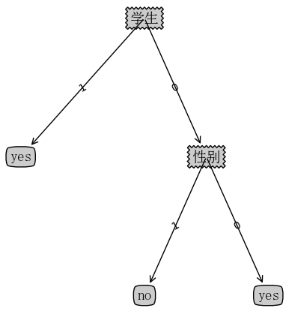
序号 Ik Xm-1 置信度 支持度 规则
1 BCE E 67 % 40 % E → BC
2 BCE CE 100 % 40 % CE → B
3 BCE BE 67 % 40 % BE → C
4 ABCD D 67 % 40 % D → ABC
5 ABCD A 67 % 40 % A → BCD
6 ABCD CD 100 % 40 % CD → AB
7 ABCD BD 67 % 40 % BD → AC
8 ABCD AD 100 % 40 % AD → BC
9 ABCD AC 67 % 40 % AC → BD
10 ABCD AB 67 % 40 % AB → CD
11 ABCD BCD 100 % 40 % BCD → A
12 ABCD ACD 100 % 40 % ACD → B
13 ABCD ABD 100 % 40 % ABD → C
14 ABCD ABC 67 % 40 % ABC → D
参数
输入参数:
参数变量名
值
数据地址
file_path
data/data_in_excercice3.13.txt
最小支持度
min_support
0.5
最小置信度
min_confidence
0.8
是否只求 最大频繁集的结果
is_maximum_frequent_itemset
0
计算出的结果(输出所有频繁项目集的强关联规则)
序号 Ik Xm-1 置信度 支持度 规则
1 BC B 80 % 80 % B → C
2 BC C 100 % 80 % C → B
3 CD D 67 % 40 % D → C
4 AB A 100 % 60 % A → B
5 AB B 60 % 60 % B → A
6 AD D 67 % 40 % D → A
7 AD A 67 % 40 % A → D
8 BE E 100 % 60 % E → B
9 BE B 60 % 60 % B → E
10 CE E 67 % 40 % E → C
11 AC A 100 % 60 % A → C
12 AC C 75 % 60 % C → A
13 BD D 100 % 60 % D → B
14 BD B 60 % 60 % B → D
15 BCE E 67 % 40 % E → BC
16 BCE BE 67 % 40 % BE → C
17 BCE CE 100 % 40 % CE → B
18 ABC A 100 % 60 % A → BC
19 ABC B 60 % 60 % B → AC
20 ABC C 75 % 60 % C → AB
21 ABC AB 100 % 60 % AB → C
22 ABC AC 100 % 60 % AC → B
23 ABC BC 75 % 60 % BC → A
24 ACD D 67 % 40 % D → AC
25 ACD A 67 % 40 % A → CD
26 ACD AD 100 % 40 % AD → C
27 ACD CD 100 % 40 % CD → A
28 ACD AC 67 % 40 % AC → D
29 ABD D 67 % 40 % D → AB
30 ABD A 67 % 40 % A → BD
31 ABD AD 100 % 40 % AD → B
32 ABD BD 67 % 40 % BD → A
33 ABD AB 67 % 40 % AB → D
34 BCD D 67 % 40 % D → BC
35 BCD BD 67 % 40 % BD → C
36 BCD CD 100 % 40 % CD → B
37 ABCD D 67 % 40 % D → ABC
38 ABCD A 67 % 40 % A → BCD
39 ABCD AD 100 % 40 % AD → BC
40 ABCD BD 67 % 40 % BD → AC
41 ABCD CD 100 % 40 % CD → AB
42 ABCD AB 67 % 40 % AB → CD
43 ABCD AC 67 % 40 % AC → BD
44 ABCD ABD 100 % 40 % ABD → C
45 ABCD ACD 100 % 40 % ACD → B
46 ABCD BCD 100 % 40 % BCD → A
47 ABCD ABC 67 % 40 % ABC → D
案例2:书上116页习题三13题
参数
输入参数:
参数变量名
值
数据地址
file_path
data/data/data_in_book.txt
最小支持度
min_support
0.5
最小置信度
min_confidence
0.8
是否只求 最大频繁集的结果
is_maximum_frequent_itemset
1
数据集
a,c,d,e,f
b,c,f
a,d,f
a,c,d,e
a,b,d,e,f
计算出的结果(仅输出最大频繁集中的强关联规则)
序号 Ik Xm-1 置信度 支持度 规则
1 ade e 100 % 60 % e → ad
2 ade de 100 % 60 % de → a
3 ade ae 100 % 60 % ae → d
4 adf df 100 % 60 % df → a
5 adf af 100 % 60 % af → d
参数
输入参数:
参数变量名
值
数据地址
file_path
data/data_in_excercice3.13.txt
最小支持度
min_support
0.5
最小置信度
min_confidence
0.8
是否只求 最大频繁集的结果
