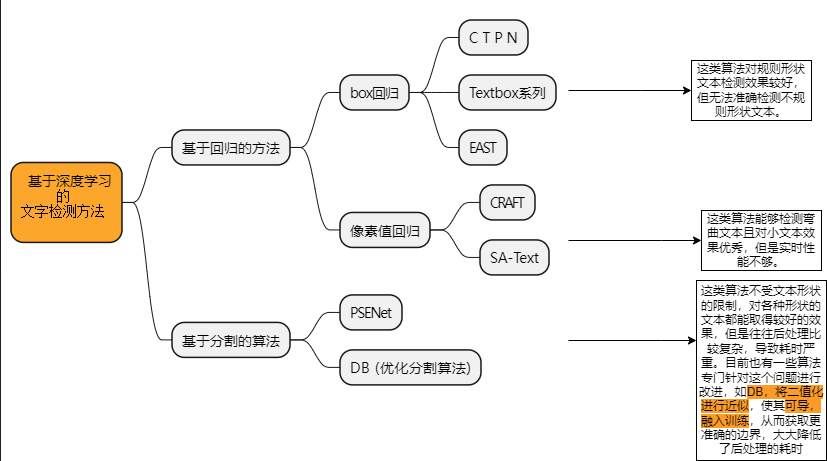
二.关键idea
1.采用垂直anchor回归机制,检测小尺度的文本候选框
2.文本检测的难点在于文本的长度是不固定,可以是很长的文本,也可以是很短的文本.如果采用通用目标检测的方法,将会面临一个问题:**如何生成好的text proposal**.针对上述问题,作者提出了一个vertical anchor的方法,具体的做法是只预测文本的竖直方向上的位置,水平方向的位置不预测。与faster rcnn中的anchor类似,但是不同的是,vertical anchor的宽度都是固定好的了,论文中的大小是16个像素。而高度则从11像素到273像素(每次除以0.7)变化,总共10个anchor.
3.采用RNN循环网络将检测的小尺度文本进行连接,得到文本行.
4.采用CNN+RNN端到端的训练方式,支持多尺度和多语言,避免后处理
CTPN通过CNN和BLSTM学到一组“空间 + 序列”特征后,在"FC"卷积层后接入RPN网络。这里的RPN与Faster R-CNN类似,分为两个分支:
1.左边分支用于bounding box regression。由于fc feature map每个点配备了10个Anchor,同时只回归中心y坐标与高度2个值,所以rpn_bboxp_red有20个channels
2.右边分支用于Softmax分类Anchor
具体RPN网络与Faster R-CNN完全一样,所以不再介绍,只分析不同之处。
六.竖直Anchor定位文字位置
由于CTPN针对的是横向排列的文字检测,所以其采用了一组(10个)等宽度的Anchors,用于定位文字位置。Anchor宽高为:
需要注意,由于CTPN采用VGG16模型提取特征,那么conv5 feature map的宽高都是输入Image的宽高的1/16。
同时fc与conv5 width和height都相等。
如图6所示,CTPN为fc feature map每一个点都配备10个上述Anchors。
这样设置Anchors是为了:
保证在x方向上,Anchor覆盖原图每个点且不相互重叠。
不同文本在y方向上高度差距很大,所以设置Anchors高度为11-283,用于覆盖不同高度的文本目标。
多说一句,我看还有人不停的问Anchor大小为什么对应原图尺度,而不是conv5/fc特征尺度。这是因为Anchor是目标的候选框,经过后续分类+位置修正获得目标在原图尺度的检测框。那么这就要求Anchor必须是对应原图尺度!除此之外,如果Anchor大小对应conv5/fc尺度,那就要求Bounding box regression把很小的框回归到很大,这已经超出Regression小范围修正框的设计目的。
获得Anchor后,与Faster R-CNN类似,CTPN会做如下处理:
Softmax判断Anchor中是否包含文本,即选出Softmax score大的正Anchor
Bounding box regression修正包含文本的Anchor的中心y坐标与高度。
注意,与Faster R-CNN不同的是,这里Bounding box regression不修正Anchor中心x坐标和宽度。具体回归方式如下: