导读
参考文章:
Yolov7学习笔记(五)损失函数中的正样本匹配
Yolov7原论文
IoU、GIoU、DIoU、CIoU、EIoU 5大评价指标
one-hot编码
torch.nn.BCELoss()和torch.nn.BCEWithLogitsLoss()损失函数
预测结果如图所示,8张图,每张图有3个图层(layer),每个图层有3个anchor。
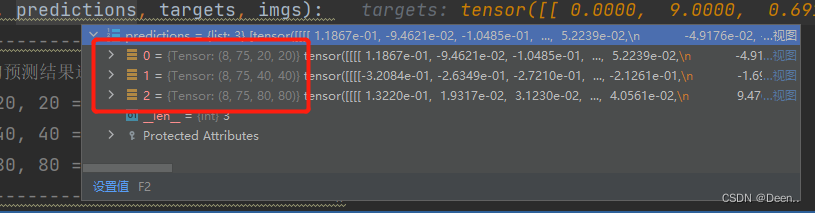
将3个anchor分离开:
bs, 75, 20, 20 => bs, 3, 20, 20, 25
bs, 75, 40, 40 => bs, 3, 40, 40, 25
bs, 75, 80, 80 => bs, 3, 80, 80, 25
[bs, 3, 20, 20, 25]意味这这个layer有8张图,且有3个anchor,特征图层的尺寸为20*20,每个网格有25个值,前4个为预测框中心点,第5个为这个预测框的目标置信度,后20个为预测框的类别置信度。
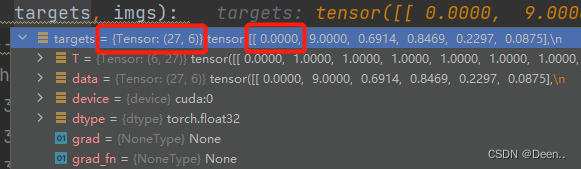
再来看真实框(target)
真实框尺寸为[number,6],这个number指的是这一个batch_size中有多少个真实框,例子的batch_size=8,number=27,如下图所示,这8张图片中有27个真实框。[number,6]中的6的第一个数值表示这个具体的真实框属于哪一张图片,下图画圈这个真实框属于第1张图,第二个数值为该真实框的类别,后面4个为真实框的坐标。其具体值为归一化后的[x,y,w,h]
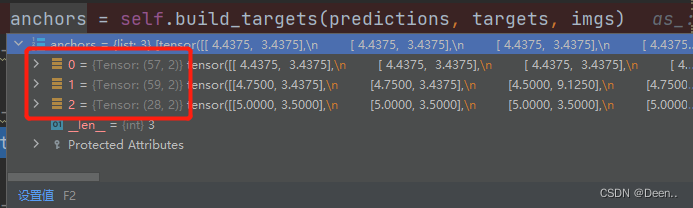
通过正样本匹配后得到正样本锚框以及与其对应的真实框。
正样本锚框的宽高:
正样本锚框的左上角坐标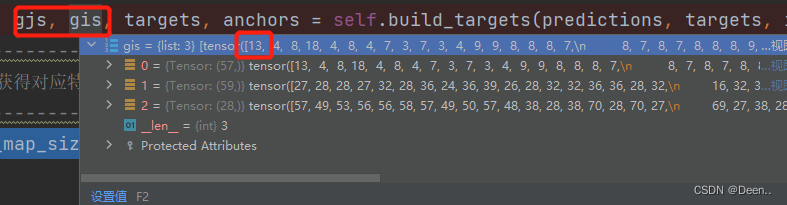
每个锚框对应的真实框。
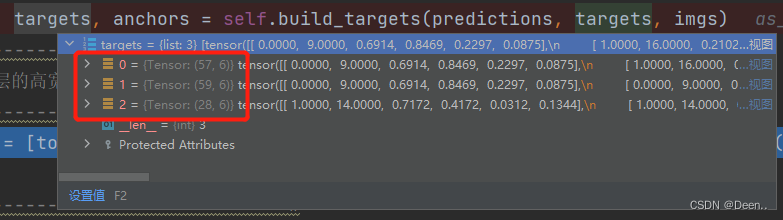
如上图的例子中,第1个图层匹配成功的正样本有57个,第2个图层有59个,第3个图层有28个。
损失函数求解
论文里没看到损失函数的公式,去翻了翻其他系列,V7的损失函数跟V5的基本差不多。还是求解种类损失、置信度损失、坐标回归损失的和。在SSD中损失函数求正样本与负样本的损失,在V7里只求正样本的损失。
yolov5的损失函数包括:
classification loss 类别置信度损失
localization loss 坐标回归损失,预测框和真实框之间的误差
confidence loss 目标置信度损失,框的目标性
总损失函数为三者的和
classification loss + localization loss + confidence loss
也可以在三个损失前乘上不同的权重系数,已达到不同比重的结果。
在yolov5中的置信度损失和类别损失用的是二元交叉熵来做的,而定位损失是用的CIOU Loss来做的
yolov7的损失函数包括:
损失函数的值 == 目标置信度损失0.1+类别置信度损失0.125+坐标回归损失*0.05
在yolov7中的置信度损失和类别损失用的是二元交叉熵来做的,而定位损失是用的CIOU Loss来做的,跟yolov5是一样的。
具体流程:
计算损失,对三个特征层各自进行处理:
取出一个特征层,取出这个特征层中的正样本锚框的属性。
for i, prediction in enumerate(predictions):
#-------------------------------------------#
# image, anchor, gridy, gridx
#-------------------------------------------#
b, a, gj, gi = bs[i], as_[i], gjs[i], gis[i]
tobj = torch.zeros_like(prediction[..., 0], device=device) # target obj
然后 获得目标数量,如果目标大于0 则开始计算回归损失和种类损失。
# 获得目标数量,如果目标大于0
# 则开始计算种类损失和回归损失
#-------------------------------------------#
n = b.shape[0]
正样本回归损失
找到正样本锚框对应的预测框,将其取出:
prediction_pos = prediction[b, a, gj, gi]
获取正样本锚框的网格的坐标:
# grid 获得正样本的x、y轴坐标
#-------------------------------------------#
grid = torch.stack([gi, gj], dim=1)
对预测框进行解码,解码后的值是对应特征图层尺寸的值:
下列(x,y)对应锚框网格左上角坐标的偏移量,因为真实框也是与正样本锚框一样对应,它的(x,y)也是相对锚框网格的左上角坐标。真实框跟预测框都在同一个锚框内。
预测框的(x,y):
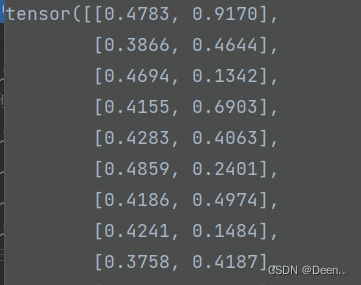
真实框的(x,y):
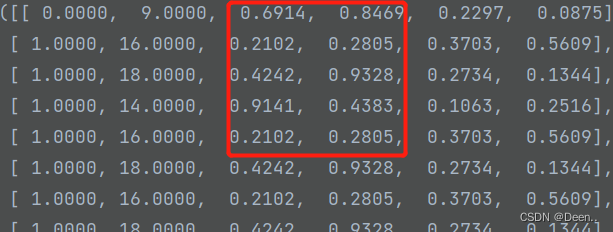
# 进行解码,获得预测结果
#-------------------------------------------#
xy = prediction_pos[:, :2].sigmoid() * 2. - 0.5
wh = (prediction_pos[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
box = torch.cat((xy, wh), 1)
所以将真实框的值也映射到特征图层上,得到与其对应的特征图层尺寸的值:
selected_tbox = targets[i][:, 2:6] * feature_map_sizes[i]
selected_tbox[:, :2] -= grid.type_as(prediction)
计算预测框和真实框的回归损失,刚好真实框跟预测框都是一样对应的,在相应网格上计算预测框跟真实框的iou,最后再取平均:
# 计算预测框和真实框的回归损失
#-------------------------------------------#
iou = self.bbox_iou(box.T, selected_tbox, x1y1x2y2=False, CIoU=True)
box_loss += (1.0 - iou).mean()
GIOU
参考文章:IoU、GIoU、DIoU、CIoU、EIoU 5大评价指标
建议直接去看这篇文章。

正样本类别损失
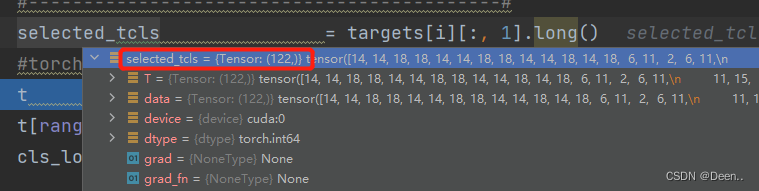
首先先查找真实框targets是属于哪个类别的,然后将其类别取出 selected_tcls:[number],number是真实框的数量,以下图为例,真实框的数量是122个(122其实是由正样本数量决定,因为这部分内容是另一个时间做debug的,所以正样本数量跟前文不一样。):
再将这个类别制作成[122,20]的格式,这一部分其实就是one-hot编码:
t = torch.full_like(prediction_pos[:, 5:], self.cn, device=device) # targets
t[range(n), selected_tcls] = self.cp

然后再将真实框的类别跟预测框的类别进行self.BCEcls求解,这是一个损失函数,求解完毕后得到类别损失值。
#-------------------------------------------#
# 计算匹配上的正样本的分类损失
#-------------------------------------------#
selected_tcls = targets[i][:, 1].long()
#torch.full_like 返回一个形状与input相同且值全为fill_value的张量
t = torch.full_like(prediction_pos[:, 5:], self.cn, device=device) # targets
t[range(n), selected_tcls] = self.cp
cls_loss += self.BCEcls(prediction_pos[:, 5:], t) # BCE
self.BCEcls
这边提一下self.BCEcls损失函数,引用这篇文章内容:
self.BCEcls用的是torch.nn.BCEWithLogitsLoss(),也就是二元交叉熵损失,跟torch.nn.BCELoss()的区别在于交叉熵计算前,将计算数值归一化。
BCELoss的全称是Binary Cross Entropy, 即二分类交叉熵损失。如下公式 (y是真实标签,p是预测值):
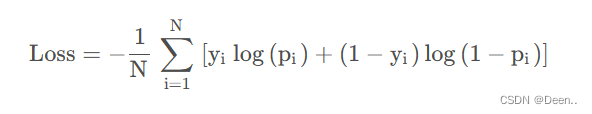
其实这个函数就是CrossEntropyLoss的当类别数N=2时候的特例。因为类别数为2,属于第一类的概率为y,那么属于第二类的概率自然就是(1-y)。因此套用与CrossEntropy损失的计算方法,用对应的标签乘以对应的预测值再求和,就得到了最终的损失。
正样本目标置信度损失
把真实框跟预测框的重合程度认为是这个网格有目标的置信度也就是tobj,然后让预测框的置信度去逼近这个值。如果真实框跟预测框完全重合,即iou等于1,如果预测框的目标置信度等于1,这样子计算出来obj_loss目标置信度损失就为0。所以应该让预测框的目标置信度去逼近1。也就是让预测框的目标置信度去逼近iou的值。
