CNN中使用注意力机制是一个有效的提高网络性能的方法,它的核心重点就是让网络关注到它更需要关注的地方。我们使用注意力机制让网络可以自适应地关注某些区域,主要的实现就是加权值,我们的代码也是通过给通道或像素加权值实现注意力机制。
一般而言,注意力机制分为通道注意力和空间注意力,或者将两者结合使用。
一、通道注意力
CNN中的特征图往往包含宽(W)、高(H)和通道数(C)。如下图所示:
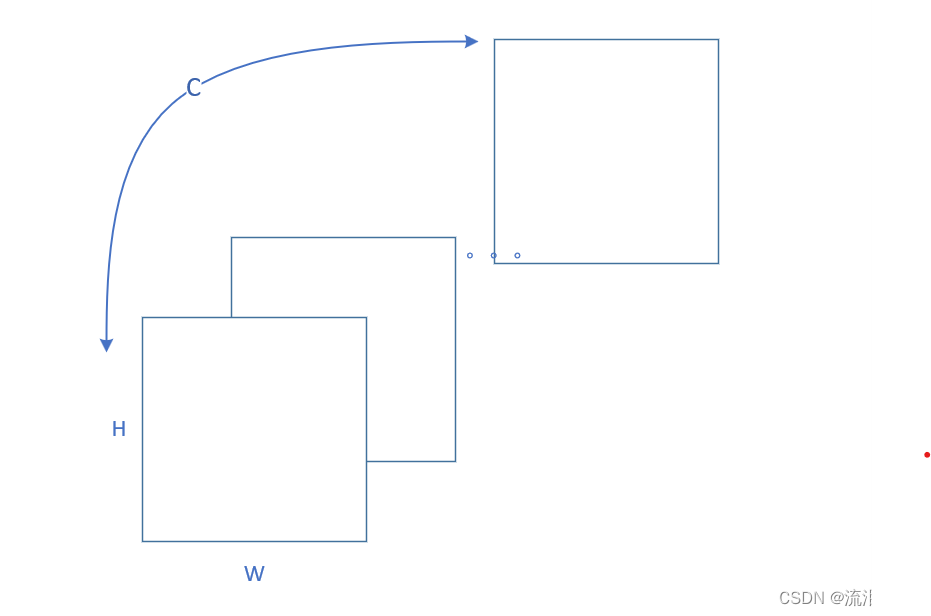
不同通道提取不同的特征信息,比如第一个通道提取水平特征,第二个特征提取垂直特征等。假如我们的任务比较关注垂直特征,则需要给第二个通道附更高的权值,来放大这个特征。
二、空间注意力
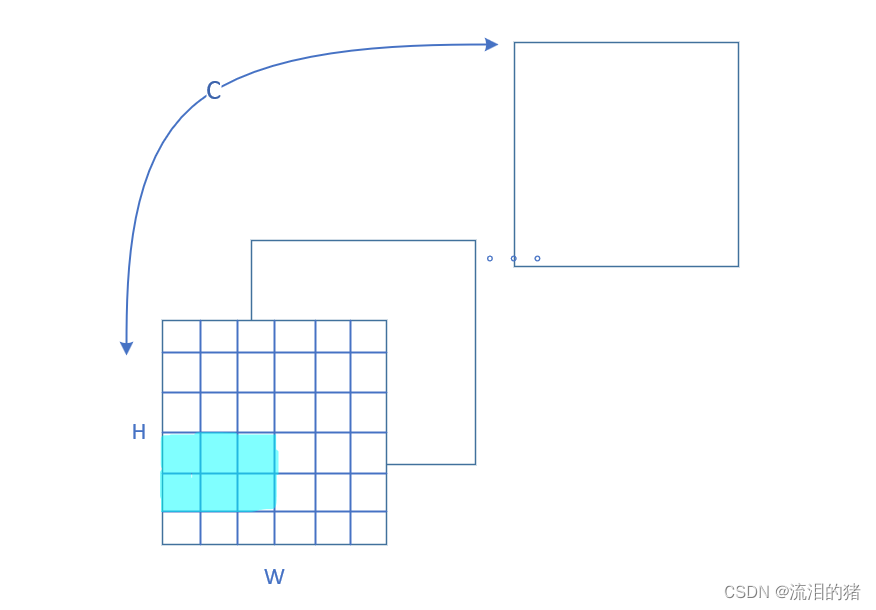
空间注意力在特征图中,在同一个通道中,不是所有的区域都是同等重要的,比如下图中,蓝色标记的位置是我们所重点关注的位置,我们就需要通过空间注意力机制,给相应的像素附更高的权值,实现重点关注该区域的功能。
三、集中注意力机制介绍(SEnet、CBAM)
在这里主要介绍SEnet和CBAM注意力机制以及相关pytorch代码实现。
1、SEnet
(1)论文来源
SEnet来自于论文《Squeeze-and-Excitation Networks》
论文链接是https://arxiv.org/abs/1709.01507
(2)SEnet结构组成
SEnet结构如下图所示,该模型可以实现通道注意力。

输入的特征尺寸是W×H×C, SEnet实现步骤包括以下几步:
1、全局平均池化:对每一个通道进行全局平均池化得到一个尺寸为1×1×C的特征。
2、Squeeze操作:将全局平均池化后的特征向量通过一个全连接层(一般是多层感知机)映射到一个较小的维度。这个过程被称为"Squeeze",用于学习通道的全局表示。一般来说,这个全连接层的输出维度可以通过一个超参数进行控制,以决定压缩的比例。
3、Excitation操作:将"Squeeze"操作的输出再经过一个全连接层,将维度恢复到原始的通道数。然后,通过一个激活函数(如Sigmoid函数)激活这个全连接层的输出,产生通道注意力权重。
4、重标定特征:将通道注意力权重与原始特征相乘,将注意力权重应用于原始特征,以重新加权特征图中的每个通道。这个过程可以通过将通道注意力权重扩展为与原始特征图相同的形状,然后将它们逐通道相乘实现。
实现代码如下:代码通过gpt生成,真的很好用哇
import torch
import torch.nn as nn
class SEBlock(nn.Module):
def __init__(self, channels, reduction=16):
super(SEBlock, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Linear(channels, channels // reduction)
self.relu = nn.ReLU(inplace=True)
self.fc2 = nn.Linear(channels // reduction, channels)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.size()
out = self.avg_pool(x).view(b, c)
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
out = self.sigmoid(out).view(b, c, 1, 1)
out = x * out.expand_as(x)
return out
class SENet(nn.Module):
def __init__(self, num_classes=10):
super(SENet, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(32)
self.se_block = SEBlock(32)
self.flatten = nn.Flatten()
self.fc = nn.Linear(32 * 32 * 32, num_classes)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = nn.ReLU(inplace=True)(out)
out = self.se_block(out)
