文章目录
上一篇:【论文阅读】时序动作检测系列论文精读(2017年 上)
4. Cascaded Boundary Regression for Temporal Action Detection
论文目的——拟解决问题
- 滑窗得到的proposal可能包含动作中具有显著特征的部分,但可能无法包含完整动作。
贡献——创新
- 提出了一种新型的两阶段动作检测网络,采用Cascaded Boundary Regression(CBR)进行级联式的渐进边界回归。
实现流程
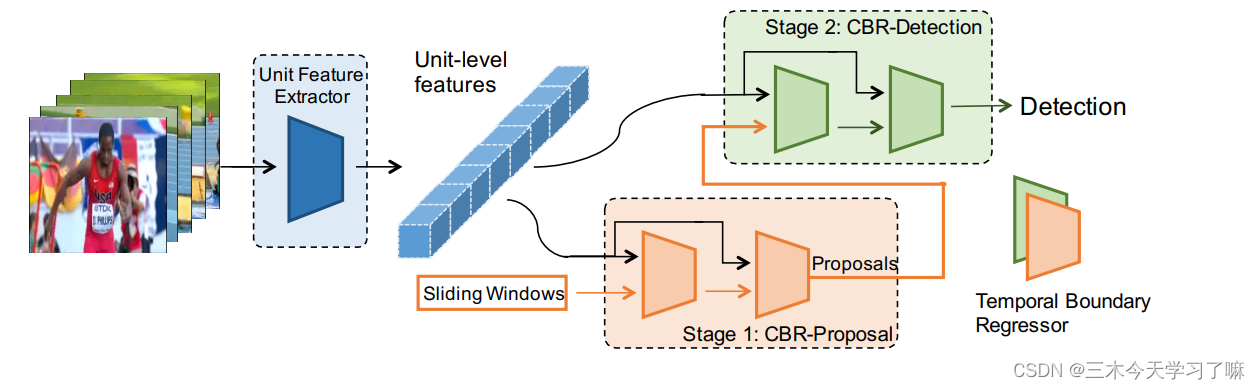
提出two-stage的CBR网络,输入动作片段snippet,一阶段的proposal网络输出对边界回归(开始/结束时刻)的offset和该片段的动作得分(无视动作类别),若得分高于阈值,将校正后的片段输入二阶段的detection网络,输出n+1类动作下的具体动作得分和n类动作对应的boundary offset。两阶段内均对候选框的边界进行串联的渐进回归。
详细方法
-
Feature Extraction:
将视频裁剪成多个不重叠的单元(unit),采用C3D和双流网络进行对应片段的特征提取。一个片段(clip)由多个unit组成,这些unit称为内部单元(internal unit);clip前后的、用于边界回归的unit被称为语义单元(context unit), 这对时间边界推断很重要。内部特征、语义特征通过均值汇集操作P分别从单元级特征中汇集出来。