obj_loss += self.BCEobj(prediction[..., 4], tobj) * self.balance[i] # obj loss
prediction[…, 4]是预测框的目标置信度。
tobj是真实框与预测框求iou后得到的值,如果真实框跟预测框的越重合,number个iou值也就越大,tobj的值也就越接近1,如下图:
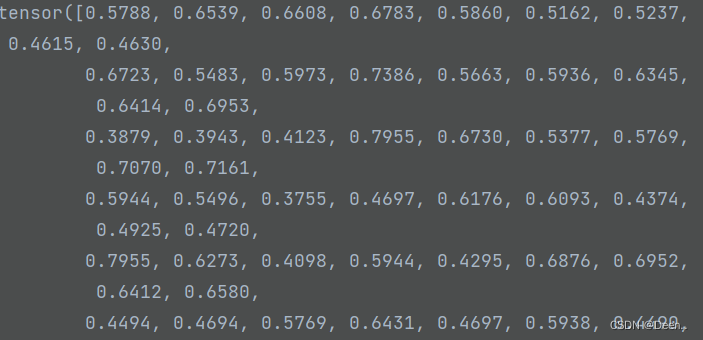
#detach 意为分离,对某个张量调用函数 d e t a c h ( ) \rm detach()detach() 的作用是返回一个 T e n s o r \rm TensorTensor,它和原张量的数据相同,但 r e q u i r e s _ g r a d = F a l s e \rm requires\_grad=Falserequires_grad=False,也就意味着 d e t a c h ( ) \rm detach()detach() 得到的张量不会具有梯度。这一性质即使我们修改其 r e q u i r e s _ g r a d \rm requires\_gradrequires_grad 属性也无法改变。
# clamp()函数的功能将输入input张量每个元素的值压缩到区间 [min,max],并返回结果到一个新张量。
tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * iou.detach().clamp(0).type(tobj.dtype) # iou ratio
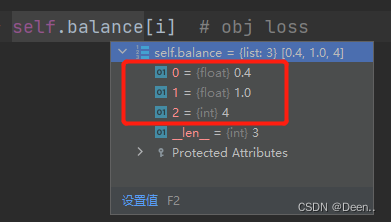
计算目标是否存在的置信度损失,并且乘上每个特征层的比例,第一个特征层占0.4,第二个特征层占1,第3个特征层占4。
总损失值
3个layer依次完成3个损失函数的求解后,将损失值求和取平均:
yolov7的损失函数只针对正样本。
损失函数的值 == 目标置信度损失0.1+类别置信度损失0.125+坐标回归损失*0.05
box_loss *= self.box_ratio
obj_loss *= self.obj_ratio
cls_loss *= self.cls_ratio
bs = tobj.shape[0]
loss = box_loss + obj_loss + cls_loss
return loss
这就求得本轮的loss总损失了。
代码:
#使得类实例对象可以像调用普通函数那样,以“对象名()”的形式使用。
def __call__(self, predictions, targets, imgs):
#-------------------------------------------#
# 对输入进来的预测结果进行reshape
# bs, 255, 20, 20 => bs, 3, 20, 20, 85
# bs, 255, 40, 40 => bs, 3, 40, 40, 85
# bs, 255, 80, 80 => bs, 3, 80, 80, 85
#-------------------------------------------#
for i in range(len(predictions)):
bs, _, h, w = predictions[i].size()
predictions[i] = predictions[i].view(bs, len(self.anchors_mask[i]), -1, h, w).permute(0, 1, 3, 4, 2).contiguous()
#-------------------------------------------#
# 获得工作的设备
#-------------------------------------------#
device = targets.device
#-------------------------------------------#
# 初始化三个部分的损失
#-------------------------------------------#
cls_loss, box_loss, obj_loss = torch.zeros(1, device = device), torch.zeros(1, device = device), torch.zeros(1, device = device)
#-------------------------------------------#
# 进行正样本的匹配
#-------------------------------------------#