is_maximum_frequent_itemset
0
计算出的结果(输出所有频繁项目集的强关联规则)
序号 Ik Xm-1 置信度 支持度 规则
1 ad a 100 % 80 % a → d
2 ad d 100 % 80 % d → a
3 ae e 100 % 60 % e → a
4 de e 100 % 60 % e → d
5 adf af 100 % 60 % af → d
6 adf df 100 % 60 % df → a
7 ade e 100 % 60 % e → ad
8 ade ae 100 % 60 % ae → d
9 ade de 100 % 60 % de → a
代码
import itertools
defload_data(file_path):"""
加载数据集
:param file_path: 文件路径
:return: data_list list类型
"""
data_list =[]withopen(file_path, encoding="utf-8")as f:for line in f:
line = line.strip("\n")
data_list.append(line.split(','))# print(data_list)return data_list
defdata_2_index(data_set):"""
把data_set中的字符串转为index
:param data_set: 数据列表 list
:return: data_set 数据列表 list
"""# 把data_set拆包 然后取出其中的元素 通过set去重(无序) 得到所有样本的非重复集合
items =set(itertools.chain(*data_set))# print(items)# 保存字符串到编号的映射
str_2_index ={
}# 保存编号到字符串的映射
index_2_str ={
}for index, item inenumerate(items):# print(index, '->', item)
str_2_index[item]= index
index_2_str[index]= item
# print(str_2_index)# e.g: {'D': 0, 'E': 1, 'C': 2, 'A': 3, 'B': 4}# 把原来的矩阵中所有字符串转换为indexfor i inrange(len(data_set)):for j inrange(len(data_set[i])):
data_set[i][j]= str_2_index[data_set[i][j]]# print(data_set)return data_set, index_2_str
defbuild_c1(data_set):"""
创建候选1项集
:param data_set: 数字化后的data_set
:return: e.g:[frozenset({0, 45}), frozenset({1, 6})]
"""# 把data_set中的元素(已转化为index)去重
items =set(itertools.chain(*data_set))# print(items)# 用frozenset把项集装进新列表里"""
Tips: 使用frozenset的原意是接下来的步骤需要使用items里的内容做key
若直接将数字作为key的话也可以,但是后面还有生成二项集、三项集的操作,那就需要用list等来装,这样就不能作为key了
即:
my_dict = {}
my_dict[frozenset([1, 2, 3])] = 2.2
这个操作时可以的,打印my_dict是:{frozenset({1, 2, 3}): 2.2}
my_dict = {}
my_dict[[1, 2, 3]] = 2.2
这个非操作是非法的,TypeError: unhashable type: 'list' 即list不能哈希
当然,办法总比困难多,我试过将list转为str,将字符串作为key放入dict。这样也是可以,但是需要两个函数专门处理,
并且这两个解析函数还需要根据不同的数据类型专门写。
"""
frozen_items =[frozenset(i)for i inenumerate(items)]# print(frozen_items)# e.g: [frozenset({0}), frozenset({1}), frozenset({2}), frozenset({3}), frozenset({4})]return frozen_items
defck_2_lk(data_set, ck, min_support, no_frequent_set):"""
根据候选k项集生成频繁k项集,依据min_support
:param data_set: 数据集 list类型
:param ck: 候选k项集 list类型,list装frozenset
:param min_support: float 最小支持度
:param no_frequent_set: 非频繁项目集
:return: lk dict类型 频繁项目集
"""# 频数字典 用来记录每个项集出现的频数
support ={
}# 用数据集的每一行跟候选项集的每个项对比,若该项集是其中子集,则+1,否则为0for item in ck:# print(item)# 判断集合item是否为集合row的子集
flag =0for i in no_frequent_set:# 非频繁项目集的超集也是非频繁项目集if i.issubset(item):