其中||代表矢量串联(concatenation)。通过多尺度的时间滑动窗口来扫描视频。时间滑动窗口由两个参数来模拟:窗口长度l_i和窗口重叠o_i。请注意,虽然多尺度的片段会有时间上的重叠,但片段级的特征是由单位级的特征计算出来的,而单位级的特征只计算一次。 -
Temporal Coordinate Regression:
对于边界回归,以往的工作主要使用参数化的坐标偏移量(parameterized coordinates offsets),即先对候选框的中心位置和长度进行参数化(由此可推导得到候选框边界坐标),再基于中心和长度坐标表示具体的偏移量。例如
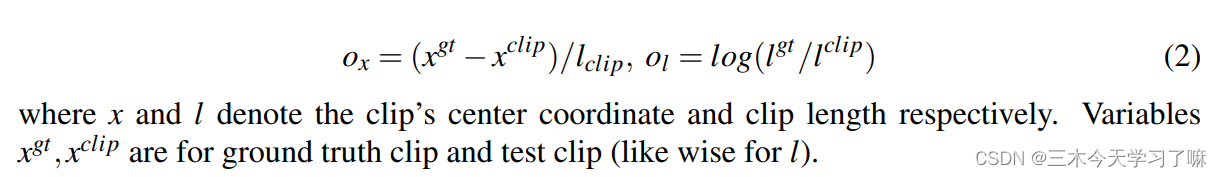
本文的思路是直接进行具体坐标的回归。由于GT的标注单位常常是秒,故先乘以FPS计算得到开始/结束时刻对应帧,再通过unit长度和取整操作确定开始/结束时刻对应的unit索引,随后进行精细的坐标回归:
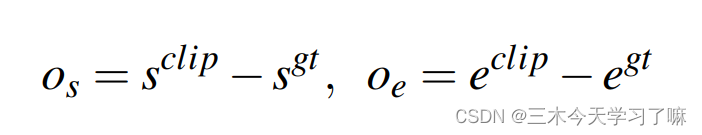
s_clip和e_clip既可以是unit-level标注,也可对应frame-level标注,论文最后选用前者。unit-level坐标回归背后的直觉是,由于基本的unit-level feature被提取来编码Nu帧,该特征可能没有足够的辨别力来回归帧级的坐标。与帧级回归相比,单元级坐标回归更容易学习,尽管其边界更粗略。 -
Two-Stage Proposal and Detection Pipeline:
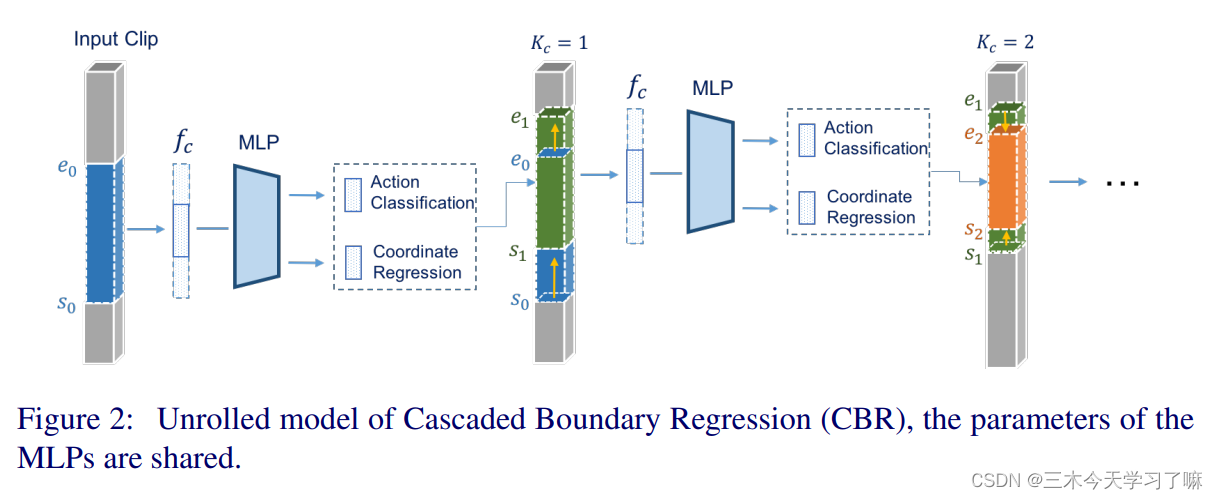
在proposal和detection的两个阶段中,边界回归都是以级联的方式进行的:输出的边界作为反馈再输回网络进行进一步的校正。(迭代的思想)如图所示,每个校正流程由K次回归构成,最终的框是K次校正的结果,最终的动作得分也是K次得分的乘积。两阶段的网络是分开训练的,但每一阶段内出于简便性考量共享了网络参数。
