Part1 ResNet
1 论文阅读
已知网络层数越深越难训练,为解决这个问题,该论文提出了残差学习模块,这种结构模块容易优化,并且能在深度很深的情况下达到较高的准确率。
深层网络的训练主要面临两个问题,一个是梯度消失/梯度爆炸,另一个是网络退化,前者可以使用归一化操作、调整优化器和学习率等方式解决,而后者使得网络在层数加深时训练效果达到饱和,并且这种网络退化不是由于过拟合引起的。
因此,本论文从恒等变换下手,提出了残差学习模块来解决这种深层网络下的网络退化问题,使得深层网络中的结构模块既能进行非线性变换得到更好的训练效果,也能进行恒等变换来保持当前足够好的训练效果。
ResNet主要有以下几个特点:
- 残差表示
- 捷径连接(实现恒等变换)
2 网络结构
网络中的亮点:
- 深层网络结构(突破1000)
- residual模块
- 丢弃Dropout,使用Batch Normalization加速训练
传统的深层网络结构面临的问题:
- 梯度消失或梯度爆炸
- 退化问题(degradation problem)
residual结构:

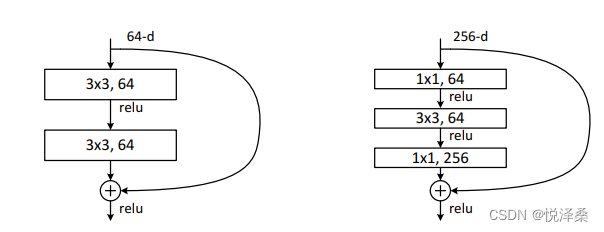
左边的残差结构用于较浅层的网络(ResNet34),右边的BottleNeck用于ResNet50/101/152,主分支与shortcut的输出特征矩阵shape必须相同。
BottleNeck中的1*1卷积核用于升降维,先降维再升维,有利于减少参数量。
ResNet结构示意图中的虚线shortcut表示这里的残差结构有升维,对应的shortcut中添加了用于升维的1*1卷积核。
原论文的ResNet与PyTorch官方实现的ResNet有区别:原论文中的虚线残差结构的主分支上,1*1卷积步长为2,3*3卷积的步长为1;而PyTorch官方实现中,1*1卷积步长为1,3*3卷积的步长为2,略微提升了准确率。
Batch Normalization(BN):调整一个Batch下的feature map满足均值为0,方差为1的分布规律,均值和方差都是向量,维度和深度对应,在正向传播中统计得到,γ和β在反向传播过程中训练得到。(Batch Normalization详解以及pytorch实验_太阳花的小绿豆的博客-CSDN博客_batchnormalization pytorch)

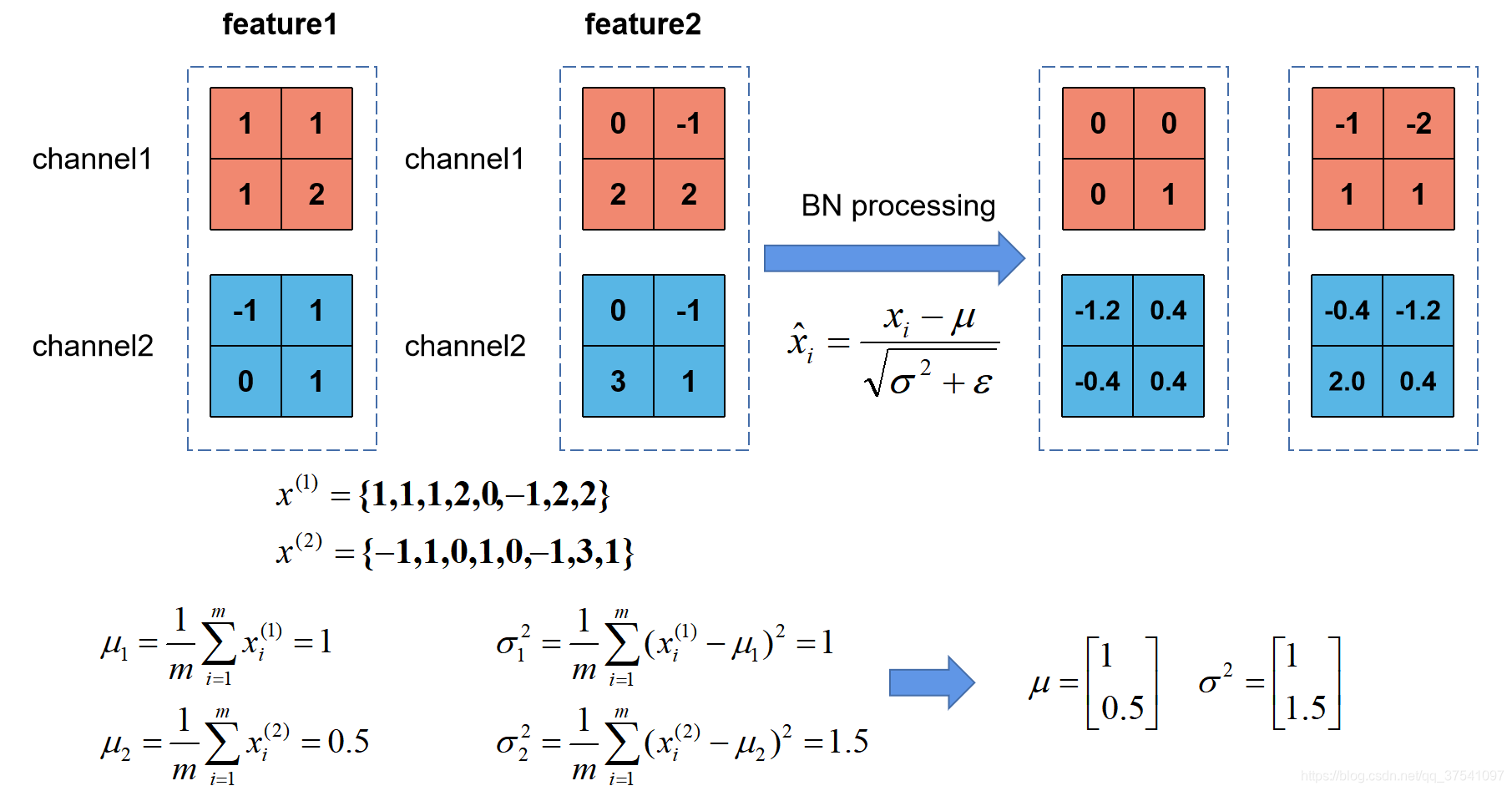
使用BN时要注意:
- 训练时tranning=True,验证时trainning=False,在pytorch中可通过创建模型的model.train()和model.eval()方法控制
- batch size设置的越大,均值和方差越接近整个训练集的均值和方差
- 建议将bn层放在卷积层(Conv)和激活层(例如Relu)之间,且卷积层不要使用偏置bias
迁移学习的优势:能快速训练出较好的效果,即使数据集较小也能达到理想效果(要留意预训练处理方法)
迁移学习的常见方式:载入权重后训练所有参数;载入权重后只训练最后几层参数;载入权重后添加全连接层
3 基于PyTorch搭建ResNet
from torch.nn.modules.batchnorm import BatchNorm2d
import torch
import torch.nn as nn
# 浅层ResNet的残差结构
class BasicBlock(nn.Module):
expansion = 1 # 主分支中卷积核个数是否发生变化
def __init__(self,in_channel,out_channel,stride=1,downsample=None):
super(BasicBlock,self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel,out_channels=out_channel,
kernel_size=3,stride=stride,padding=1,bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel,out_channels=out_channel,
kernel_size=3,stride=1,padding=1,bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self,x):
identity = x
# 如果传入了下采样,就是虚线的残差块
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
# 深层ResNet的残差结构
class Bottleneck(nn.Moudule):
expansion = 4
def __init__(self,in_channel,out_channel,stride=1,downsample=None):
super(Bottleneck,self).__init__()
# 降维
self.conv1 = nn.Conv2d(in_channels=in_channel,out_channels=out_channel,
kernel_size=1,stride=1,bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.conv2 = nn.Conv2d(in_channels=out_channel,out_channels=out_channel,
kernel_size=3,stride=stride,padding=1,bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
# 升维
self.conv3 = nn.Conv2d(in_channels=out_channel,out_channels=out_channel*self.expansion,
kernel_size=1,stride=1,bias=False)
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self,x):
identity = x
# 如果传入了下采样,就是虚线的残差块
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
# ResNet
class ResNet(nn.Module):
def __init__(self,block,blocks_num,num_classes=1000,include_top=True):
super(ResNet,self).__init__()
self.include_top = include_top
self.in_channel = 64
self.conv1 = nn.Conv2d(3,self.in_channel,kernel_size=7,stride=2,padding=3,bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
self.layer1 = self._make_layer(block,64,blocks_num[0])
self.layer2 = self._make_layer(block,128,blocks_num[1],stride=2)
self.layer3 = self._make_layer(block,256,blocks_num[2],stride=2)
self.layer4 = self._make_layer(block,512,blocks_num[3],stride=2)
# 如果包含全连接层
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(512*block.expansion,num_classes)
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight,mode='fan_out',nonlinearity='relu')
def _make_layer(self,block,channel,block_num,stride=1):
downsample = None
if stride!=1 or self.in_channel!=channel*block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel,channel*block.expansion,kernel_size=1,stride=stride,bias=False),
nn.BatchNorm2d(channel*block.expansion)
)
layers = []
layers.append(block(self.in_channel,channel,downsample=downsample,stride=stride))
self.in_channel = channel*block.expansion
for _ in range(1,block_num):
layers.append(block(self.in_channel,channel))
return nn.Sequential(*layers) # 非关键字参数
def forward(self,x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x,1)
x = self.fc(x)
return x
def resnet18(num_classes=1000,include_top=True):
return ResNet(BasicBlock,[2,2,2,2],num_classes=num_classes,include_top=include_top)
def resnet34(num_classes=1000,include_top=True):
return ResNet(BasicBlock,[3,4,6,3],num_classes=num_classes,include_top=include_top)
def resnet50(num_classes=1000,include_top=True):
return ResNet(Bottleneck,[3,4,6,3],num_classes=num_classes,include_top=include_top)
def resnet101(num_classes=1000,include_top=True):
return ResNet(Bottleneck,[3,4,23,3],num_classes=num_classes,include_top=include_top)
def resnet152(num_classes=1000,include_top=True):
return ResNet(Bottleneck,[3,8,36,3],num_classes=num_classes,include_top=include_top)
Part2 ResNeXt
1 论文阅读
该论文在ResNet的基础上,提出了“基数(转换集的大小)”这个概念,并指出,“基数”是除了网络深度和宽度以外另一个影响训练效果的重要因素,并且增加“基数”这个操作比增加网络的深度和宽度更有效率,并且,一昧增加超参数的规模并不总会提升训练效果,因此超参数规模的增大会使训练难度和不确定性增加,相比之下,巧妙的网络结构设计能比单纯增加现有网络的深度取得更好的效果。
从这个角度出发,该论文改进了ResNet的网络结构,将多个相同结构的卷积堆叠起来作为残差块,并认为这种结构能更好地避免过拟合问题。残差块的输入会先分割成大小相等的若干部分,再对每个部分分别进行相同的卷积操作,再将结果整合到一起形成输出。相比于Inception结构,这种结构模块更简洁且更容易实现。
经过实验发现,101层的ResNeXt比200层的ResNet准确率更高,并且复杂度只有后者的一半。ResNeXt的主要特点如下:
- 多分支的卷积网络
- 分组卷积
- 压缩卷积网络
- 加性转换
构造ResNeXt的残差块结构需要遵循以下两个准则:
- 相同大小的spatial map共享超参数
- 每次将spatial map下采样 2 倍时,块的宽度也乘以系数 2
2 网络结构
和ResNet相比,ResNeXt在ResNet的基础上改进了block的结构,主干改为了分组卷积,在计算量相同的情况下,ResNeXt的错误率更低

分组卷积比传统的卷积参数量更少,当输出维度与输入维度相同时,相当于对输入特征矩阵的每一个channel分配了一个channel为1的卷积核进行卷积。
以下三种形式在计算上完全等价。

ResNet50和ResNeXt50:

只有block层数大于等于3的时候,才能搭建出有意义的分组卷积的block,因此这种改进对浅层的ResNet作用不大
3 基于PyTorch搭建ResNet
代码链接:(colab)基于PyTorch搭建ResNeXt
# 基于PyTorch搭建ResNeXt
from torch.nn.modules.batchnorm import BatchNorm2d
import torch
import torch.nn as nn
# 浅层的残差结构(不变)
class BasicBlock(nn.Module):
expansion = 1 # 主分支中卷积核个数是否发生变化
def __init__(self,in_channel,out_channel,stride=1,downsample=None):
super(BasicBlock,self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel,out_channels=out_channel,
kernel_size=3,stride=stride,padding=1,bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel,out_channels=out_channel,
kernel_size=3,stride=1,padding=1,bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self,x):
identity = x
# 如果传入了下采样,就是虚线的残差块
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
# 深层的残差结构
class Bottleneck(nn.Moudule):
expansion = 4
def __init__(self,in_channel,out_channel,stride=1,downsample=None,groups=1,width_per_group=64):
super(Bottleneck,self).__init__()
width = int(out_channel*(width_per_group/64.))*groups
# 降维
self.conv1 = nn.Conv2d(in_channels=in_channel,out_channels=width,
kernel_size=1,stride=1,bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.conv2 = nn.Conv2d(in_channels=width,out_channels=width,groups=groups,
kernel_size=3,stride=stride,padding=1,bias=False)
self.bn2 = nn.BatchNorm2d(width)
# 升维
self.conv3 = nn.Conv2d(in_channels=width,out_channels=out_channel*self.expansion,
kernel_size=1,stride=1,bias=False)
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self,x):
identity = x
# 如果传入了下采样,就是虚线的残差块
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
# ResNet
class ResNeXt(nn.Module):
def __init__(self,block,blocks_num,num_classes=1000,include_top=True):
super(ResNeXt,self).__init__()
self.include_top = include_top
self.in_channel = 64
self.conv1 = nn.Conv2d(3,self.in_channel,kernel_size=7,stride=2,padding=3,bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
self.layer1 = self._make_layer(block,64,blocks_num[0])
self.layer2 = self._make_layer(block,128,blocks_num[1],stride=2)
self.layer3 = self._make_layer(block,256,blocks_num[2],stride=2)
self.layer4 = self._make_layer(block,512,blocks_num[3],stride=2)
# 如果包含全连接层
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(512*block.expansion,num_classes)
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight,mode='fan_out',nonlinearity='relu')
def _make_layer(self,block,channel,block_num,stride=1):
downsample = None
if stride!=1 or self.in_channel!=channel*block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel,channel*block.expansion,kernel_size=1,stride=stride,bias=False),
nn.BatchNorm2d(channel*block.expansion)
)
layers = []
layers.append(block(self.in_channel,channel,downsample=downsample,
stride=stride,groups=self.groups,width_per_group=self.width_per_group))
self.in_channel = channel*block.expansion
for _ in range(1,block_num):
layers.append(block(self.in_channel,channel,groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers) # 非关键字参数
def forward(self,x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x,1)
x = self.fc(x)
return x
def resnet18(num_classes=1000,include_top=True):
return ResNet(BasicBlock,[2,2,2,2],num_classes=num_classes,include_top=include_top)
def resnet34(num_classes=1000,include_top=True):
return ResNet(BasicBlock,[3,4,6,3],num_classes=num_classes,include_top=include_top)
def resnet50(num_classes=1000,include_top=True):
return ResNet(Bottleneck,[3,4,6,3],num_classes=num_classes,include_top=include_top)
def resnet101(num_classes=1000,include_top=True):
return ResNet(Bottleneck,[3,4,23,3],num_classes=num_classes,include_top=include_top)
def resnet152(num_classes=1000,include_top=True):
return ResNet(Bottleneck,[3,8,36,3],num_classes=num_classes,include_top=include_top)
def resnext50_32_4d(num_classes=1000,include_top=True):
groups = 32
width_per_group = 4
return ResNeXt(Bottleneck,[3,4,6,3],num_classes=num_classes,include_top=include_top,
groups=groups,width_per_group=width_per_group)
def resnext101_32_8d(num_classes=1000,include_top=True):
groups = 32
width_per_group = 8
return ResNeXt(Bottleneck,[3,4,23,3],num_classes=num_classes,include_top=include_top,
groups=groups,width_per_group=width_per_group)
Part3 代码练习:猫狗大战
代码链接:(colab)猫狗大战
dataloader:
data_dir = '/content/drive/MyDrive/Colab Notebooks/cat_dog/'
train_dir = data_dir+'train/'
test_dir = data_dir+'test/'
val_dir = data_dir+'val/'
train_imgs = os.listdir(train_dir)
train_labels = []
normalize = transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
transform = transforms.Compose([transforms.Resize([32,32]),transforms.ToTensor(),normalize])
class CatDogDataset(Dataset):
def __init__(self, root, transform=None):
self.root = root
self.transform = transform
# 正样本
self.imgs = os.listdir(self.root)
self.labels = []
for img in self.imgs:
if img.split('_')[0]=='cat':
self.labels.append(0)
if img.split('_')[0]=='dog':
self.labels.append(1)
def __len__(self):
return len(self.imgs)
def __getitem__(self, index):
label = self.labels[index]
img_dir = self.root + str(self.imgs[index])
img = Image.open(img_dir)
# transform?
if self.transform is not None:
img = self.transform(img)
return img,torch.from_numpy(np.array(label)) # 返回数据+标签LeNet5:
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool1(x)
x = F.relu(self.conv2(x))
x = self.pool2(x)
x = x.view(-1, 32*5*5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x相关参数:

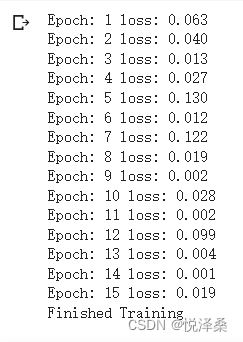
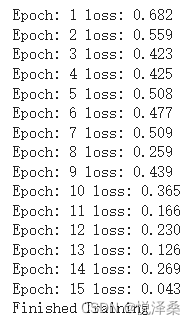
训练(左为ResNet34,右为LeNet5):

生成结果csv文件:

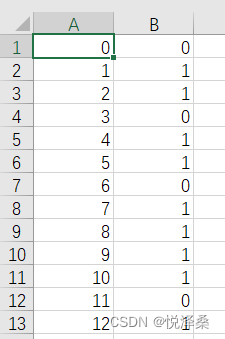
评分结果:

由此可见,在使用相同的优化参数和训练轮数的情况下,ResNet34比LeNet5效果更好。
Part4 思考题
1. Residual learning
设基础的映射是h(x),残差块两个分支的映射分别为f(x)和x,则h(x)=x+f(x),f(x)就是主分支待学习的映射,这种结构将有助于恒等映射的实现和预处理,缓解网络退化问题。当求导算梯度时,就有h'(x)=1+f'(x),这也能缓解梯度消失问题。
2. Batch Normailization 的原理
卷积神经网络包含很多隐含层,每层参数都会随着训练而改变,隐层的输入分布总会变化,使得学习速度降低,激活函数的梯度达到饱和。Normalization是解决该问题的一种思路,但如果Normalization的使用过多,会使训练过程的计算很复杂,过少不容易见效,因此提出了BN,BN是先将数据划分成多个批次,再在每一个批次进行归一化操作。
3. 为什么分组卷积可以提升准确率?即然分组卷积可以提升准确率,同时还能降低计算量,分数数量尽量多不行吗?
根据ResNeXt的论文内容,它指出,分组卷积最初的目的是便于将一个模型同时放在多个GPU上训练,分组卷积能降低计算量,但是几乎没有证据表明分组卷积可以提升准确率,即使在现在我也暂时没有找到相关依据。从ResNet到ResNeXt的改进主要是提出了cardinality这个概念,个人认为,如果分组卷积可以提升准确率,则是因为分组卷积可以进行分组学习,从而学习到更深层次的信息,类似于卷积神经网络和传统全连接层。
分组卷积的分组数量不能过多,过多的分组会使特征提取的很零散,不利于关键特征的提取。