文章目录
1.TURN TAP: Temporal Unit Regression Network for Temporal Action Proposals
论文目的——拟解决问题
时间行动建议(TAP)的生成是一个重要的问题,从未经修剪的视频中快速准确地提取语义上重要的(如人类行动)片段是大规模视频分析的一个重要步骤。
①滑窗方法计算效率过低。②现有评估指标不精确。
贡献——创新
-
提出了Temporal Unit Regression Network(TURN)。TURN联合预测动作建议,并通过时间坐标回归来完善时间边界;
-
为候选框提出任务(TAP)提出新的度量标准“平均召回率-检出框频率”(Average Recall vs. Frequency of retrieved proposals, AR-F)
实现流程
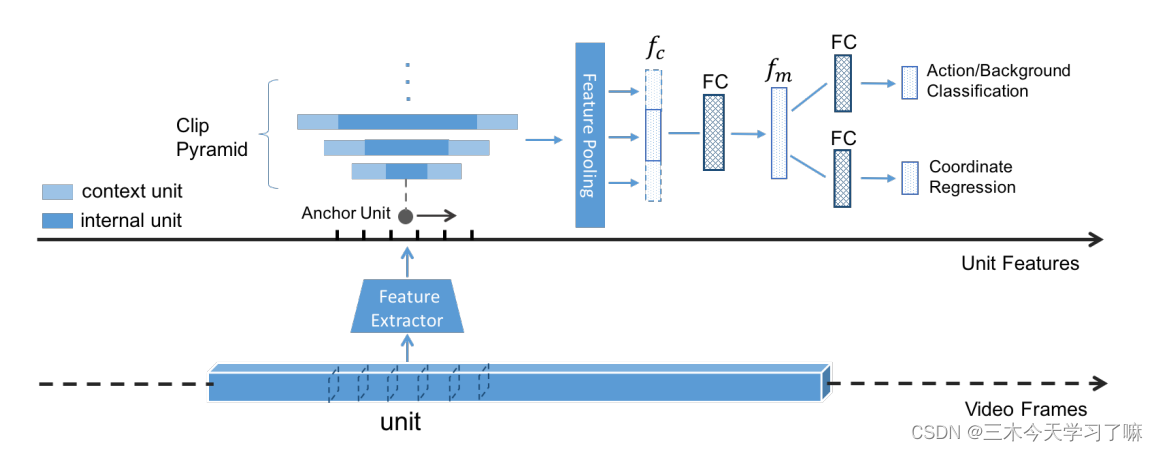
(1)一个长的视频被分解成短的视频单元(6/16/32frames),并为每个单元计算CNN特征(C3D,双流CNN)。
(2)一组连续的特征单元(unit features),称为片段,被汇集起来以创建片段特征。
(3)多个时间尺度被用来在一个Anchor Unit创建一个片段金字塔。
(4)TURN将一个片段作为输入,并输出一个置信度分数,表明它是否是一个动作实例,以及两个回归偏移的开始和结束时间,以细化时间上的动作边界。
详细方法
Video Unit Processing: 为了避免重复提取同一窗口或重叠窗口的视觉特征,我们使用视频单元(video units)作为我们框架中的基本处理单元。
Clip Pyramid Modeling:

公式里的参数在原论文中介绍的很清楚。
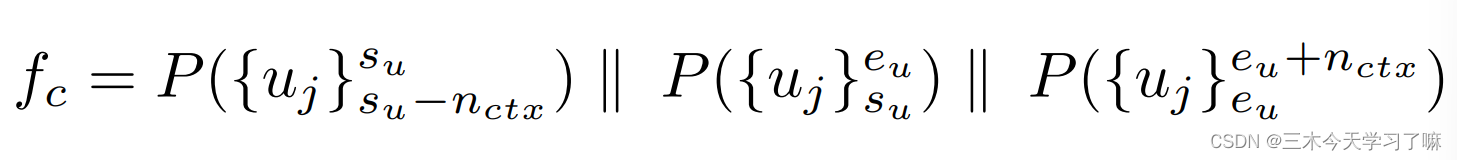
其中||代表矢量串联,P使用的是mean pooling。请注意,尽管多分辨率剪辑会有时间重叠,但剪辑级别的特征是由单元级别的特征计算得到的,而单元级别的特征只计算一次。
Unit-level Temporal Coordinate Regression:
网络包含两个输出:第一个输出confidence score判断clip中是否包含action,第二个输出temporal coordinate regression offsets。回归偏移量由下式表达
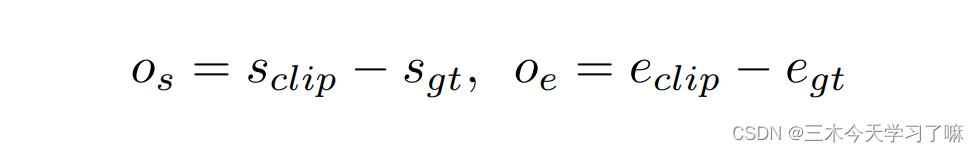
s和e分别表示起始unit和终止unit的位置。
Loss Function:
正样本定义为:(1)与GT的tIoU最大的样本(2)与GT的tIoU大于0.5的样本
负样本定义为:与GT的tIoU为0的样本
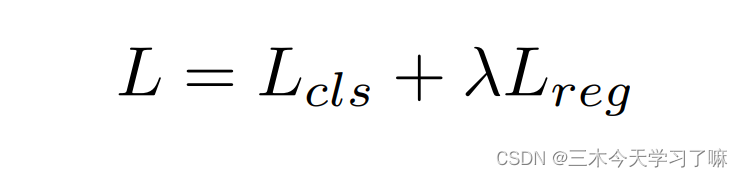
第一项Lcls为分类Loss,用于对action/background做分类,是softmax损失。第二项为回归Loss,用于校正proposal的位置。λ为超参数。
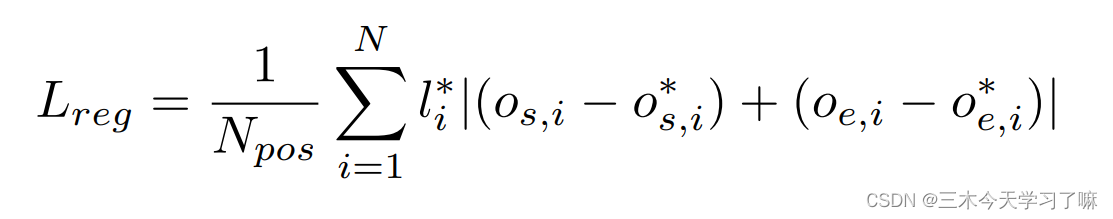
采用L1距离。l∗i是标签,1代表阳性样本,0代表背景样本。
2. Temporal Action Detection with Structured Segment Networks
论文目的——拟解决问题
- 精确时间定位的一个主要挑战是在proposed temporal regions中存在大量不完整的动作片段
- 视频中巨大的视觉数据量限制了他们以端到端方式对长期依赖关系进行建模的能力。
- 既没有对活动中的不同阶段(如开始和结束)进行明确的建模,也没有提供评估完整性的机制。
贡献——创新
- Structured Segment Networks(SSN): 可通过结构化的时间金字塔对每个行为实例的时间结构进行建模。 在金字塔的顶部,进一步使用了一个分解的判别模型,该模型包含两个分类器,分别用于对行为进行分类和确定完整性。 这使框架可以有效地将积极的proposals与背景的或不完整的proposals区分开,从而准确的识别和定位。
- 提出关注动作的开始、进行与结束三个阶段性属性,依此时域结构信息提升候选框所包含动作的完整性,只在proposal与action对齐时显示较高的得分。
- 基于稀疏采样策略(sparse snippet sampling strategy)克服了长期建模的计算问题,实现了高效轻量的端到端模型。
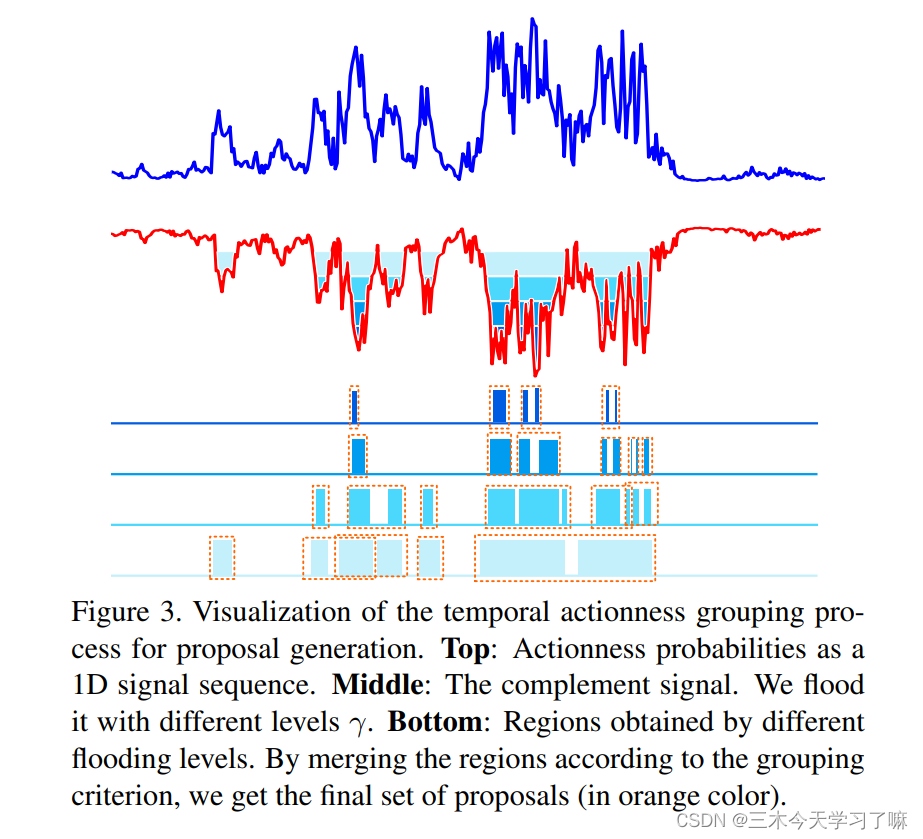
- 提出了基于分水岭(watershed)的候选框提出机制TAG(temporal actionness grouping)。【temporal actionness grouping(TAG):一种简单而有效的时序行动proposal方案,生成高质量的行动proposal。】
具体方法
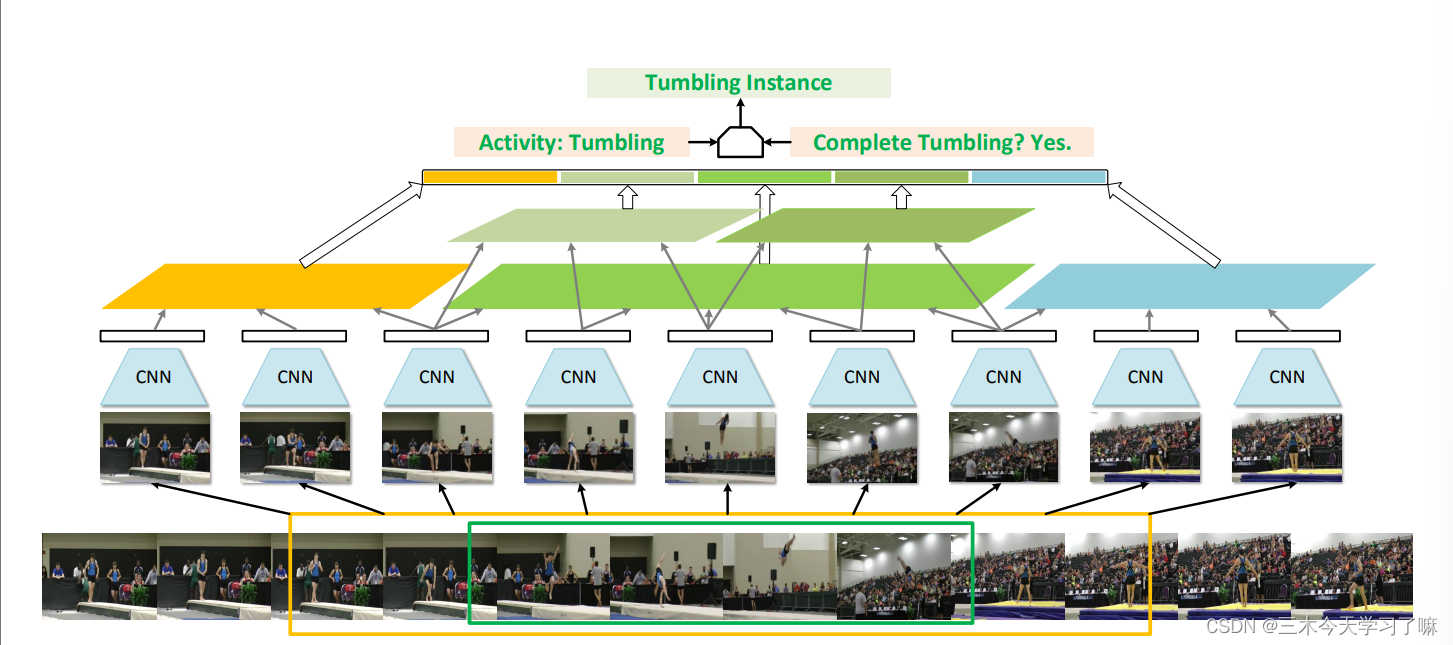
将增强框分为三阶段:开始(黄色特征)、进行(绿色特征)和结束(蓝色特征),使用结构化时序金字塔池化(structured temporal pyramid pooling, STPP)方法对三阶段分别处理,将各阶段STPP得到的特征连结成全局信息后传给动作类别判别器和动作完整性判别器,最终结合两个分类器的结果以输出完整动作实例结果。上述整体均被囊括在一个端到端的模型中进行训练。
详细方法
补充一点:
Location Regression and Multi-Task Loss:


采用稀疏片段采样策略(sparse snippet sampling strategy)降低计算量(此举明显是为了端到端训练且不炸显存的妥协之举):一个候选框(proposal)必然包括很多片段(snippet),实际操作时将任一候选框平均地分成九截(segment),每一截中都会包含几个片段。在SSTP时,在每一截中仅处理其中的一个片段。同时这一行为也固定了SSTP在处理一个候选框后得到的特征维度。
在测试时利用分类器的线性特性和矩阵知识,将矩阵WPool(矩阵V)转换成Pool(矩阵W矩阵V),测试速度提升20倍。
下图中,上为score图,中为反score图,下为TAG算法得到的候选框。用不同阈值得到几组候选框,NMS后输入SSN网络。
3. A Pursuit of Temporal Accuracy in General Activity Detection
论文目的——拟解决问题
- 要分辨一个视频片段是捕捉了整个动作还是其中的一部分是不容易的。这个问题对于基于区域建议的检测方法来说特别突出,因为时间建议和空间建议之间有一个关键区别。
【在图像中,一个物体的外观往往与它的局部部分看起来很不一样。因此,对于一个视觉检测器来说,要分辨一个窗口是对应于整个物体还是只是局部的一部分,通常不是很困难。】
然而,对于视频来说,人们往往可以很容易地从一小段(甚至一帧)中看出动作是什么,但整个动作实际上可能持续得更久。一个动作和其一部分之间的模糊区别使得准确定位起始点和结束点非常困难。 - 动作持续时长分布不一,故基于滑窗的方法常采用更多的窗尺度和更短的步长,造成了计算资源的浪费;同时在长时间跨度上进行卷积计算的代价也过于高昂。
贡献——创新
- 提出自下向上的候选框提出方法TAG(temporal actionness grouping),对边界信息更加敏感,可以产生更准确的候选区域,并可以处理广泛的动作长度。
- 行动性和完整性在本质上是不同的特征,因此设计了一个有两步的级联分类网络。第一步删除那些属于背景的动作,而第二步,我们称之为完整性分类,专门用来识别那些只捕捉到动作的不完整部分的候选动作,并将它们从结果中剔除。