Loss Function:
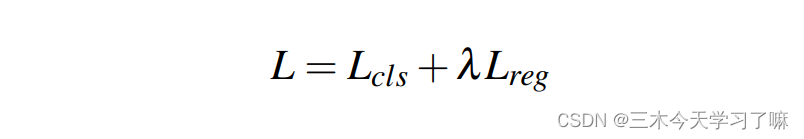
其中L_cls是分类的损失,是标准的交叉熵损失。对于proposal网络,L_cls是二元分类交叉熵损失;对于检测网络,L_cls是标准的多类交叉熵损失。 L_reg是用于时间坐标回归,λ是一个超参数,根据经验设定。回归损失为:

实验结果表明,坐标的直接回归优于参数化后的回归(作者认为这是因为视频时长不像图像中的目标一样可以随意放缩);基于unit-level的回归优于基于frame-level的回归(作者认为frame-level的坐标可能包含了不必要的信息);使用双流网络提取的特征作为输入优于C3D网络。
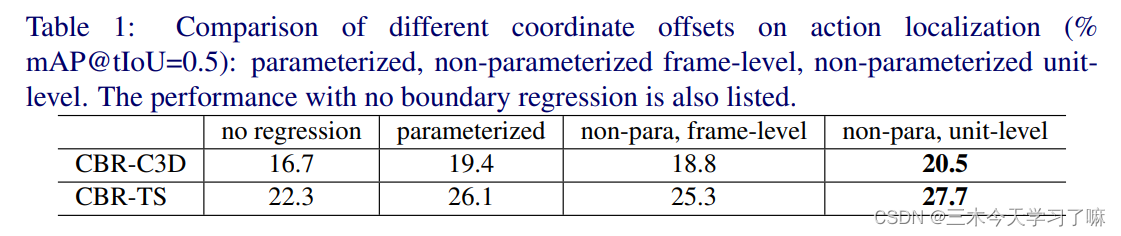
同时,对于CBR模块的内部回归次数,不同阶段、不同特征,其最优值是不同的,且不是越多越好的。但实验也表明了一些缺陷,对于不同数据集,滑窗的尺度、CBR内部回归次数等参数均需手动调整。
手工特征太明显了,并且网络对不同数据集的泛化性很差。



5. R-C3D: Region Convolutional 3D Network for Temporal Activity Detection
论文目的——拟解决问题
- 目前的方法依赖于外部proposal的生成或详尽的滑动窗口(Temporal Aaction Proposal),导致计算效率低下。