flag =1break# 剪枝if flag ==1:continuefor row in data_set:# print(row)if item.issubset(row):# key -- 字典中要查找的键。# value -- 可选,如果指定键的值不存在时,返回该默认值。
support[item]= support.get(item,0)+1# print(support)# 计算频率需要用到长度
length =len(data_set)
lk ={
}for key, value in support.items():# print(key, value)
percent = value / length
# 频率大于最小支持度才能进入频繁项集if percent >= min_support:
lk[key]= percent
else:# 如果是非频繁项目集,记录之,包含其的子集都不用计算了
no_frequent_set.append(key)return lk
deflk_2_ck_plus_1(lk):"""
将频繁k项集(lk)两两组合转为候选k+1项集
:param lk: 频繁k项集 dict
:return: ck_plus_1
"""
lk_list =list(lk)# print(lk_list)# 保存组合后的k+1项集
ck_plus_1 =set()
lk_size =len(lk)# 若lk_size<=1则不需要再组合(最后一次)if lk_size >1:# 获取频繁项集的长度
k =len(lk_list[0])"""
itertools.combinations(range(lk_size), 2) 相当于从lk_size中任选2个项集 i,j
即c_n_2
"""for i, j in itertools.combinations(range(lk_size),2):# print(i, j)# 取并集
t = lk_list[i]| lk_list[j]# print(lk_list[i],lk_list[j],t)# 两两组合后项集长度是k+1,否则不要iflen(t)== k +1:
ck_plus_1.add(t)# print(t)# print(ck_plus_1)return ck_plus_1
defget_all_L(data_set, min_support):"""
把所有的频繁项集拿到
:param data_set: 数据
:param min_support: 最小支持度
:return:
"""# 创建候选1项集
c1 = build_c1(data_set)# print(c1)# 从候选1项集 到 频繁1项集(第一次不需要两两组合)
no_frequent_set =[]
l1 = ck_2_lk(data_set, ck=c1, min_support=min_support, no_frequent_set=no_frequent_set)
L = l1
Lk = l1
whilelen(Lk)>0:
lk_key_list =list(Lk.keys())# print(lk_key_list)# 频繁k 到 候选k+1 进行了两两组合
ck_plus_1 = lk_2_ck_plus_1(lk_key_list)# 候选k 到 频繁k
Lk = ck_2_lk(data_set, ck_plus_1, min_support, no_frequent_set)iflen(Lk)>0:# 把字典lk的键/值对更新到l
L.update(Lk)else:breakreturn L
defrules_from_item(item):"""
将item两两组合,并返回其差集
:param item: 所有关联规则中的一个键值对
:return:
"""# print(item)# 关联规则左边
left =[]for i inrange(1,len(item)):"""
若使用append 则会把combinations对象原封不动添加进列表里
使用extend 则会把combinations对象拆包再添加到列表里
combination对象是可以迭代的一个对象 combinations(item,1) = combinations((1,),(2,),(3,))
"""# 将一个列表和数字 i 作为参数,并返回一个元组列表,每个元组的长度为 i,其中包含x个元素的所有可能组合。列表中元素不能与自己结合,不包含列表中重复元素
left.extend(itertools.combinations(item, i))# left.append(itertools.combinations(item, i))# print(left)# difference()方法用于返回集合的差集。
ans =[(frozenset(i),frozenset(item.difference(i)))for i in left]# print(ans)return ans
defrules_from_L(max_L, L, min_confidence):"""
:param L: 所有关联规则(字典 frozenset为键,支持度为值)
:param min_confidence:
:return:
"""# 保存所有候选的关联规则
rules =[]for Lk in max_L:# 频繁项集长度要大于1才能生成关联规则iflen(Lk)>1:# 用于在列表末尾一次性追加另一个序列中的多个值
rules.extend(rules_from_item(Lk))
