ImageNet Classification with Deep Convolutional Networks(AlexNet)
论文简述
本文算是深度学习的起源,这篇文章讲述了一种可实现的网络架构,并在ILSVRC-2012挑战赛中优势突出,top-5 错误率达到15.4%,远远超过第二名26.2%,证实了CNN网络结构的可实现性及高优越性。此外,文章中还提到了许多现在仍在使用的技术,如dropout,数据扩增,ReLU激活函数等等。
论文要点
CNN的优势
CNN网络结构的容量可以通过改变深度和广度来控制,它们还可以对图像的性质(即统计的平稳性和像素依赖性的局部性)作出强有力且最正确的假设,因此相比全连接,CNN需要更少的参数和连接来实现。【CNN主要特征是局部感受野和权值共享】
ReLU-非饱和神经元(non-saturating)
- non-saturating neurons = 没有被挤压(到一个特定的区间)处理过的值
relu:input neurons的值,要么变0, 要么保持原值(无挤压,无最大最小值限制)
leaky_relu:input neurons的值, 要么按照某比例缩小,要么保持原值(无挤压,无最大最小值限制) - saturating neurons = 被挤压(到一个特定的区间)过的值
sigmoid: input neurons的值会被挤压到[0,1]的区间
tanh:input neurons的值会被挤压到[-1,1]的区间 - 为什么要用relu这样的能生成non-saturating neurons的non-linear activations, 而不用生成saturating neurons的sigmoid或tanh?
- 规避vanishing, exploding of gradients 带来的gradient值过大过小,不能继续进行后向传播,导致训练效率低下
- 论文中提到,使用了RELU后,训练效率大幅提升
转自知乎:https://www.zhihu.com/question/264163033/answer/277481519

论文提出像ReLU这样的非饱和非线性激活函数比饱和型非线性训练效率大幅度提升。
局部响应归一化(Local Response Normalization,LRN)
局部响应归一化从实际神经元中发现的侧抑制(被激活的神经元抑制相邻的神经元)受到启发,从而对局部神经元的活动创建竞争机制,使得响应较大的值相对更大,提高模型的泛化能力。
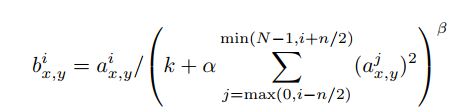
需要注意的是,公式中的i是指第i个kernel,也就是说是在同一位置的不同kernel之间进行抑制,公式即为当前kernel中的特征除以相邻位置的特征平方和,从而抑制小的响应,扩张大的响应。
重叠池化(Overlapping Pooling)
池化时,池化步长为s(隔s选定一个池化单元),池化核大小为z(每个单元汇总一个以池单元位置为中心的z×z大小的邻域),文章提出使步长小于池化核,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。此外,本文还采用了最大池化,避免平均池化的模糊化效果。
数据扩充
- 图像平移和水平反射
随机从256×256的图像中截取224×224大小的图像,并进行水平反射,使训练集变成原来的2048倍,且训练样本之间是高度相互依赖的。训练时截取了五个这样的图像(一个中心图像和四个角落图像)以及他们的水平反射,最后在softmax层将预测结果进行求均值 - 改变RGB通道的强度
将通过PCA找到的主分量(特征向量)乘以相对应倍数后加起来,其倍数大小与 相应的特征值乘以从平均零和标准偏差为0.1的高斯中提取的随机变量 的结果成比例。其中的随机变量α在每次对应的图像需要训练时再重新提取
数据扩充既增加了训练数据的量级,又使网络学习到物体统一性对位置尺寸、光照强度及颜色变化具有不变性
Dropout
使每个隐藏神经元的输出以0.5的概率设置为0,被drop掉的神经元前向传播和后向传播都不参与,每次神经网络的结构都不相同,所以也可以看做是另一种的模型融合。此外,神经元也不可以依赖其他神经元的活跃来完成网络,增加了网络结构的鲁棒性。在测试阶段,则需要将输出结果乘以0.5。dropout会加倍训练收敛所需的迭代次数。
数据扩充和dropout用以防止网络过拟合
其他细节
随机梯度下降
权重衰减以0.0005(可以降低训练误差)
当验证错误率不再随当前学习率提高而提高时,采用的启发式方法是将学习率除以10。
采用双GPU并行处理
网络构架

第二、四、五层的卷积层只与处在同一GPU上的前一层网络的卷积核相连接,第三层的卷积层与第二层全部的卷积核相连接,局部响应层跟在第一和第二个卷积层后,最大池化层跟在相应归一化以及第五个卷积层后边,ReLUctant应用在所有卷积层及连接层后面。