包含如下内容:
2017 CVPR, 文章主要提出了归一化权重(normalize weights and zero biases)和角度间距(angular margin),对传统网络softmax进行改进,实现角度softmax网络,实现了最大类内距离小于最小类间距离,进一步提高人脸识别的精度(当然,可以用于分类任务中).
SphereFace在MegaFace数据集上识别率在2017年排名第一.
主要思想
针对人脸识别任务,为了进一步提高人脸识别精度,提取更加有效的特征,即减小类内误差,提高类间误差,因此,论文提出了新的网络结构:SphereFace,该网络改变softmax的表达形式,即转换为对应的角度softmax(归一化权重/偏差为0/角度表达),将传统正确分类的方法转化为角度间隔的学习方法.从而实现了让最大类内距离小于最小类间距离.
网络结构
A-Softmax是根据Softmax推到出来的,Softmax后验概率为:
由最大似然原则,使用如下公式作为loss函数,即softmaxloss.因此softmaxloss主要分为两步,softmax和logloss,softmaxloss定义如下:
对上述公式进行权重归一化,偏差置0,就可以得到修正的损失函数
在二分类问题中,当cos(θ1)>cos(θ2)时,可以确定属于类别1,但分类1与分类2的决策面是同一分,说明分类1与分类2之间的间隔(margin)相当小,直观上的感觉就是分类不明显。如果要让分类1与分类2有一个明显的间隔,可以做两个决策面,对于类别1的决策平面为:cos(mθ1)=cos(θ2),对于类别2的策平面为:cos(θ1)=cos(mθ2),其中m≥2,m∈N。m是整数的目的是为了方便计算,因为可以利用倍角公式,m≥2说明与该分类的最大夹角要比其它类的小小夹角还要小m倍。如果m=1,那么类别1与类别2的决策平面是同一个平面,如果m≥2v,那么类别1与类别2的有两个决策平面,相隔多大将会在性质中说明。从上述的说明与Lmodified可以直接得到A-Softmax Loss:
其中
实验结果
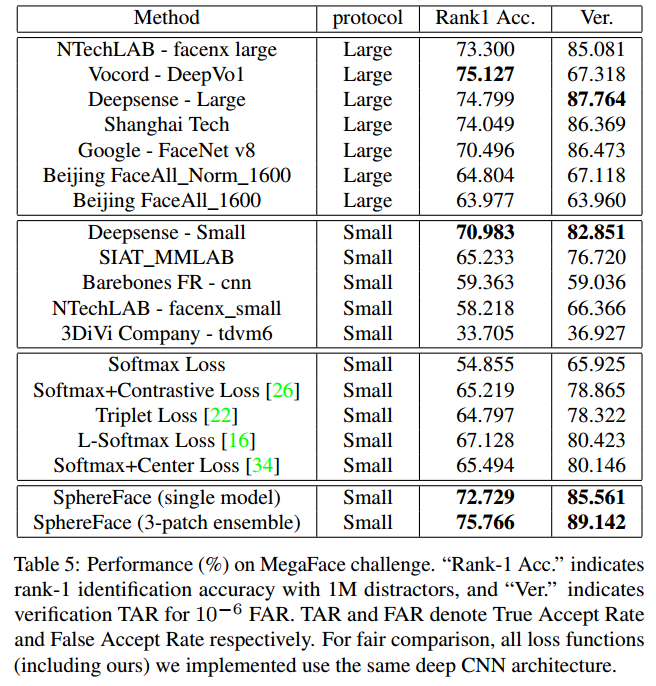
A-Softmax在较小的数据集合上有着良好的效果且理论具有不错的可解释性,它的缺点也明显就是计算量相对比较大,也许这就是作者在论文中没有测试大数据集的原因。
代码实现
源文件主要由四个部分组成:caffe.proto /margin_inner_product_layer.cpp /margin_inner_product_layer.cu /margin_inner_product_layer.hpp.