result =[]# print(rules)for left, right in rules:# left和right都是frozenset类型 二者可以取并集(分子 Ik) 然后L里去查询支持度
support = L[left | right]# 置信度公式
confidence = support / L[left]
lift = confidence / L[right]if confidence >= min_confidence:
result.append({
"左": left,"右": right,"支持度": support,"置信度": confidence,"提升度": lift})return result
defreturn_2_str(index_2_str, result):"""
把index转为具体商品名称
:param index_2_str: index:str 的dict
:param result: 关联规则的list
:return:
"""for item in result:
true_left =[]
true_right =[]
left =list(item['左'])for tem in left:
true_left.append(index_2_str[tem])
right =list(item['右'])for tem in right:
true_right.append(index_2_str[tem])
item['左']=frozenset(true_left)
item['右']=frozenset(true_right)return result
defprint_frozenset(fs):
ans =[]for i in fs:
ans.append(i)return"".join(sorted(ans))defget_maximum_frequent_itemset(L):"""
求最大频繁项目集
:param L:
:return:
"""
max_L ={
}for i in L:
flag =1for j in L:# 子集不能比本身长iflen(i)>=len(j):continue# 是某个子集表示其不是最大频繁项目集if i.issubset(j):
flag =0breakif flag ==1:# print(L[i])
max_L[i]= L[i]# print(max_L)return max_L
if __name__ =='__main__':# 参数列表# 数据源# file_path = "data/data.txt"# # 最小支持度,需大于等于该值# min_support = 0.04# # 最小置信度# min_confidence = 0.06# file_path = "data/data_in_book.txt"# # 最小支持度,需大于等于该值# min_support = 0.4# # 最小置信度# min_confidence = 0.6
file_path ="data/data_in_excercice3.13.txt"# 最小支持度,需大于等于该值
min_support =0.5# 最小置信度
min_confidence =0.8# 是否只求最大频繁集的结果
is_maximum_frequent_itemset =1# 加载数据
data_set = load_data(file_path)# 把数据转为数字 方便比较计算
data_set, index_2_str = data_2_index(data_set)# 得到所有频繁项目集
L = get_all_L(data_set, min_support=min_support)if is_maximum_frequent_itemset:
max_L = get_maximum_frequent_itemset(L)# print(max_L)# 仅算出最大频繁项目集的关联规则
result = rules_from_L(max_L, L, min_confidence=min_confidence)else:# 得到所有关联规则
result = rules_from_L(L, L, min_confidence=min_confidence)
result = return_2_str(index_2_str, result)# print(result)print("序号","\t","Ik","\t","Xm-1","\t","置信度","\t","支持度","\t","规则")
index =1for item in result:print(index,"\t\t", print_frozenset(item["左"]| item["右"]),"\t", print_frozenset(item["左"]),"\t\t",round(item["置信度"]*100),"%\t",round(item["支持度"]*100),"%\t",
print_frozenset(item["左"]),"→", print_frozenset(item["右"]))
index +=1
# 统计yi的个数deftypeCount(typeList, t):
cnt =0for tL in typeList:if tL == t:
cnt +=1return cnt
# 计算Y=-1或1的条件下,X等于某值 个数deffeatCount(dataSet, i, feat, y):
cnt =0# print(i, feat, y)for row in dataSet:if row[i]== feat and row[-1]== y:
cnt +=1return cnt
defcalcBayes(dataSet, X):
lenDataSet =len(dataSet)
typeList =[row[-1]for row in dataSet]
typeSet =set(typeList)# 类别集合print(typeList, typeSet)
pList =[]# 记录预计 各类类别 概率for t in typeSet:print('-'*50)
yNum = typeCount(typeList, t)# 计算yi的个数print(f'{
t} num =', yNum)
py = yNum / lenDataSet
print(f'P(Y = {
t}) =', py)
pSum = py
# 对每个特征分量计数for i inrange(len(X)):
xiNum = featCount(dataSet, i, X[i], t)# 统计Y条件下 Xi取相应特征 的数量print(f'特征{
X[i]} num =', xiNum)# 条件概率P{X = xi | Y = yi}
pxy = xiNum / yNum
print(f'条件概率 =', pxy)
pSum *= pxy
print(f'P(X|Y= {
t})P(Y= {
t}) =', pSum)
pList.append(pSum)# print(pList)return pList, typeSet
# 就是找最大的概率,记录下标defpredict(pList, typeList):for i inrange(len(pList)):if pList[i]==max(pList):print('*'*50)print(f'预测类为 = {
typeList[i]}')returndefcreateDataSet(file_path):"""
加载数据集
:param file_path: 文件路径
:param line: 读多少行,0代表都读,1代表只读取表头
:return: data_list list类型
"""
labels =[]
dataSet =[]
i =1withopen(file_path, encoding="utf-8")as f:for line in f:
line = line.strip("\n")if i ==1:
labels = line.split(',')else:
dataSet.append(line.split(','))
i = i +1return dataSet, labels # 返回数据集和分类属性if __name__ =='__main__':
path ="./data/book_p139.csv"
X =['0','1','1','0']
dataSet, labels = createDataSet(path)
pList, typeSet = calcBayes(dataSet, X)
predict(pList,list(typeSet))
任务五 K-Means算法的编程实现
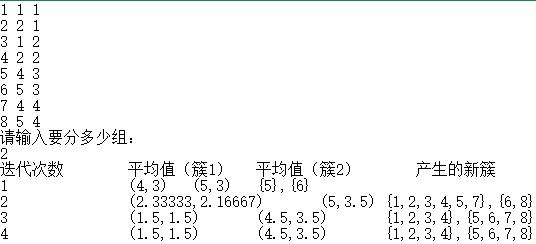
运行结果截图
数据集
1,1,1
2,2,1
3,1,2
4,2,2
5,4,3
6,5,3
7,4,4
8,5,4
代码
#include <bits/stdc++.h>
using namespace std;
vector<vector<int> > sample;
//表格大小
int row = 0;
int column;
struct group {
vector<double> avg;//簇每个属性的平均值
vector<int> ids;//簇的成员id
void cal_avg(int field_num) {
//序号不求平均值
for (int i = 1; i < field_num; i++)
{
double ans = 0;
for (int j = 0; j < ids.size(); j++)
{
ans += sample[ids[j]-1][i];
}
avg.push_back(ans / ids.size());
}
}
};
vector<group> get_new_groups(vector<group>& old_groups, bool &flag) {
vector<group> new_groups;
for (int i = 0; i < old_groups.size(); i++)
{
group t;
new_groups.push_back(t);
}
//每次取一个样本,分别计算其和各个簇的距离,最近的就把这个样本id放到那个簇里面去
//依次计算每个属性离哪个中心点最近,把它放在最近中心点的簇中
for (int i = 0; i < row; i++)
{
int min_distance = INT_MAX;
int target_groups=-1;
for (int k = 0; k < old_groups.size(); k++)
{
int t_distance = 0;
//序号不计算
for (int j = 1; j < column; j++)
{
//欧氏距离
t_distance += pow(abs(sample[i][j] - old_groups[k].avg[j - 1]), 2);
}
if (min_distance > t_distance)
{
min_distance = t_distance;