实现流程
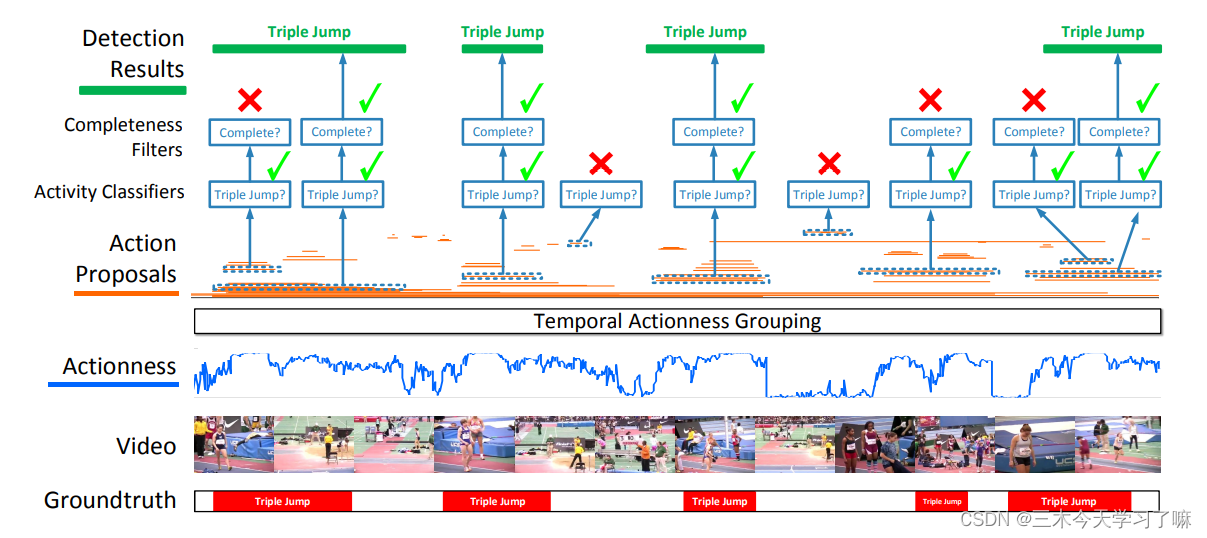
拟议的动作检测框架从评估视频snippet的动作性开始。使用TAG(temporal actionness grouping)生成temporal action proposals(橙色)。这些级联分类器针对proposals进行评估,以验证其相关性和完整性。只有三级跳的完整实例的建议才由框架产生。非完整的提议和背景提议被框架拒绝的。
详细方法
Framework Overview:
proposed framework包括两个阶段:生成temporal proposals和分类proposed candidates。前者是为了产生一组可能反映感兴趣的动作的、与类别无关的时间区域,而后者是为了确定每个候选区域是否真的对应于一个动作以及它属于哪个类别。(挑战和贡献都在前面)
Temporal Region Proposals:
候选框生成作为一个自底向上的流程,主要分为三个步骤:提取片段,评估每个片段的动作得分,将片段聚类(grouping)成候选框。
(1)提取片段:,每个片段都结合了一个视频帧和一个由此产生的光流。不仅传达了特定时间步长的场景外观,还传达了当时的运动信息。
(2)评估动作得分:动作得分不在乎类别,只衡量视频片段内含有动作的概率,采用TSN(Temporal Segment Network)的网络结构训练了一个双流二分类分类器以实现功能。将有动作标记的片段置为正样本,无动作标记的背景置为负样本,调节数据比例为1:1。
(3)grouping:为了实现对噪声的鲁棒性,需要模型能忍受偶尔的离群值(eg动作内部短暂的低置信度片段)。

如上图所示进行聚类算法,首先设计一个动作阈值以得到较为确定是动作的片段,向后延展此步得到的片段;再设计一个容忍阈值以判断哪些片段定不是动作,在延展过程中遇到低于容忍阈值的片段即暂停延展。
