访问【WRITE-BUG数字空间】_[内附完整源码和文档]
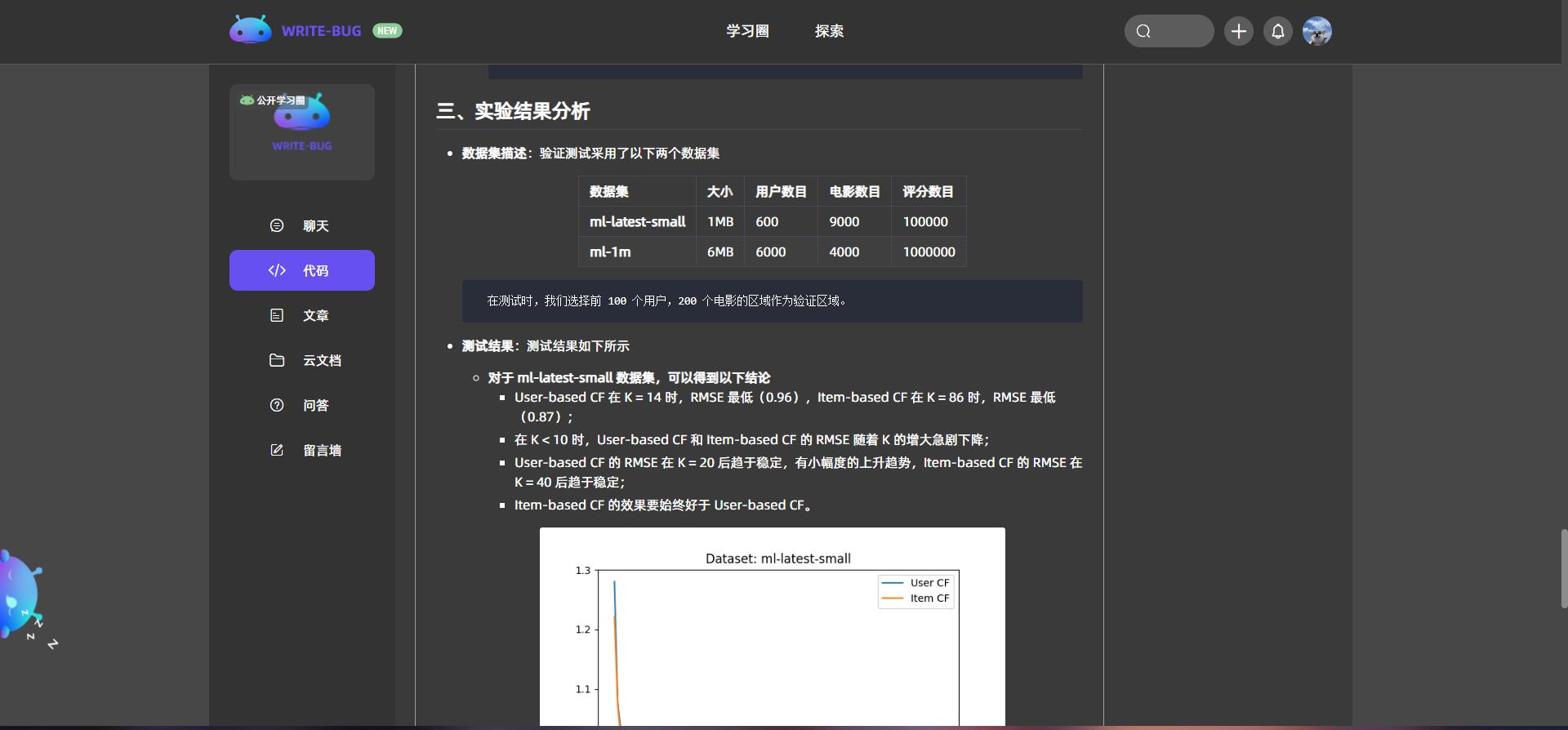
本次实验实现了基于用户和基于项的协同滤波算法,并在 Movielens 两个较小的数据集上进行了测试,测试采用 RMSE 进行评估
一、问题简述
1.1 推荐系统问题
推荐系统问题旨在用户推荐相关项,项可以是用户未观看过的电影、书籍,未访问过的网站,可以是任何可以购买的产品,实现一种个性化的推荐。
推荐系统可以总结为以下模型: Utility Function: u : X × S → R \text{Utility Function: } u: X \times S \to R Utility Function: u:X×S→R 其中, X X X 是用户的集合, S S S 是项的集合, R R R 是用户对项评分的集合,并且是关于项的有序集。
推荐系统问题主要的问题为:如何为矩阵收集已知的评级,如何从已知的评级中推断未知的评级,如何评估推断的好坏。收集评分可以通过显式收集用户的评分,也可以通过学习用户的行为预测评分;推断未知评分可以使用基于内容、协同相关、基于隐因子(矩阵分解)、基于深度模型的模型甚至混合模型等;评估推断的好坏时可以选择在评分表中划分一块区域用于测试,计算平方根误差(RMSE),Top K 的精确度等。
1.2 协同滤波算法
基于用户的协同滤波算法
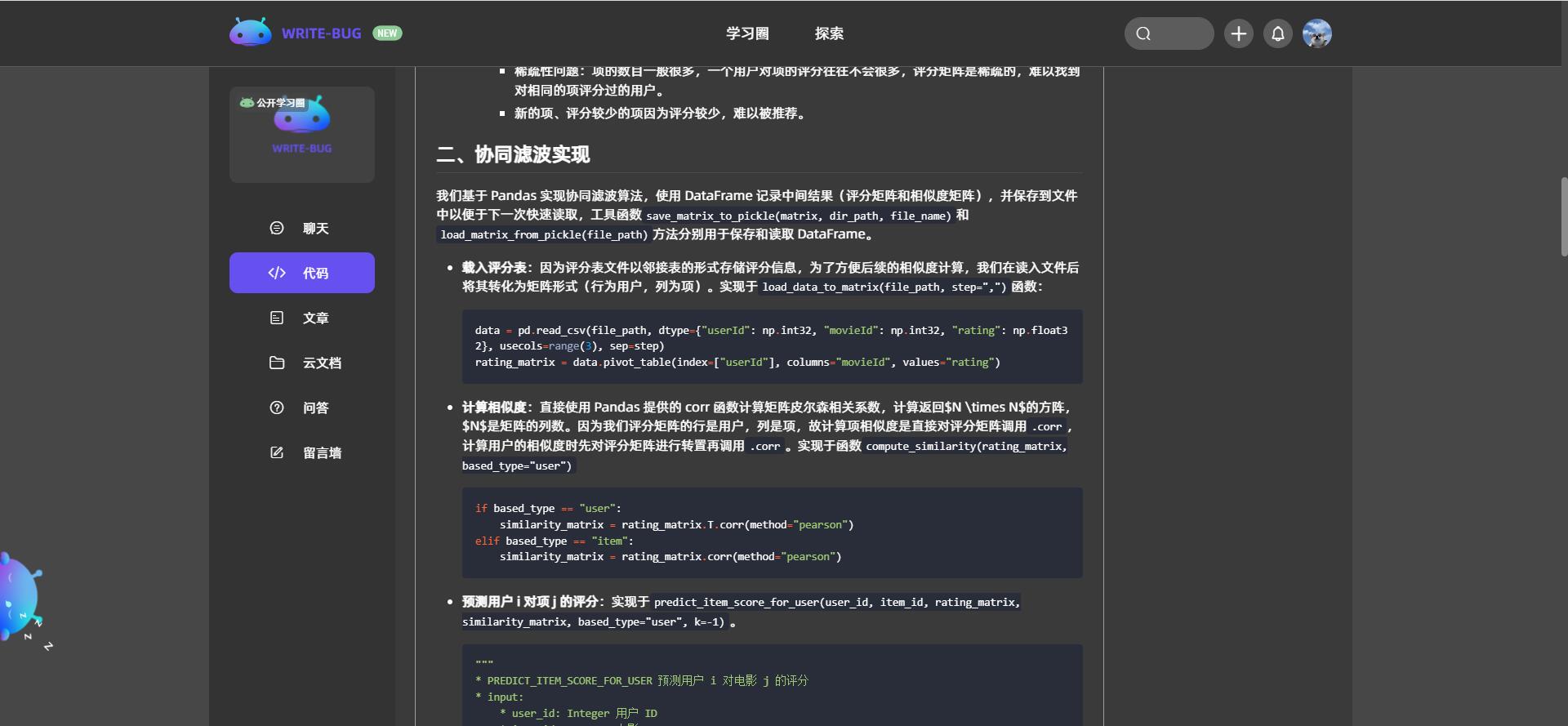
第一步:读取用户-项的评分矩阵 R R R。