//应该分到哪一类
target_groups = k;
}
}
//避免了序号的重复
new_groups[target_groups].ids.push_back(sample[i][0]);
}
for (int i = 0; i < new_groups.size(); i++) {
new_groups[i].cal_avg(column);
}
for (int i = 0; i < new_groups.size(); i++) {
int len = new_groups[i].avg.size(),j;
//判断质心是否移动
for (j = 0; j < len; j++)
{
if (new_groups[i].avg[j]!=old_groups[i].avg[j])
{
flag = false;
break;
}
}
if (j== len)
{
flag = true;
}
else
{
flag = false;
break;
}
}
old_groups.clear();
return new_groups;
}
void print_head(vector<group> old_groups) {
//打印
string blank = "";
cout << "迭代次数\t";
for (int i = 1; i <= old_groups.size(); i++)
{
cout << "平均值(簇" << i << ")\t";
}
for (int i = 0; i < row / 2; i++)
{
blank += ' ';
}
cout << blank << "产生的新簇" << blank << endl;
}
void print_content(vector<group> current_groups,int &id) {
cout << id << "\t\t";
//打印平均值
for (int i = 0; i < current_groups.size(); i++)
{
int length = current_groups[i].avg.size();
cout << "(" << current_groups[i].avg[0];
for (int j = 1; j < length - 1; j++)
{
cout << "," << current_groups[i].avg[j];
}
cout << "," << current_groups[i].avg[length - 1] << ")\t";
}
//打印簇
for (int i = 0; i < current_groups.size(); i++)
{
cout << "{";
int length = current_groups[i].ids.size();
for (int j = 0; j < length - 1; j++) {
cout << current_groups[i].ids[j] << ",";
}
cout << current_groups[i].ids[length - 1];
if (i != current_groups.size() - 1)
{
cout << "},";
}
else
{
cout << "}";
}
}
cout << endl;
id++;
}
int main()
{
string path = "data.csv";//书P178
//string path = "data1.csv";
//string path = "data2.csv";
ifstream inFile(path, ios::in);
if (!inFile)
{
cout << "打开文件失败!" << endl;
exit(1);
}
string line;
string field;
while (getline(inFile, line))//getline(inFile, line)表示按行读取CSV文件中的数据
{
sample.push_back(vector<int>());
string field;
istringstream sin(line); //将整行字符串line读入到字符串流sin中
while (getline(sin, field, ',')) {//将字符串流sin中的字符读入到field字符串中,以逗号为分隔符
sample[row].push_back(atoi(field.c_str()));
}
row++;
}
inFile.close();
column = sample[0].size();
for (int i = 0; i < row; i++)
{
for (int j = 0; j < sample[i].size(); j++)
{
cout << sample[i][j] << " ";
}
cout << endl;
}
//组数
int k;
cout << "请输入要分多少组:\n";
cin >> k;
while (k > row) {
cout << "组数不合法";
cin >> k;
}
vector<group> old_groups;
set<int> initial;//初始各个簇随机放一个id [1,row]
srand(time(0));
while (initial.size()!=k)
{
int id = rand() % row + 1;
initial.insert(id);
}
//待删除
//initial.clear();
//initial.insert(1);
