AlexNet包含6千万个参数和65万个神经元,包含了5个卷积层,其中有几层后面跟着最大池化(max-pooling)层,以及3个全连接层,最后还有一个1000路的softmax层。为了加快训练速度,AlexNet使用了Relu非线性激活函数以及一种高效的基于GPU的卷积运算方法。为了减少全连接层的过拟合,AlexNet采用了最新的正则化方法“dropout”,该方法被证明非常有效。
总结一下AlexNet的主要贡献:
1、2路GPU实现,加快了训练速度
2、Relu非线性激活函数,减少训练时间,加快训练速度
3、为了减少过拟合,使用了“dropout”。
4、5个卷积层+3个全连接层,去除任何卷积层,导致性能变差。
实验所用数据集:ImageNet 采用其子集1000种每种1000张,总共120万训练集、15万测试集和5万验证集。给定一幅矩形图像,首先重新调整图像使得短边长度为256,然后裁剪出中央256x256 的区域。除了将图像减去训练集的均值图像(训练集和测试集都减去训练集的均值图像),本文不做任何其他图像预处理。
AlexNet整体结构
第一层卷积层使用96个大小为11x11x3的卷积核对224x224x3的输入图像以4个像素为步长(这是核特征图中相邻神经元感受域中心之间的距离)进行滤波。第二层卷积层将第一层卷积层的输出(经过响应归一化和池化)作为输入,并使用256个大小为5x5x48的核对它进行滤波。第三层、第四层和第五层的卷积层在没有任何池化或者归一化层介于其中的情况下相互连接。第三层卷积层有384个大小为3x3x256的核与第二层卷积层的输出(已归一化和池化)相连。第四层卷积层有384个大小为3x3x192的核(两部分),第五层卷积层有256个大小为3x3x192 的核(两部分),最后经过。每个全连接层有4096个神经元。
最大池化层为3x3,步长为2(第一、二和五层之后有最大池化层),第6、7层后l连接dropout层。

文章输入是224x224x3,但227 x227 x3更好,(n-f)/s+1=(227-11)/ 4+1=55;
最大池化将图片降维
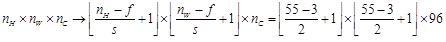
AlexNet代码实现
def create(self):
"""Create the network graph."""
# 1st Layer: Conv (w ReLu) ->Lrn -> Pool
conv1 = conv(self.X,11, 11, 96, 4, 4, padding='VALID', name='conv1')
norm1 = lrn(conv1, 2,1e-05, 0.75, name='norm1')
pool1 =max_pool(norm1, 3, 3, 2, 2, padding='VALID', name='pool1')
# 2nd Layer: Conv (w ReLu) -> Lrn -> Pool with 2 groups
conv2 = conv(pool1, 5,5, 256, 1, 1, groups=2, name='conv2')
norm2 = lrn(conv2, 2,1e-05, 0.75, name='norm2')
pool2 =max_pool(norm2, 3, 3, 2, 2, padding='VALID', name='pool2')
# 3rd Layer: Conv (w ReLu)
conv3 = conv(pool2, 3, 3, 384, 1, 1,name='conv3')
# 4th Layer: Conv (w ReLu)splitted into two groups
conv4 = conv(conv3, 3,3, 384, 1, 1, groups=2, name='conv4')
# 5th Layer: Conv (w ReLu) ->Pool splitted into two groups
conv5 = conv(conv4, 3, 3, 256, 1, 1,groups=2, name='conv5')
pool5 =max_pool(conv5, 3, 3, 2, 2, padding='VALID', name='pool5')
# 6th Layer: Flatten -> FC (wReLu) -> Dropout
flattened =tf.reshape(pool5, [-1, 6*6*256])
fc6 = fc(flattened, 6*6*256, 4096,name='fc6')
dropout6 =dropout(fc6, self.KEEP_PROB)
# 7th Layer: FC (w ReLu) ->Dropout
fc7 = fc(dropout6,4096, 4096, name='fc7')
dropout7 =dropout(fc7, self.KEEP_PROB)
# 8th Layer: FC and returnunscaled activations
self.fc8 =fc(dropout7, 4096, self.NUM_CLASSES, relu=False, name='fc8')
每一个卷积后都跟着一个Relu激活函数。
def conv(x, filter_height, filter_width, num_filters, stride_y,stride_x, name,
padding='SAME',groups=1):
"""Create aconvolution layer.
Adapted from:https://github.com/ethereon/caffe-tensorflow
"""
# Get number of inputchannels
input_channels =int(x.get_shape()[-1])
# Create lambda functionfor the convolution
convolve = lambda i, k:tf.nn.conv2d(i, k,
strides=[1, stride_y, stride_x, 1],
padding=padding)
withtf.variable_scope(name) as scope:
# Create tf variablesfor the weights and biases of the conv layer
weights =tf.get_variable('weights', shape=[filter_height,
filter_width,
input_channels/groups,
num_filters])
biases =tf.get_variable('biases', shape=[num_filters])
if groups == 1:
conv = convolve(x,weights)
# In the cases of multiplegroups, split inputs & weights and
else:
# Split input andweights and convolve them separately
input_groups =tf.split(axis=3, num_or_size_splits=groups, value=x)
weight_groups =tf.split(axis=3, num_or_size_splits=groups,
value=weights)
output_groups = [convolve(i, k) for i, kin zip(input_groups, weight_groups)]
# Concat the convolvedoutput together again
conv =tf.concat(axis=3, values=output_groups)
# Add biases
bias = tf.reshape(tf.nn.bias_add(conv, biases),tf.shape(conv))
# Apply relu function
relu = tf.nn.relu(bias, name=scope.name)
return relu
定义全连接层
def fc(x, num_in, num_out, name, relu=True):
"""Create afully connected layer."""
withtf.variable_scope(name) as scope:
# Create tf variablesfor the weights and biases
weights =tf.get_variable('weights', shape=[num_in, num_out],
trainable=True)
biases =tf.get_variable('biases', [num_out], trainable=True)
# Matrix multiplyweights and inputs and add bias
act =tf.nn.xw_plus_b(x, weights, biases, name=scope.name)
if relu:
# Apply ReLu nonlinearity
relu = tf.nn.relu(act)
return relu
else:
return act
定义最大池化层
def max_pool(x, filter_height, filter_width, stride_y, stride_x,name,
padding='SAME'):
"""Create amax pooling layer."""
return tf.nn.max_pool(x,ksize=[1, filter_height, filter_width, 1],
strides=[1, stride_y, stride_x, 1],
padding=padding, name=name)
定义lrn
def lrn(x, radius, alpha, beta, name, bias=1.0):
"""Create alocal response normalization layer."""
returntf.nn.local_response_normalization(x, depth_radius=radius,
alpha=alpha,beta=beta,
bias=bias, name=name)
定义dropout
def dropout(x, keep_prob):
"""Create adropout layer."""
return tf.nn.dropout(x,keep_prob)