【MySQL入门】(五)Flask使用MySQL存储数据
本文基于MySQL 8.0.29 和 Python 3.8。
1. flask_sqlalchemy简介
Flask-SQLAlchemy 是一个为 Flask 应用增加 SQLAlchemy 支持的扩展,也是一种数据库框架,支持多种数据库后台。它致力于简化在 Flask 中 SQLAlchemy 的使用,提供了有用的默认值和额外的助手来更简单地完成常见任务。无须关心SQL处理细节,通过调用方法操作数据库。这是flask_sqlalchemy的中文文档。
2. 安装pymysql,sqlalchemy,flask_sqlalchemy
pip install pymysql sqlalchemy flask_sqlalchemy
3. 配置一个简单的Flask应用
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = "mysql+pymysql://{}:{}@{}/{}?charset=utf8mb4" \
.format('root','密码','x.x.x.x:3306','数据库名')
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True # 每次请求结束后会自动提交数据库中的变动
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True # 事件系统跟踪修改
db = SQLAlchemy(app) # 实例化数据库对象,它提供访问Flask-SQLAlchemy的所有功能
4. 定义一个类(对应数据库中的表)
class Myuser(db.Model): # 所有模型的基类叫 db.Model,它存储在创建的SQLAlchemy实例上。
#定义表名
__tablename__ = 'myuser'
#定义字段
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=False)
money = db.Column(db.Float, unique=False)
#__repr__()方法显示一个可读字符串,用于调试、测试
def __repr__(self):
return '<Myuser id:{} name:{} money:{}>'.format(self.id,self.name,self.money)
这是一个简单的实例:

常见的 SQLalchemy 列类型
| 类型名称 | python类型 | 描述 |
|---|---|---|
| Integer | int | 常规整形,通常为32位 |
| SmallInteger | int | 短整形,通常为16位 |
| BigInteger | int 或 long | 精度不受限整形 |
| Float | float | 浮点数 |
| Numeric | decimal.Decimal | 定点数 |
| String | str | 可变长度字符串 |
| Text | str | 可变长度字符串,适合大量文本 |
| Unicode | unicode | 可变长度Unicode字符串 |
| Boolean | bool | 布尔型 |
| Date | datetime.date | 日期类型 |
| Time | datetime.time | 时间类型 |
| Interval | datetime.timedelta | 时间间隔 |
| Enum | str | 字符列表 |
| PickleType | 任意Python对象 | 自动Pickle序列化 |
| LargeBinary | str | 二进制 |
常见的 SQLalchemy 列选项
| 可选参数 | 描述 |
|---|---|
| primary_key | 如果设置为True,则为该列表的主键 |
| unique | 如果设置为True,该列不允许相同值 |
| index | 如果设置为True,为该列创建索引,查询效率会更高 |
| nullable | 如果设置为True,该列允许为空。如果设置为False,该列不允许空值 |
| default | 定义该列的默认值 |
5. 删除、创建数据表
下面的操作将对数据库中的所有表产生影响:
# 删除旧表:
db.drop_all()
# 创建新表:
db.create_all()
6. 数据库的增删改查
1.增
user_A = Myuser(id=123, name='user_A', money=66.66)
user_B = Myuser(id=456, name='user_B', money=888.88)
#在将对象写入数据库之前,先将其添加到会话中(类似缓存)
# 插入单个对象
# db.session.add(user_A)
# 插入多个对象
db.session.add_all([user_A, user_B])
#会话提交到数据库后执行操作
db.session.commit()
结果:
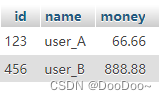
2. 删
db.session.delete(user_B)
db.session.commit()
结果:
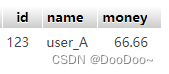
3. 改
user_A.name = 'somebody'
user_A.money= 999
db.session.add(user_A)
db.session.commit()
结果:
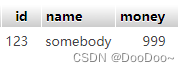
4. 查
Myuser.query.filter_by(id = 123).first()
Myuser.query.filter_by(name = 'somebody').all()

常用的SQLAlchemy查询过滤器
| 过滤器 | 说明 |
|---|---|
| filter() | 把过滤器添加到原查询上,返回一个新查询 |
| filter_by() | 把等值过滤器添加到原查询上,返回一个新查询 |
| limit | 使用指定的值限定原查询返回的结果 |
| offset() | 偏移原查询返回的结果,返回一个新查询 |
| order_by() | 根据指定条件对原查询结果进行排序,返回一个新查询 |
| group_by() | 根据指定条件对原查询结果进行分组,返回一个新查询 |
常用的SQLAlchemy查询执行器
| 方法 | 说明 |
|---|---|
| all() | 以列表形式返回查询的所有结果 |
| first() | 返回查询的第一个结果,如果未查到,返回None |
| first_or_404() | 返回查询的第一个结果,如果未查到,返回404 |
| get() | 返回指定主键对应的行,如不存在,返回None |
| get_or_404() | 返回指定主键对应的行,如不存在,返回404 |
| count() | 返回查询结果的数量 |
| paginate() | 返回一个Paginate对象,它包含指定范围内的结果 |