Detecting Action Instances:
有了一组候选的时间区域,下一阶段就是要从中找出完整的动作实例,并将它们分类到特定的动作类别中。
候选框筛选主要分两步,先在判断候选框动作类别的同时筛选掉背景框,再基于特定动作的完整性筛选掉不完整的框。
①Activity Classification:
采用TSN提出的分类器,与特定动作IOU大于0.7的候选框视作正样本,与任意动作标注占比时长小于5%的候选框视作负样本,其背后隐含的道理是:那些小IOU但着实与GT有交集的候选框可能包含显著的动作片段,容易混淆判别器。这种策略可以帮助分类器更关注候选框是前景还是背景。
在测试时,先处理视频,对每一个片段进行动作类别判断,再把结果聚合到region-level来判断一个候选框是什么动作/背景。
②Completeness Filtering:
判断动作是否完整不能只看动作内部信息,还应该关注候选框内部不同部分的区别、候选框前后的视频信息。论文中搭建了如下模型以判断动作完整性:
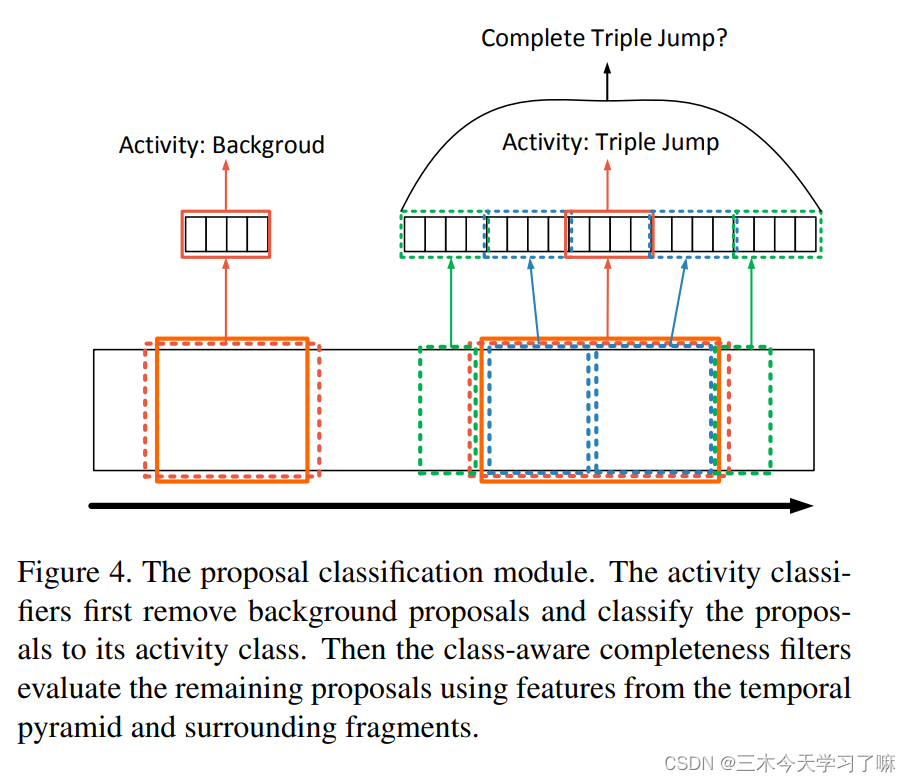
一个双层金字塔结构:第一层对整个候选框内各片段(snippet)得分进行池化,如图深棕色;第二层对1/2候选框内各片段(snippet)得分进行池化,如图蓝色。前后片段的动作平均得分,如图绿色。论文中为每个动作训练了一个SVM分类器,逐个进行判断。(尽管现在看来,这种提特征的方式很简单甚至拙劣,但是金字塔结构、利用前后视频信息组成整体特征、利用分类器判断的思路还在一直延续被使用)
设判断动作类别的分类器给出置信度P,动作完整性得分为S,候选框的最终得分C= P * epx(S_c)。
其中Pa是活动分类器的概率,Sc是完整性得分。这一表述表明,检测结果的最终可信度是其类别概率和完整性分数的组合。