首先,了解一下caffe.proto文件
message MarginInnerProductParameter {
optional uint32 num_output = 1; // 输出类别
enum MarginType {
SINGLE = 0;
DOUBLE = 1;
TRIPLE = 2;
QUADRUPLE = 3;
}
optional MarginType type = 2 [default = SINGLE]; // 类型type
optional FillerParameter weight_filler = 3; // 权重初始化
optional int32 axis = 4 [default = 1];
// base/gamma/power/lambda_min/iteration为了便于学习,定义公式
// lambda_ = base_ * pow(((Dtype)1. + gamma_ * iter_), -power_);
// lambda_ = std::max(lambda_, lambda_min_);
optional float base = 5 [default = 1];
optional float gamma = 6 [default = 0];
optional float power = 7 [default = 1];
optional int32 iteration = 8 [default = 0];
optional float lambda_min = 9 [default = 0];
}接下来,我们看看源码margin_inner_product_layer.hpp:
MarginInnerProductParameter_MarginType type_;
// common variables
Blob<Dtype> x_norm_; // 对应输入的模值
Blob<Dtype> cos_theta_; // 对应输入的cos值,x'w/|x|
Blob<Dtype> sign_0_; // sign_0 = sign(cos_theta) // 正负号函数,输出-1、0、1,这里用来规范正负范围
// for DOUBLE type
Blob<Dtype> cos_theta_quadratic_; // cos 的平方
// for TRIPLE type
Blob<Dtype> sign_1_; // sign_1 = sign(abs(cos_theta) - 0.5)
Blob<Dtype> sign_2_; // sign_2 = sign_0 * (1 + sign_1) - 2
Blob<Dtype> cos_theta_cubic_; // cos 的立方
// for QUADRA type
Blob<Dtype> sign_3_; // sign_3 = sign_0 * sign(2 * cos_theta_quadratic_ - 1) // 对应论文中(-1)^k
Blob<Dtype> sign_4_; // sign_4 = 2 * sign_0 + sign_3 - 3 // 对应论文中-2k
Blob<Dtype> cos_theta_quartic_; // cos 的四次方
int iter_;
Dtype lambda_; 接下来,我们看看源码margin_inner_product_layer.cpp:
注意:在type:SINGLE时,lambda_不加入运算,此时lambda无效
#include <vector>
#include "caffe/blob.hpp"
#include "caffe/common.hpp"
#include "caffe/filler.hpp"
#include "caffe/layer.hpp"
#include "caffe/util/math_functions.hpp"
#include "caffe/layers/margin_inner_product_layer.hpp"
namespace caffe {
template <typename Dtype>
void MarginInnerProductLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
CHECK_EQ(bottom[0]->num(), bottom[1]->num())
<< "Number of labels must match number of output; "
<< "DO NOT support multi-label this version." // 不支持多标签
<< "e.g., if prediction shape is (M X N), "
<< "label count (number of labels) must be M, "
<< "with integer values in {0, 1, ..., N-1}.";
type_ = this->layer_param_.margin_inner_product_param().type(); // 类型
iter_ = this->layer_param_.margin_inner_product_param().iteration(); // iter_
lambda_ = (Dtype)0.; // lambda初始化为0
const int num_output = this->layer_param_.margin_inner_product_param().num_output();
N_ = num_output; // 输出类别个数
const int axis = bottom[0]->CanonicalAxisIndex(
this->layer_param_.margin_inner_product_param().axis()); // axis默认为1
// Dimensions starting from "axis" are "flattened" into a single
// length K_ vector. For example, if bottom[0]'s shape is (N, C, H, W),
// and axis == 1, N inner products with dimension CHW are performed.
K_ = bottom[0]->count(axis); // 扁平化处理,即压缩为对应类别后数目,即 k_ = C*H*W
// Check if we need to set up the weights // 检查是否需要设置权重,这里分开训练与测试
if (this->blobs_.size() > 0) {
LOG(INFO) << "Skipping parameter initialization"; // 如果blobs中存在值,就不进行初始化
} else {
this->blobs_.resize(1);
// Intialize the weight
vector<int> weight_shape(2); // 初始化vector, 大小为 num_output * C*H*W
weight_shape[0] = N_;
weight_shape[1] = K_;
this->blobs_[0].reset(new Blob<Dtype>(weight_shape)); // 初始化 blobs_
// fill the weights
shared_ptr<Filler<Dtype> > weight_filler(GetFiller<Dtype>(
this->layer_param_.margin_inner_product_param().weight_filler()));
weight_filler->Fill(this->blobs_[0].get());
} // parameter initialization // 使用对应初始化方法初始化
this->param_propagate_down_.resize(this->blobs_.size(), true);
}
template <typename Dtype>
void MarginInnerProductLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// Figure out the dimensions
const int axis = bottom[0]->CanonicalAxisIndex(
this->layer_param_.margin_inner_product_param().axis());
const int new_K = bottom[0]->count(axis);
CHECK_EQ(K_, new_K) // 比较每次数据维度是否相同
<< "Input size incompatible with inner product parameters.";
// The first "axis" dimensions are independent inner products; the total
// number of these is M_, the product over these dimensions.
M_ = bottom[0]->count(0, axis);
// The top shape will be the bottom shape with the flattened axes dropped,
// and replaced by a single axis with dimension num_output (N_).
// 根据输入维度 reshape 输出维度,即 C * N * H * W --> C * (N_)
vector<int> top_shape = bottom[0]->shape();
top_shape.resize(axis + 1);
top_shape[axis] = N_; // 设置第二维的输出维度
top[0]->Reshape(top_shape);
// if needed, reshape top[1] to output lambda // 如果输出为两个,reshape第二个数据 lambda
if (top.size() == 2) {
vector<int> lambda_shape(1, 1);
top[1]->Reshape(lambda_shape);
}
// common temp variables // 初始化一般变量x_norm_/x_norm_/cos_theta_
vector<int> shape_1_X_M(1, M_);
x_norm_.Reshape(shape_1_X_M);
sign_0_.Reshape(top_shape);
cos_theta_.Reshape(top_shape);
// optional temp variables // 这里根据不同的type类型初始化对应的参数变量
switch (type_) {
case MarginInnerProductParameter_MarginType_SINGLE:
break;
case MarginInnerProductParameter_MarginType_DOUBLE:
cos_theta_quadratic_.Reshape(top_shape);
break;
case MarginInnerProductParameter_MarginType_TRIPLE:
cos_theta_quadratic_.Reshape(top_shape);
cos_theta_cubic_.Reshape(top_shape);
sign_1_.Reshape(top_shape);
sign_2_.Reshape(top_shape);
break;
case MarginInnerProductParameter_MarginType_QUADRUPLE:
cos_theta_quadratic_.Reshape(top_shape);
cos_theta_cubic_.Reshape(top_shape);
cos_theta_quartic_.Reshape(top_shape);
sign_3_.Reshape(top_shape);
sign_4_.Reshape(top_shape);
break;
default:
LOG(FATAL) << "Unknown margin type.";
}
}
template <typename Dtype>
void MarginInnerProductLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
iter_ += (Dtype)1.;
Dtype base_ = this->layer_param_.margin_inner_product_param().base();
Dtype gamma_ = this->layer_param_.margin_inner_product_param().gamma();
Dtype power_ = this->layer_param_.margin_inner_product_param().power();
Dtype lambda_min_ = this->layer_param_.margin_inner_product_param().lambda_min();
// 公式计算对应的lambda_,可以帮助网络收敛(从大到小变化)
lambda_ = base_ * pow(((Dtype)1. + gamma_ * iter_), -power_);
lambda_ = std::max(lambda_, lambda_min_);
top[1]->mutable_cpu_data()[0] = lambda_;
/************************* normalize weight *************************/
// 对权重进行预处理,即除以均方根(归一化权重)
Dtype* norm_weight = this->blobs_[0]->mutable_cpu_data();
Dtype temp_norm = (Dtype)0.;
for (int i = 0; i < N_; i++) {
temp_norm = caffe_cpu_dot(K_, norm_weight + i * K_, norm_weight + i * K_);
temp_norm = (Dtype)1./sqrt(temp_norm);
caffe_scal(K_, temp_norm, norm_weight + i * K_);
}
/************************* common variables *************************/
// x_norm_ = |x| // 计算输入数据的模
const Dtype* bottom_data = bottom[0]->cpu_data();
const Dtype* weight = this->blobs_[0]->cpu_data();
Dtype* mutable_x_norm_data = x_norm_.mutable_cpu_data();
for (int i = 0; i < M_; i++) {
mutable_x_norm_data[i] = sqrt(caffe_cpu_dot(K_, bottom_data + i * K_, bottom_data + i * K_));
}
// cos_theta = x'w/|x| // 计算 cos 值
Dtype* mutable_cos_theta_data = cos_theta_.mutable_cpu_data();
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasTrans, M_, N_, K_, (Dtype)1.,
bottom_data, weight, (Dtype)0., mutable_cos_theta_data); // 该公式计算x'w(矩阵惩罚)