- VGG、ResNet、C3D等深度特征,在图像/视频分类任务中单独学习。这种现成的表征对于在不同的视频领域中定位活动可能不是最理想的,从而导致性能低下。(即迁移效果差)
贡献——创新
- 一个端到端的3D区域卷积网络模型(Region Convolutional 3D Network, R-C3D),它结合了候选框生成和分类阶段,可以检测任意长度的活动;
- 通过在网络的候选框生成和分类部分之间共享完全卷积的C3D特征来实现快速的检测速度(比目前的方法快5倍);
总体来说,作者认为TAP(Temporal Aaction Proposal)和分类不应分开,故设立一个端到端网络同时学习两部分知识;作者认为2D卷积的特征提取法缺少时序信息,故采用3D卷积希望学到新的联系。
实现流程
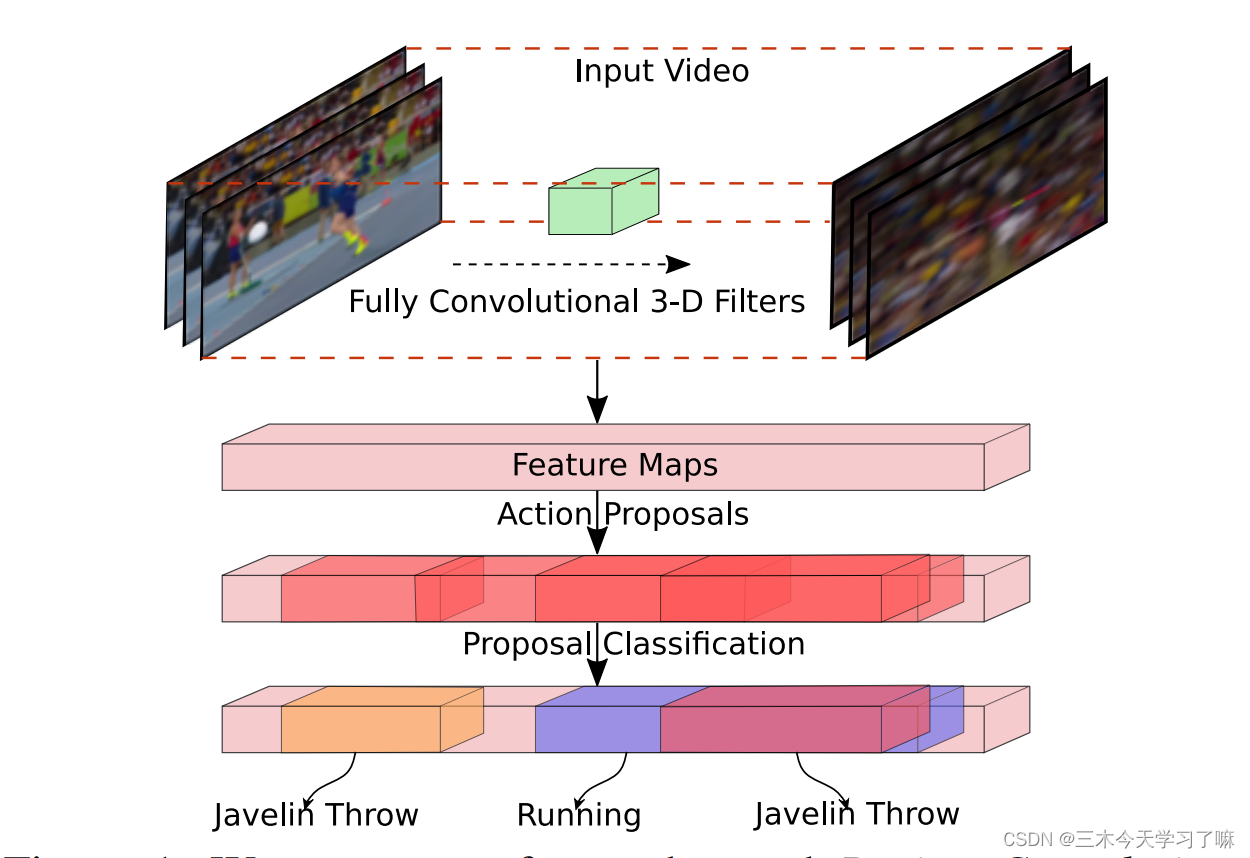
该网络用完全卷积的三维滤波器对帧进行编码,提出活动候选框,然后根据其边界内的集合特征对其进行分类和细化。
详细方法
如下图所示,主要具体分为三个部分:3D卷积特征提取模块,候选框生成模块、动作框校正与分类模块。
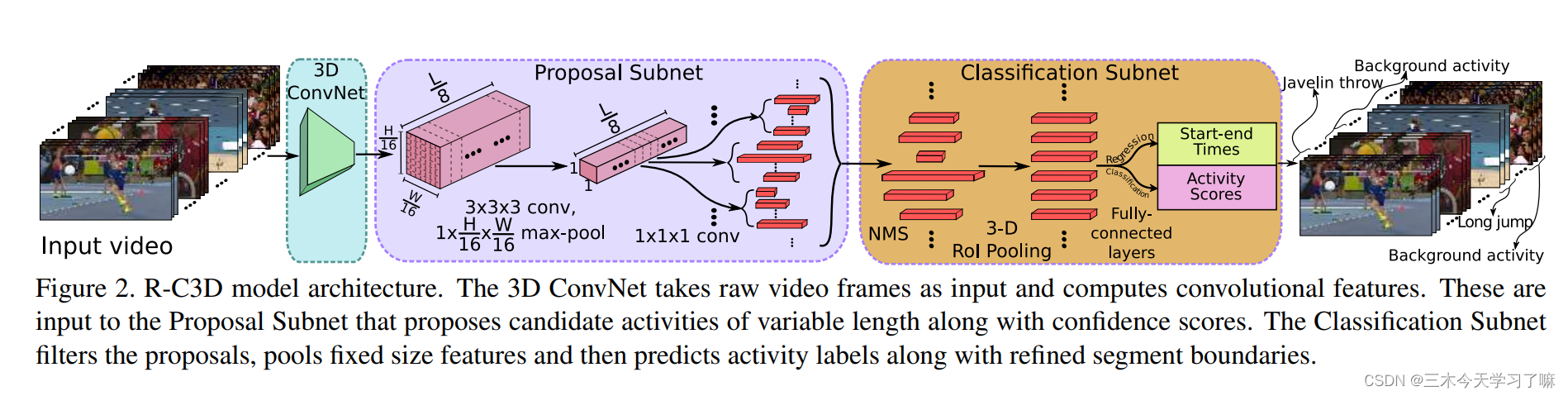
Temporal Proposal Subnet:
- 对于3* L* H* W维度的视频输入,将其通过C3D提出的3D ConvNet网络的卷积层(conv1a-conv5b),得到512*(L/8)* (H/16)* (W/16)维度的输出。其中输入视频时长L只取决于内存。