out = self.flatten(out)
out = self.fc(out)
return out
# 创建模型实例
model = SENet()
2、CBAM
(1)论文来源
CBAM来自于论文《CBAM: Convolutional Block Attention Module》
原文链接:
https://arxiv.org/pdf/1807.06521.pdf
(2)CBAM结构组成
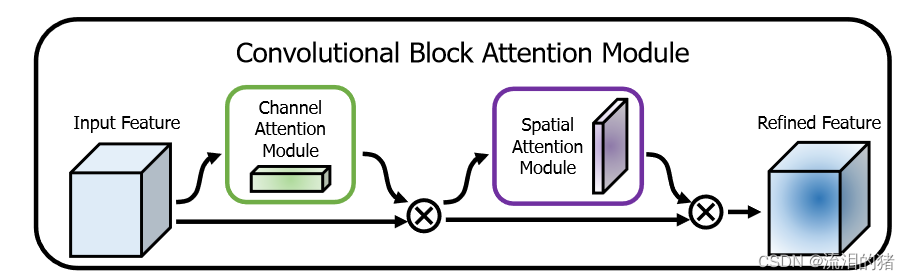
CBAM注意力机制包含通道注意力模块和空间注意力模块。主要包含以下步骤:
1、共享全局平均池化:对输入特征图进行两次全局平均池化操作,分别用于计算空间注意力和通道注意力。全局平均池化能够捕捉到整个特征图的统计信息。
2、空间注意力:对全局平均池化后的特征进行两个不同的处理分支。一个分支是通过一个1x1卷积层产生空间注意力权重,用于学习特征图不同位置的重要性。另一个分支是通过一个1x1卷积层产生空间注意力的缩放因子,用于调整特征图中每个通道的权重。这两个分支的输出通过逐元素相乘操作,得到最终的空间注意力。
3、通道注意力:对全局平均池化后的特征进行两个不同的处理分支。一个分支是通过一个全连接层产生通道注意力权重,用于学习每个通道的重要性。另一个分支是通过一个全连接层产生通道注意力的缩放因子,用于调整特征图中每个通道的权重。这两个分支的输出通过逐元素相乘操作,得到最终的通道注意力。
4、重标定特征:将空间注意力和通道注意力分别应用于原始特征图。首先,将空间注意力权重通过扩展和重复操作,使其与特征图具有相同的形状。然后,将通道注意力权重通过扩展操作,使其具有相同的维度。最后,将两者逐元素相乘,将注意力权重应用于原始特征图,得到最终的重标定特征。
实现代码如下:
import torch
import torch.nn as nn
class ChannelAttention(nn.Module):
def __init__(self, channels, reduction=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Conv2d(channels, channels // reduction, kernel_size=1, stride=1, padding=0)
self.relu = nn.ReLU(inplace=True)
self.fc2 = nn.Conv2d(channels // reduction, channels, kernel_size=1, stride=1, padding=0)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
out = self.avg_pool(x)
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
out = self.sigmoid(out)
out = x * out
return out
class SpatialAttention(nn.Module):
def __init__(self):
super(SpatialAttention, self).__init__()
self.conv = nn.Conv2d(2, 1, kernel_size=7, stride=1, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avg_out, max_out], dim=1)
out = self.conv(out)
out = self.sigmoid(out)
out = x * out
return out
class CBAM(nn.Module):
def __init__(self, channels, reduction=16):
super(CBAM, self).__init__()
self.channel_att = ChannelAttention(channels, reduction)
self.spatial_att = SpatialAttention()
def forward(self, x):
out = self.channel_att(x)
out = self.spatial_att(out)
return out
# 创建模型实例
model = CBAM(channels=64, reduction=16)