bs, as_, gjs, gis, targets, anchors = self.build_targets(predictions, targets, imgs)
#-------------------------------------------#
# 计算获得对应特征层的高宽
#-------------------------------------------#
feature_map_sizes = [torch.tensor(prediction.shape, device=device)[[3, 2, 3, 2]].type_as(prediction) for prediction in predictions]
#-------------------------------------------#
# 计算损失,对三个特征层各自进行处理
#-------------------------------------------#
for i, prediction in enumerate(predictions):
#-------------------------------------------#
# image, anchor, gridy, gridx
#-------------------------------------------#
b, a, gj, gi = bs[i], as_[i], gjs[i], gis[i]
tobj = torch.zeros_like(prediction[..., 0], device=device) # target obj
#-------------------------------------------#
# 获得目标数量,如果目标大于0
# 则开始计算种类损失和回归损失
#-------------------------------------------#
n = b.shape[0]
if n:
prediction_pos = prediction[b, a, gj, gi] # prediction subset corresponding to targets
#-------------------------------------------#
# 计算匹配上的正样本的回归损失
#-------------------------------------------#
#-------------------------------------------#
# grid 获得正样本的x、y轴坐标
#-------------------------------------------#
grid = torch.stack([gi, gj], dim=1)
#-------------------------------------------#
# 进行解码,获得预测结果
#-------------------------------------------#
xy = prediction_pos[:, :2].sigmoid() * 2. - 0.5
wh = (prediction_pos[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
box = torch.cat((xy, wh), 1)
#-------------------------------------------#
# 对真实框进行处理,映射到特征层上
#-------------------------------------------#
selected_tbox = targets[i][:, 2:6] * feature_map_sizes[i]
selected_tbox[:, :2] -= grid.type_as(prediction)
#-------------------------------------------#
# 计算预测框和真实框的回归损失
#-------------------------------------------#
iou = self.bbox_iou(box.T, selected_tbox, x1y1x2y2=False, CIoU=True)
box_loss += (1.0 - iou).mean()
#-------------------------------------------#
# 根据预测结果的iou获得置信度损失的gt
#-------------------------------------------#