for (int i = 0; i < M_; i++) {
caffe_scal(N_, (Dtype)1./mutable_x_norm_data[i], mutable_cos_theta_data + i * N_);
}
// sign_0 = sign(cos_theta) // 正负号函数,输出-1、0、1
caffe_cpu_sign(M_ * N_, cos_theta_.cpu_data(), sign_0_.mutable_cpu_data());
/************************* optional variables *************************/
switch (type_) {
case MarginInnerProductParameter_MarginType_SINGLE:
break;
case MarginInnerProductParameter_MarginType_DOUBLE:
// cos_theta_quadratic
caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)2., cos_theta_quadratic_.mutable_cpu_data()); // cos的平方
break;
case MarginInnerProductParameter_MarginType_TRIPLE:
// cos_theta_quadratic && cos_theta_cubic
caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)2., // cos的平方 cos_theta_quadratic_.mutable_cpu_data());
caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)3., // cos的立方 cos_theta_cubic_.mutable_cpu_data());
// sign_1 = sign(abs(cos_theta) - 0.5)
caffe_abs(M_ * N_, cos_theta_.cpu_data(), sign_1_.mutable_cpu_data()); // cos_theta_绝对值
caffe_add_scalar(M_ * N_, -(Dtype)0.5, sign_1_.mutable_cpu_data()); // -0.5
caffe_cpu_sign(M_ * N_, sign_1_.cpu_data(), sign_1_.mutable_cpu_data()); // 正负号函数,输出-1、0、1
// sign_2 = sign_0 * (1 + sign_1) - 2
caffe_copy(M_ * N_, sign_1_.cpu_data(), sign_2_.mutable_cpu_data());
caffe_add_scalar(M_ * N_, (Dtype)1., sign_2_.mutable_cpu_data());
caffe_mul(M_ * N_, sign_0_.cpu_data(), sign_2_.cpu_data(), sign_2_.mutable_cpu_data());
caffe_add_scalar(M_ * N_, - (Dtype)2., sign_2_.mutable_cpu_data());
break;
case MarginInnerProductParameter_MarginType_QUADRUPLE:
// cos_theta_quadratic && cos_theta_cubic && cos_theta_quartic
caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)2., // cos 的平方 cos_theta_quadratic_.mutable_cpu_data());
caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)3., // cos 的立方 cos_theta_cubic_.mutable_cpu_data());
caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)4., // cos 的四次方 cos_theta_quartic_.mutable_cpu_data());
// sign_3 = sign_0 * sign(2 * cos_theta_quadratic_ - 1)
caffe_copy(M_ * N_, cos_theta_quadratic_.cpu_data(), sign_3_.mutable_cpu_data());
caffe_scal(M_ * N_, (Dtype)2., sign_3_.mutable_cpu_data());
caffe_add_scalar(M_ * N_, (Dtype)-1., sign_3_.mutable_cpu_data());
caffe_cpu_sign(M_ * N_, sign_3_.cpu_data(), sign_3_.mutable_cpu_data());
caffe_mul(M_ * N_, sign_0_.cpu_data(), sign_3_.cpu_data(), sign_3_.mutable_cpu_data());
// sign_4 = 2 * sign_0 + sign_3 - 3
caffe_copy(M_ * N_, sign_0_.cpu_data(), sign_4_.mutable_cpu_data());
caffe_scal(M_ * N_, (Dtype)2., sign_4_.mutable_cpu_data());
caffe_add(M_ * N_, sign_4_.cpu_data(), sign_3_.cpu_data(), sign_4_.mutable_cpu_data());
caffe_add_scalar(M_ * N_, - (Dtype)3., sign_4_.mutable_cpu_data());
break;
default:
LOG(FATAL) << "Unknown margin type.";
}
/************************* Forward *************************/
Dtype* top_data = top[0]->mutable_cpu_data();
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasTrans, M_, N_, K_, (Dtype)1.,