第二步:跟据评分矩阵计算用户相似度矩阵 S U S_U SU,在计算相似度时我们选择皮尔森相关系数。我们可以将计算出的评分矩阵保存在文件中,以免下次重复计算。
第三步:假定我们要预测用户 u u u 给项 i i i 的评分。首先找到于目标用户最相似的 K 个用户 U s i m U_{sim} Usim,并且这些用户对项 i i i 有评分记录,根据以下公式计算预测评分: r u , i = ∑ v ∈ U s i m s u , v r v , i ∑ v ∈ U s i m s u , v r_{u,i} = \frac{\sum_{v \in U_{sim}} s_{u,v}r_{v,i}}{\sum_{v \in U_{sim}} s_{u,v}} ru,i=∑v∈Usimsu,v∑v∈Usimsu,vrv,i 其中, r u , i r_{u,i} ru,i 指用户 u u u 对项 i i i 的预测评分, s u , v s_{u,v} su,v 指用户 u u u 和用户 v v v 的相似度。
基于项的协同滤波算法
第一步:读取用户-项的评分矩阵 R R R。
第二步:跟据评分矩阵计算用户相似度矩阵 S I S_I SI,在计算相似度时我们选择皮尔森相关系数。我们可以将计算出的评分矩阵保存在文件中,以免下次重复计算。
