最近在做一些视觉检测的东西,进行数据集的训练和val之前,首先要对数据集进行一定的分析,分析数据集当中标签分类比例,以及其他的相关信息。接下来按照自己的想法以及百度到的东西进行相关实验。
第一步便是获取相关数据集。在进行数据集分析时,我使用的是xml格式(那些开源公开数据集包含有多种类型格式,可以自行选取)的数据进行分析,当然也可以使用yolo格式的txt类型的数据集进行分析。
第二步,进行数据集分析。数据集分析当然是使用pandas+matplotlib+numpy的经典数据分析模式进行。下面我们一步步开始进行。
1.导入xml数据集的路径。我是使用ubuntu18.04的系统进行操作。导入文件的路径是从根目录开始。
(在此提示一下路径末尾一定要添加/,要不然该路径在后续操作当中会被当成一个string)。
并导入xml,pandas以及os的pack。
2.遍历文件夹下的xml文件。
本人使用的xml文件类型如下所示,文件子标签当中的类型是text类型,所以我在获取值当中时使用 .text方法。若是需要获取的值类型,各位分析xml文件,看类型决定使用text或者attrib的方法。
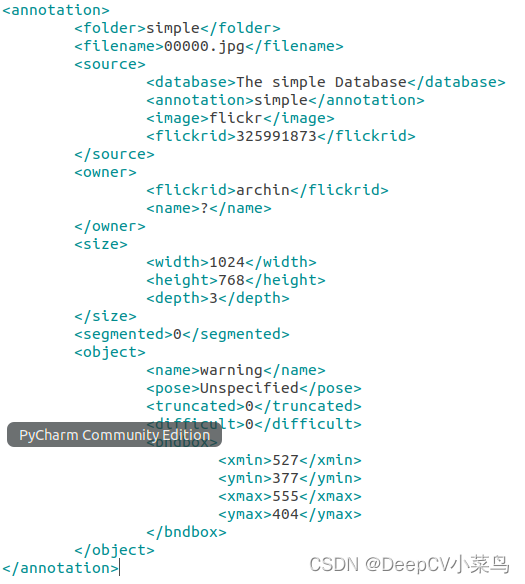
编写获取标签的函数。比计算你需要使用的数据。(本人需要计算尺寸大小以及获取name标签数据)。
def cal_annotations(resfile):
tree = Et.parse(resfile)
root_annotation = tree.getroot()
objects = root_annotation.find('object')
name = objects.find('name')
out_name = name.text
bndbox = objects.find('bndbox')
xmin = bndbox.find('xmin')
out_xmin = float(xmin.text)
xmax = bndbox.find('xmax')
out_xmax = float(xmax.text)
ymin = bndbox.find('ymin')
out_ymin = float(ymin.text)
ymax = bndbox.find('ymax')
out_ymax = float(ymax.text)
w = out_xmax - out_xmin
h = out_ymax - out_ymin
return out_name, w, h
下一步将需要使用的数据生成csv文件,并对其进行保存。
for i in range(len(filelist)):
res_file = os.path.join(cur_path,filelist[i])
name, w_, h_ = cal_annotations(res_file)
result.append([name, w_, h_])
test_csv = pd.DataFrame(data=result,columns=type)
print(test_csv)
test_csv.to_csv('csv1.csv')
第三部需要生成的csv文件使用pandas和matplotlib进行分析。(由于在生成csv文件时,使用很多默认参数,避坑指南1:在获取某一列的数据情况时一定要查看一下columons,要不然Key可能会出现一些差别。)之后在使用matplotlib进行绘图就可以啦。
import pandas as pd import matplotlib.pyplot as mlp path_csv = '/home/dupengsen/YOLOV5_1/onnx_project/csv1.csv' cctsdb_train = pd.read_csv(path_csv) print(cctsdb_train.columns) Names_list = cctsdb_train['Name '].value_counts()
以上只是对自己的记录,大家如有需要使用我的bug,私聊我哦