文章目录
1. 前言
本周开始看模型篇,本周目标:CTPN,RRPN,DMPNet,EAST,冲鸭!!
第一篇,CTPN(Connectionist Text Proposal Network),其实是基于Faster R-CNN改进的,将RPN的体系结构扩展到文本识别上面,达到了state-of-art水平。
2. 实现
2.1 关键idea
1.开发了一种锚(anchor)回归机制,可以联合预测每个文本提案的垂直位置和文本/非文本得分,从而获得极好的定位精度;
2.RNN网络内递推机制,它优雅地在卷积特征映射中处理顺序文本建议;
3.CNN+RNN无缝集成,以满足文本序列的本质,形成统一的端到端可培训模型。能够在一个进程中处理多尺度和多语言的文本,避免了进一步的后过滤或细化。
2.2 模型结构

1.用VGG16的前5个Conv stage(到conv5)得到feature map(WxHxC);
2.在Conv5的feature map的每个位置上取3x3xC的窗口的特征,这些特征将用于预测该位置k个anchor对应的类别信息,位置信息;
3.将每一行的所有窗口对应的3x3xC的特征(Wx3x3xC)输入到RNN(BLSTM)中,得到Wx256的输出;
4.将RNN的Wx256输入到512维的fc层;
5.fc层特征输入到三个分类或者回归层中。第二个2k scores 表示的是k个anchor的类别信息(是字符或不是字符)。第一个2k vertical coordinate和第三个k side-refinement是用来回归k个anchor的位置信息。2k vertical coordinate表示的是bounding box的高度和中心的y轴坐标(可以决定上下边界),k个side-refinement表示的bounding box的水平平移量。这边注意,只用了3个参数表示回归的bounding box,因为这里默认了每个anchor的width是16,且不再变化(VGG16的conv5的stride是16)。回归出来的box如上图a中那些红色的细长矩形,它们的宽度是一定的;
6.用简单的文本线构造算法,把分类得到的文字的proposal(图b中的细长的矩形)合并成文本线。
2.3 具体细节
1.检测小尺度文本框(Detecting Text in Fine-scale Proposals)
- k个anchor的设置:宽度固定为16,高度范围为11~273像素(每次除以0.7)
- 预测k个垂直坐标:
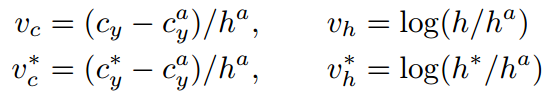
带*的都是Ground Truth;带a的都是anchor的;啥也不带的是预测的。

左边是RPN的检测框,小尺度检测提议的检测框,显然右边更加精细,更适合文本检测。
2.循环连接文本框(Recurrent Connectionist Text Proposals)
- RNN类型:双向LSTM(可以利用文本序列的上下文信息,使得检测的文本行更加精确,尽可能减少误检),每个LSTM有128个隐含层
- RNN输入:每个滑动窗口的3x3xC的特征(可以拉成一列),同一行的窗口的特征形成一个序列
- RNN输出:每个窗口对应256维特征

上面的:没用RNN
下面的:用了RNN
对比可知,用了RNN之后,图1减少了误检率;图2图3根据上下文检测到了没用RNN没检测到的文本。
3.文本行边细化(Side-refinement)
- 只接受分数大于0.7的提议。
- 文本线构造算法:
主要思想:每两个相近的proposal组成一个pair,合并不同的pair直到无法再合并为止。
判断两个proposal,Bi和Bj组成pair的条件:Bj->Bi, 且Bi->Bj。
Bj->Bi条件1:Bj是Bi的邻居中距离Bi最近的,且该距离小于50个像素
Bj->Bi条件2:Bj和Bi的vertical overlap大于0.7
- 引入文本行的Side-refinement
由于text proposal的宽度是固定16,这可能造成定位不准,部分text proposal被丢弃等。
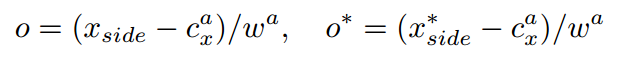
xside是距离当前锚点水平位置最近的x坐标,带*的xside是x轴的Ground Truth,cax是锚点的x轴中心,wa是固定值16。

上图是对比,红色框是加入了side-refinement后,黄色虚线是没加。不同颜色代表不同text/non-text分数。
3. 训练
1.训练标签labels
- 正样本:
与真值IoU大于0.7的anchor作为正样本
与真值IoU最大的那个anchor也定义为正样本
- 负样本:
与真值IoU小于0.5的anchor定义为负样本
2.训练成本loss
- 文本/非文本采用softmax
- 垂直坐标采用L1回归
- side-refinement采用L1回归
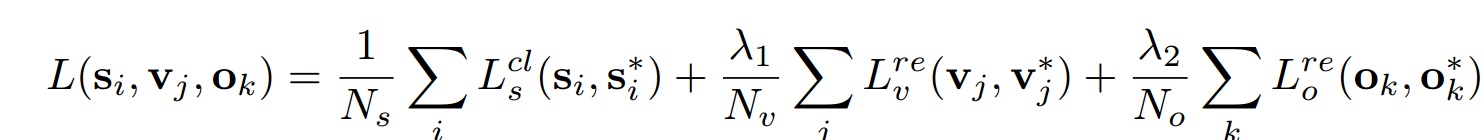
其中 。
3.训练参数
- 对于每一张训练图片,总共抽取128个样本,64正64负,如果正样本不够就用负样本补齐;
- 训练图片都将短边放缩到600像素,并且保持原图的缩放比;
- RNN层和输出层采用随机均值为0,方差为1的参数进行初始化;
- 在训练时CNN的前两层参数固定。
4. 结果
- 每张图0.14s

5. 参考资料
1.《Detecting Text in Natural Image with Connectionist Text Proposal Network》
2.论文翻译
3.https://blog.csdn.net/zchang81/article/details/78873347
4.https://zhuanlan.zhihu.com/p/37363942
5.算法原理解释
6.caffe实现代码
7.tensorflow实现代码