第三步:假定我们要预测用户 u u u 给项 i i i 的评分。首先找到于目标项最相似的 K 个项 I s i m I_{sim} Isim,并且用户 u u u 对这些项有评分记录,根据以下公式计算预测评分: r u , i = ∑ j ∈ I s i m s i , j r v , i ∑ j ∈ I s i m s i , j r_{u,i} = \frac{\sum_{j \in I_{sim}} s_{i,j}r_{v,i}}{\sum_{j \in I_{sim}} s_{i,j}} ru,i=∑j∈Isimsi,j∑j∈Isimsi,jrv,i 其中, r u , i r_{u,i} ru,i 指用户 u u u 对项 i i i 的预测评分, s i , j s_{i,j} si,j 指项 i i i 和项 j j j 的相似度。
协同滤波算法的评价
适用场景:
基于用户的协同滤波算法:具备更强的社交特性,适用于用户少物品多,时效性较强的场景。比如新闻、博客、微内容推荐场景。此外基于用户的协同滤波算法能够为用户发现新的兴趣爱好。
基于项的协同滤波算法:更适用于兴趣变化较为稳定的应用,更接近于个性化的推荐,适合物品少用户多,用户兴趣固定持久,物品更新速度不是太快的场合,比如电影推荐。
协同滤波算法的优点:适用于任何类型的项,不需要特征选择
协同滤波算法的缺点:
冷启动问题:对于基于用户的协同滤波算法,需要积累足够多的用户,并且用户有一定评分时才能找到一个用户的相似用户,而基于项的协同滤波算法没有此问题。
稀疏性问题:项的数目一般很多,一个用户对项的评分往往不会很多,评分矩阵是稀疏的,难以找到对相同的项评分过的用户。
新的项、评分较少的项因为评分较少,难以被推荐。