- 在Proposal Subnet部分基于anchor思路生成候选框。具体为,对512*(L/8)* (H/16)* (W/16)维度的输入,过一个3* 3* 3的3D卷积层和一个1*(H/16)* (W/16)的3D最大池化层,得到512* (L/8)* 1* 1维度的输出,再在每个时间点采用K个pre-defined的anchor,最终得到(L/8) *K个512维的候选片段。
- 将IoU>0.7或最大IoU的片段标注为包含动作的正样本,将IoU小于0.3的片段标注为背景负样本,选取1:1的正负样本进行训练。
Activity Classification Subnet:
-
在Classification Subnet部分,先对上一步得到的片段进行greedy NMS操作;
-
随后对得到的任意长的片段进行3DRoI池化操作 (近似Faster R-CNN,将任意维度的输入切块、池化以得到特定维度的输出,具体输入为3D ConvNet在特定片段区域下的特征)。
-
最后在特定大小的特征后接全连接层,分别进行类别判断和边界回归。
-
将IoU>0.5或最大IoU的片段标记其动作类别,将IoU小于0.5的片段标记为背景负样本,选取1:3的正负样本进行训练
Optimization:
- 分类时采用softmax损失函数,边界回归采用Smooth L1损失函数,二者联合进行优化。其中边界回归的输入指向anchor框与ground truth框在中心位置和持续时长的差异。
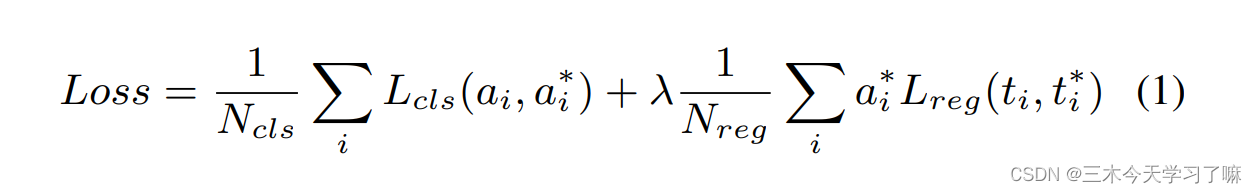
λ是损失权衡参数,设置为1值。上述损失函数同时适用于时间性提议子网和活动分类子网。
在Temporal Proposal Subnet中,二元分类损失L-cls预测提议是否包含活动,而回归损失L-reg则优化候选框和ground truth之间的相对位移。损失是与活动类别无关的。
对于Activity Classification Subnet,多类分类损失L-cls预测了候选框的具体活动类别,而类别的数量是活动的数量加上背景的数量。回归损失L-reg优化了活动和ground truth之间的相对位移。两个子网的所有四个损失都是联合优化的。
补充:
注意两个subnet的边界回归结果均使用的是中心和长度的相对位置形式,为了得到真实的起止时间,需要使用前文所述的的坐标转换公式的反变换。

6. Single Shot Temporal Action Detection
论文目的——拟解决问题
- 现有的模型,检测网络和识别网络需要分开训练,理想情况是可以进行联合训练得到最优模型。
- 检测网络生成proposal需要额外的计算时间。
- 使用滑窗生成的proposal边界通常都不够精确,并且滑窗方法需要事先确定窗口大小,只能处理固定长度的片段,不能灵活应用于变长片段。
贡献——创新
- 论文中提出的Single Shot Action Detector (SSAD)网络,为了更好地编码视频中的空间和时间信息,采用多个动作识别模型(动作分类器)来提取多粒度的特征。
- SSAD网络是one-stage的网络,不需要先生成预测proposal,直接预测动作的时序边界以及置信度。
实现流程
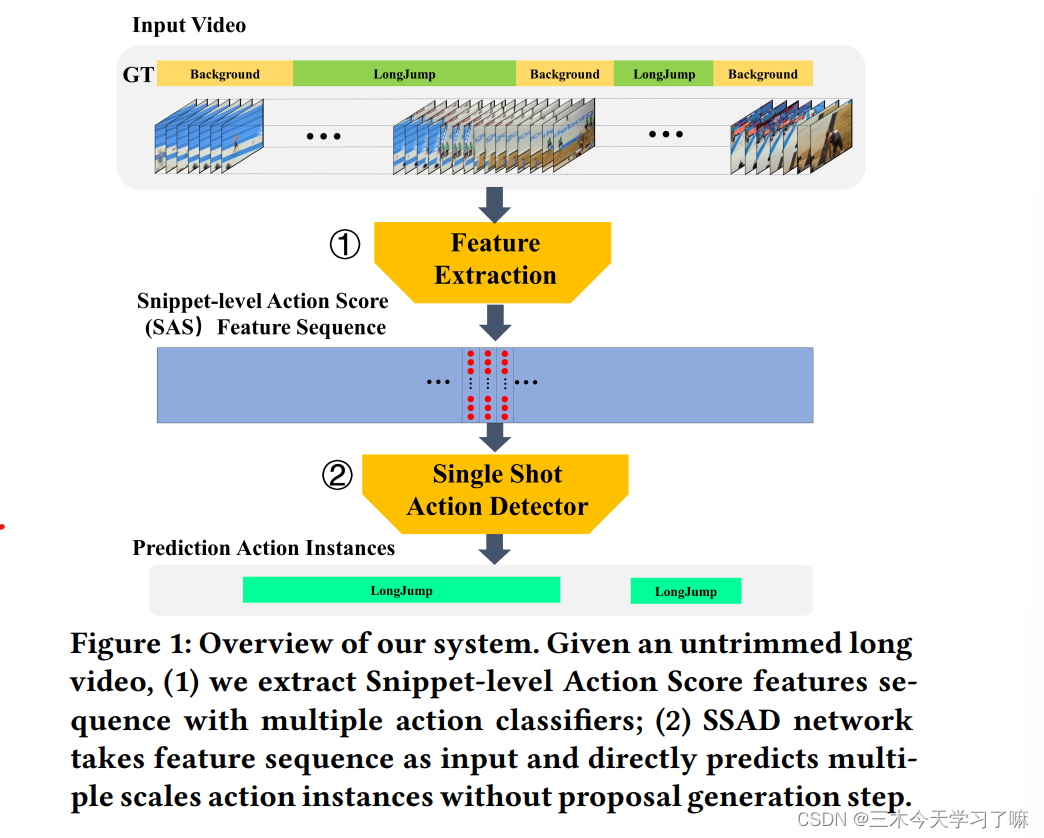
给定未裁剪的长视频,通过多个动作分类器提取片段级的动作得分(Snippet-level Action Score,SAS)特征序列,将特征输入SSAD网络并直接输出多尺寸的动作实例(起始时刻+类别)。
详细方法
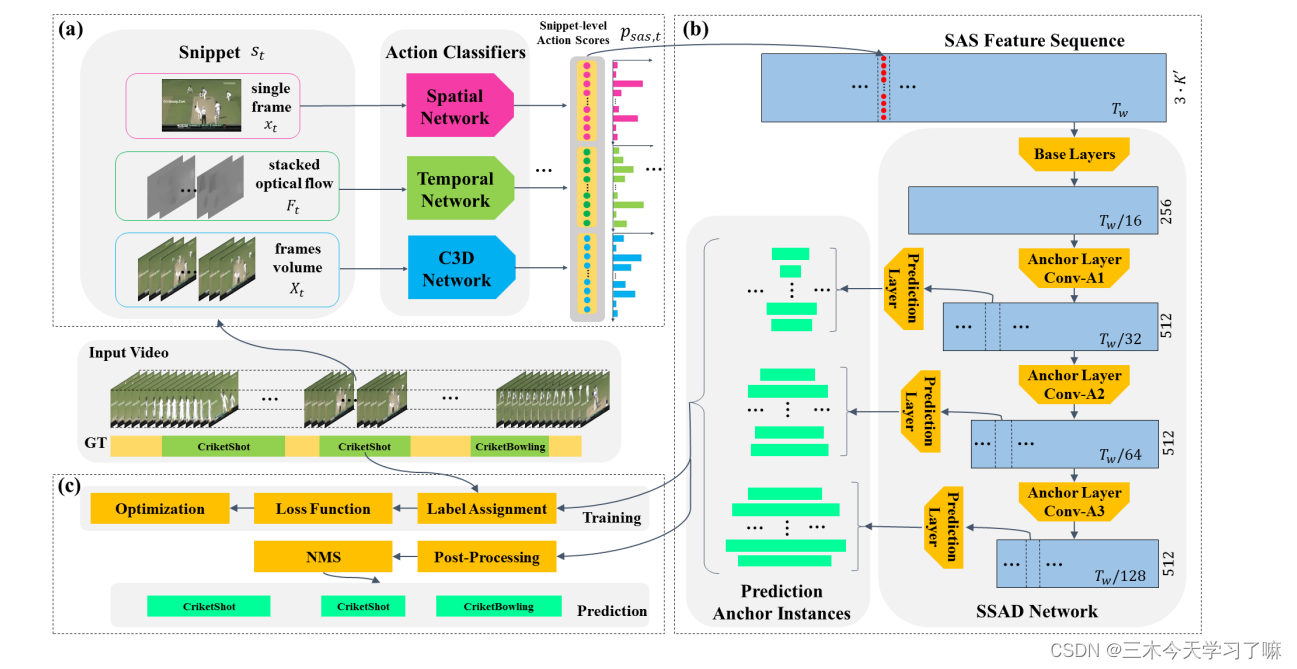
(a)特征提取:
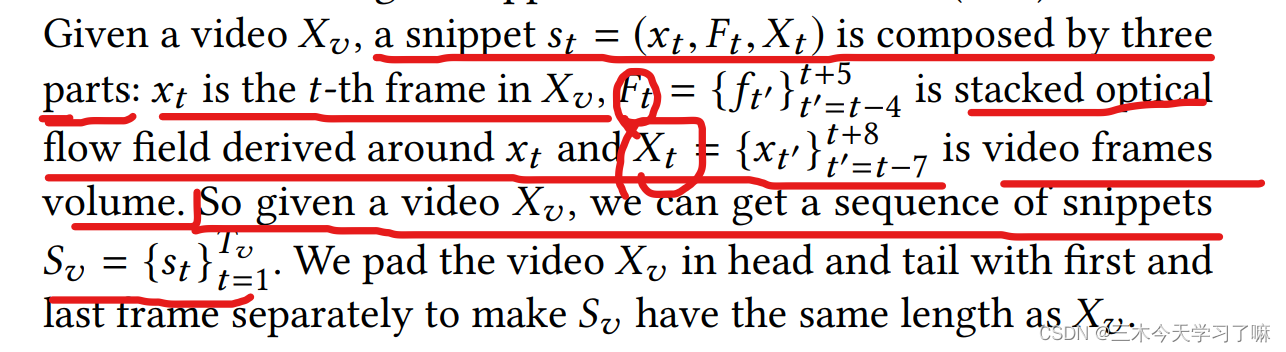
对于不同长度视频,先用特定长度窗口截得等长视频,再将其转为片段(snippet)。第t个片段包括第t帧的图像信息,以第t帧为中心的8帧的光流信息,以第t帧为中心的16帧的视频信息。(对等长视频进行padding操作使snippet个数与等长视频帧数相同)
随后以多个动作分类模型 (双流网络的空间流和时间流、C3D网络) 去提取多粒度的特征,第t帧及对应光流信息进双流网络的Spatial和Temporal分支,连续的视频信息进C3D网络。对每个片段,三个独立的分类器都给出了该片段对应K+1类的概率(K类动作+背景),随后对结果进行简单的concatenate操作构建SAS特征(Snippet-level Action Score)。对一段时长为T的视频,提取后的特征大小是是T* 3* (K+1)。
(b)SSAD网络包含三个子模块:
(1) Base layers 的作用为缩短特征序列的长度,并增大特征序列中每个位置的感受野
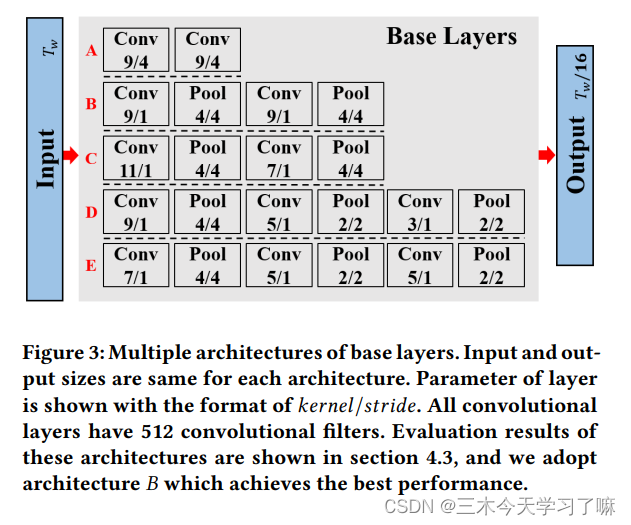
在base layer中,连续进行两次conv(9/1)+pool(4/4)操作,输出(T/16)*256大小的特征;
(2)Anchor layer渐进地降低特征维度,从而使网络在多尺度上进行预测。
锚层的输出锚点特征图尺寸分别为(Tw /32 × 512)、(Tw /64 × 512)和(Tw /128 × 512)。多个锚层逐渐减少了特征图的时间维度,使SSAD能够从多分辨率的特征图中获得预测结果。