//initial.insert(3);
for (set<int>::iterator i = initial.begin(); i!=initial.end(); i++)
{
group t;
t.ids.push_back(*i);
t.cal_avg(column);
old_groups.push_back(t);
}
print_head(old_groups);
int id = 1;
print_content(old_groups, id);
//第二次及以后迭代
//返回的是new_groups
bool flag = false;
while (!flag)
{
old_groups = get_new_groups(old_groups,flag);
print_content(old_groups, id);
}
return 0;
}
任务六 Agnes算法的编程实现
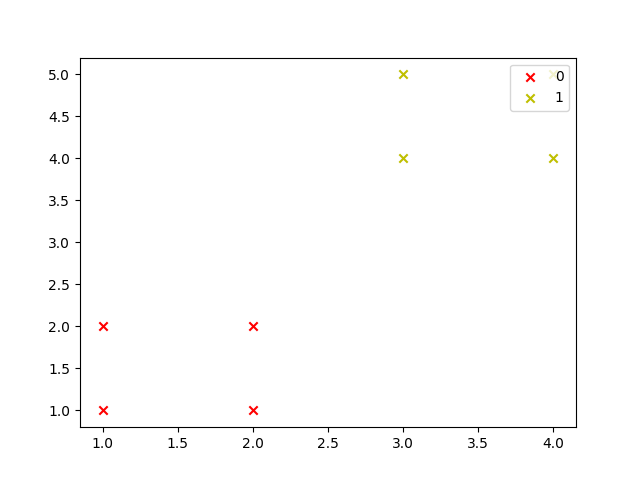
运行结果截图
数据集(dataset.csv)
1,1
1,2
2,1
2,2
3,4
3,5
4,4
4,5
代码
# -*- coding:utf-8 -*-import math
import pylab as pl
# 计算欧几里得距离,a,b分别为两个元组defdist(a, b):return math.sqrt(math.pow(a[0]- b[0],2)+ math.pow(a[1]- b[1],2))# dist_mindefdist_min(Ci, Cj):returnmin(dist(i, j)for i in Ci for j in Cj)# dist_maxdefdist_max(Ci, Cj):returnmax(dist(i, j)for i in Ci for j in Cj)# dist_avgdefdist_avg(Ci, Cj):returnsum(dist(i, j)for i in Ci for j in Cj)/(len(Ci)*len(Cj))# 找到距离最小的下标deffind_Min(M):min=1000
x =0
y =0for i inrange(len(M)):for j inrange(len(M[i])):if i != j and M[i][j]<min:min= M[i][j]
x = i
y = j
return(x, y,min)# 算法模型:defAGNES(dataset, dist, k):# 初始化C和M
C =[]# 初始簇
M =[]for i in dataset:
Ci =[]
Ci.append(i)
C.append(Ci)for i in C:
Mi =[]for j in C:
Mi.append(dist(i, j))
M.append(Mi)
q =len(dataset)# 合并更新while q > k:
x, y,min= find_Min(M)
C[x].extend(C[y])
C.remove(C[y])
M =[]for i in C:
Mi =[]for j in C:
Mi.append(dist(i, j))
M.append(Mi)
q -=1return C
# 画图defdraw(C):
colValue =['r','y','g','b','c','k','m']for i inrange(len(C)):
coo_X =[]# x坐标列表
coo_Y =[]# y坐标列表for j inrange(len(C[i])):
coo_X.append(C[i][j][0])
coo_Y.append(C[i][j][1])
pl.scatter(coo_X, coo_Y, marker='x', color=colValue[i %len(colValue)], label=i)
pl.legend(loc='upper right')
pl.show()defload_data(file_path):"""
加载数据集
:param file_path: 文件路径
:return: dataset list类型
"""
dataset =[]withopen(file_path, encoding="utf-8")as f:for line in f:
line = line.strip("\n")
t =[]for i in line.split(','):
t.append(float(i))
dataset.append(t)return dataset
if __name__ =="__main__":
file_path ="./dataset/dataset.csv"
category =2
dataset = load_data(file_path)
C = AGNES(dataset, dist_max, category)
draw(C)
import matplotlib.pyplot as plt
import random
import numpy as np
import math
list_1 =[]
list_2 =[]# 数据集一:随机生成散点图, 参数为点的个数defscatter(num):for i inrange(num):
x = random.randint(0,100)
list_1.append(x)
y = random.randint(0,100)
list_2.append(y)print(list_1)print(list_2)
data =list(zip(list_1, list_2))print(data)