bottom_data, weight, (Dtype)0., top_data); // 计算所有||x||*cos值
const Dtype* label = bottom[1]->cpu_data();
const Dtype* x_norm_data = x_norm_.cpu_data();
switch (type_) {
case MarginInnerProductParameter_MarginType_SINGLE: {
break; // 如果为SINGLE,之前算法已满足要求
}
case MarginInnerProductParameter_MarginType_DOUBLE: {
const Dtype* sign_0_data = sign_0_.cpu_data();
const Dtype* cos_theta_quadratic_data = cos_theta_quadratic_.cpu_data();
// the label[i]_th top_data
for (int i = 0; i < M_; i++) {
const int label_value = static_cast<int>(label[i]);
// |x| * (2 * sign_0 * cos_theta_quadratic - 1)
top_data[i * N_ + label_value] = x_norm_data[i] * ((Dtype)2. * sign_0_data[i * N_ + label_value] *
cos_theta_quadratic_data[i * N_ + label_value] - (Dtype)1.); // 改变对应label的参数,cos2theta.\cos 2\theta &= 2\cos^2 \theta -1
}
// + lambda * x'w
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasTrans, M_, N_, K_, lambda_,
bottom_data, weight, (Dtype)1., top_data);
// * 1 / (1 + lambda)
caffe_scal(M_ * N_, (Dtype)1./((Dtype)1. + lambda_), top_data);
break;
}
case MarginInnerProductParameter_MarginType_TRIPLE: {
const Dtype* sign_1_data = sign_1_.cpu_data();
const Dtype* sign_2_data = sign_2_.cpu_data();
const Dtype* cos_theta_data = cos_theta_.cpu_data();
const Dtype* cos_theta_cubic_data = cos_theta_cubic_.cpu_data();
// the label[i]_th output
for (int i = 0; i < M_; i++) {
const int label_value = static_cast<int>(label[i]);
// |x| * (sign_1 * (4 * cos_theta_cubic - 3 * cos_theta) + sign_2)
top_data[i * N_ + label_value] = x_norm_data[i] * (sign_1_data[i * N_ + label_value] *
((Dtype)4. * cos_theta_cubic_data[i * N_ + label_value] -
(Dtype)3. * cos_theta_data[i * N_ + label_value]) +
sign_2_data[i * N_ + label_value]);
}
// + lambda * x'w
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasTrans, M_, N_, K_, lambda_,
bottom_data, weight, (Dtype)1., top_data);
// / (1 + lambda)
caffe_scal(M_ * N_, (Dtype)1./((Dtype)1. + lambda_), top_data);
break;
}
case MarginInnerProductParameter_MarginType_QUADRUPLE: {
const Dtype* sign_3_data = sign_3_.cpu_data();
const Dtype* sign_4_data = sign_4_.cpu_data();
const Dtype* cos_theta_quadratic_data = cos_theta_quadratic_.cpu_data();
const Dtype* cos_theta_quartic_data = cos_theta_quartic_.cpu_data();
// the label[i]_th output
for (int i = 0; i < M_; i++) {
const int label_value = static_cast<int>(label[i]);
// // |x| * (sign_3 * (8 * cos_theta_quartic - 8 * cos_theta_quadratic + 1) + sign_4)
top_data[i * N_ + label_value] = x_norm_data[i] * (sign_3_data[i * N_ + label_value] *
((Dtype)8. * cos_theta_quartic_data[i * N_ + label_value] -
(Dtype)8. * cos_theta_quadratic_data[i * N_ + label_value] +
(Dtype)1.) + sign_4_data[i * N_ + label_value]);
}
// + lambda * x'w
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasTrans, M_, N_, K_, lambda_,
bottom_data, weight, (Dtype)1., top_data);
// / (1 + lambda)
caffe_scal(M_ * N_, (Dtype)1./((Dtype)1. + lambda_), top_data);
break;
}
default: {
LOG(FATAL) << "Unknown margin type.";
}
}
}