下层锚点特征图比上层锚点特征图具有更高的分辨率和更小的感受野。所以我们让下层锚层检测短动作实例,上层锚层检测长动作实例。
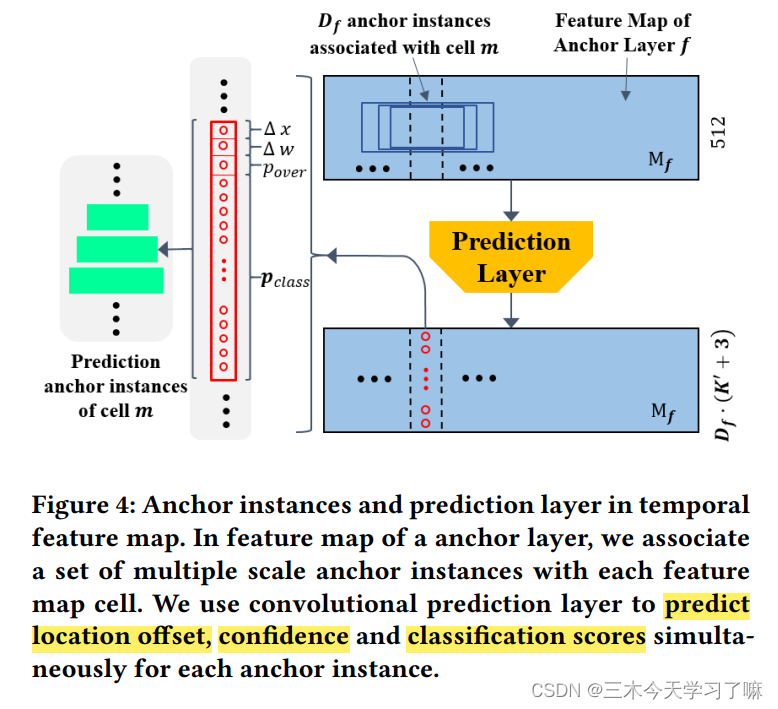
(3)预测层生成这些锚定动作实例的类别概率、位置偏移和重叠分数。
(c)训练和预测:
训练: SSAD网络的训练目标是解决一个多任务优化问题。总体损失函数包括以下几个部分,基于softmax的动作分类损失、基于MSE的overlap损失、基于Smooth L1的边界回归损失和L2正则损失,其中overlap是为了进行后续的NMS操作;
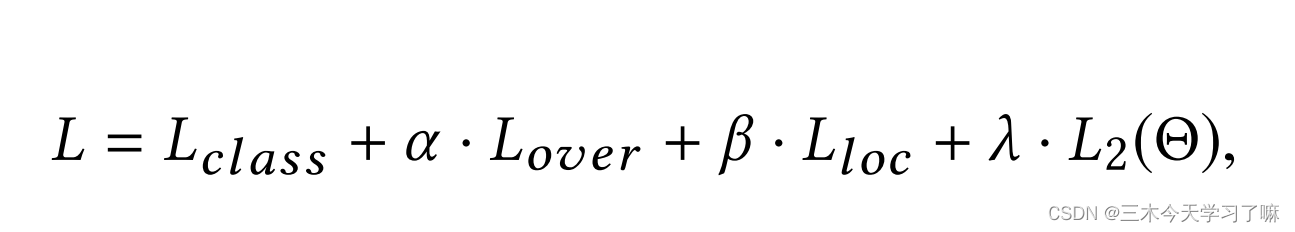
预测和后处理: 沿用前述训练过程中的数据准备方法来准备测试数据,但有以下两点变化:(1)窗口的重叠率降低到25%,以提高预测速度,减少冗余预测;(2)在预测过程中,不删除没有注释的窗口,而是保留所有窗口,因为删除操作实际上是注释信息的泄露。
在获得了一段视频所有的预测action instance后,本文采用NMS(非极大化抑制)对重叠的预测进行去重。从而获得最终的temporal action detection结果。
Feature encoding methods such as Fisher Vector [38] and VAE [24] are widely used
in action recognition task to improve performance.
诸如Fisher Vector[38]和VAE[24]等特征编码方法被广泛用于动作识别任务中,以提高性能。未来我需要学习的地方