#detach 意为分离,对某个张量调用函数 d e t a c h ( ) \rm detach()detach() 的作用是返回一个 T e n s o r \rm TensorTensor,它和原张量的数据相同,但 r e q u i r e s _ g r a d = F a l s e \rm requires\_grad=Falserequires_grad=False,也就意味着 d e t a c h ( ) \rm detach()detach() 得到的张量不会具有梯度。这一性质即使我们修改其 r e q u i r e s _ g r a d \rm requires\_gradrequires_grad 属性也无法改变。
# clamp()函数的功能将输入input张量每个元素的值压缩到区间 [min,max],并返回结果到一个新张量。
tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * iou.detach().clamp(0).type(tobj.dtype) # iou ratio
#-------------------------------------------#
# 计算匹配上的正样本的分类损失
#-------------------------------------------#
selected_tcls = targets[i][:, 1].long()
#torch.full_like 返回一个形状与input相同且值全为fill_value的张量
t = torch.full_like(prediction_pos[:, 5:], self.cn, device=device) # targets
t[range(n), selected_tcls] = self.cp
cls_loss += self.BCEcls(prediction_pos[:, 5:], t) # BCE
#-------------------------------------------#
# 计算目标是否存在的置信度损失
# 并且乘上每个特征层的比例
#-------------------------------------------#
obj_loss += self.BCEobj(prediction[..., 4], tobj) * self.balance[i] # obj loss
#-------------------------------------------#
# 将各个部分的损失乘上比例
# 全加起来后,乘上batch_size
#-------------------------------------------#
box_loss *= self.box_ratio
obj_loss *= self.obj_ratio
cls_loss *= self.cls_ratio
bs = tobj.shape[0]
loss = box_loss + obj_loss + cls_loss
return loss
def xywh2xyxy(self, x):
# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2]
y = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def box_iou(self, box1, box2):
# https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
"""
Return intersection-over-union (Jaccard index) of boxes.
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
Arguments:
box1 (Tensor[N, 4])
box2 (Tensor[M, 4])
Returns:
iou (Tensor[N, M]): the NxM matrix containing the pairwise
IoU values for every element in boxes1 and boxes2
"""
def box_area(box):
# box = 4xn
return (box[2] - box[0]) * (box[3] - box[1])
area1 = box_area(box1.T)
area2 = box_area(box2.T)
# inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
inter = (torch.min(box1[:, None, 2:], box2[:, 2:]) - torch.max(box1[:, None, :2], box2[:, :2])).clamp(0).prod(2)
return inter / (area1[:, None] + area2 - inter) # iou = inter / (area1 + area2 - inter)