plt.scatter(list_1, list_2)
plt.show()return data
defdataSet1(num, Eps, MinPts):# 数据集一:随机生成散点图, 参数为点的个数
dataSet = scatter(num)
C = dbscan(dataSet, Eps, MinPts)print(C)
x =[]
y =[]for data in dataSet:
x.append(data[0])
y.append(data[1])
plt.figure(figsize=(8,6), dpi=80)
plt.scatter(x, y, c=C, marker='o')
plt.show()defloadDataSet(fileName, splitChar='\t'):
dataSet =[]withopen(fileName)as fr:for line in fr.readlines():
curline = line.strip().split(splitChar)
fltline =list(map(float, curline))# 将字符串转换成浮点数
dataSet.append(fltline)return dataSet
# 计算两个点之间的欧式距离,参数为两个元组defdist(t1, t2):
dis = math.sqrt((np.power((t1[0]- t2[0]),2)+ np.power((t1[1]- t2[1]),2)))# print("两点之间的距离为:"+str(dis))return dis
# dis = dist((1,1),(3,4))# print(dis)# DBSCAN算法,参数为数据集,Eps为指定半径参数,MinPts为制定邻域密度阈值# 数据集二:788个点defdbscan(Data, Eps, MinPts):
num =len(Data)# 点的个数# print("点的个数:"+str(num))
unvisited =[i for i inrange(num)]# 没有访问到的点的列表# print(unvisited)
visited =[]# 已经访问的点的列表
C =[-1for i inrange(num)]# C为输出结果,初始时是一个长度为所有点的个数的值全为-1的列表。之后修改点对应的索引的值来设置点属于哪个簇。# 用k来标记不同的簇,k = -1表示噪声点
k =-1# 如果还有没访问的点whilelen(unvisited)>0:# 随机选择一个unvisited对象
p = random.choice(unvisited)# 每次访问一个点,unvisited列表remove该点,visited列表append该点,以此来实现点的标记改变。
unvisited.remove(p)
visited.append(p)# N为p的epsilon邻域中的对象的集合
N =[]for i inrange(num):# 计算epsilon邻域中的对象的个数if(dist(Data[i], Data[p])<= Eps):# and (i!=p):
N.append(i)# 如果p的epsilon邻域中的对象数大于指定阈值,说明p是一个核心对象iflen(N)>= MinPts:
k = k +1# 簇编号加一# print(k)
C[p]= k
# 对于p的epsilon邻域中的每个对象pi,将其加入p的簇中for pi in N:# 深度优先搜索,一次找出某一个核心对象的所有密度可达点(好像广度优先会更合理?不过这样与原算法定义有差异)if pi in unvisited:
unvisited.remove(pi)
visited.append(pi)# 找到核心对象p的邻域中的对象pi# M是位于pi的邻域中的核心对象点的列表
M =[]for j inrange(num):if(dist(Data[j], Data[pi])<= Eps):# and (j!=pi):
M.append(j)iflen(M)>= MinPts:for t in M:if t notin N:
N.append(t)# 将核心对象p领域内的核心对象加到N末尾,起到每次找出所有直接密度可达的点# 若pi不属于任何簇,C[pi] == -1说明C中第pi个值没有改动if C[pi]==-1:
C[pi]= k
# 如果p的epsilon邻域中的对象数小于指定阈值,说明p是一个噪声点else:
C[p]=-1return C
defdataSet2(dataSet, Eps, MinPts):
C = dbscan(dataSet, Eps, MinPts)print(C)
x =[]
y =[]for data in dataSet:
x.append(data[0])
y.append(data[1])
plt.figure(figsize=(8,6), dpi=80)
plt.scatter(x, y, c=C, marker='o')
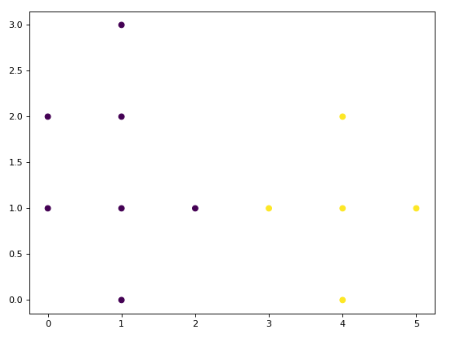
plt.show()if __name__ =='__main__':# dataSet1(1000, 10, 5)# dataSet2(loadDataSet('788points.txt', splitChar=','), 2, 14)
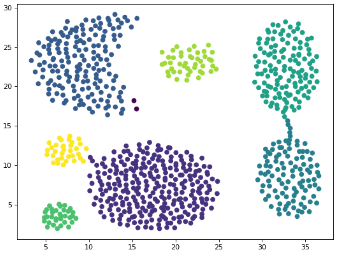
dataSet2(loadDataSet('book_p191.txt', splitChar=','),1,4)