2.7 使用Pytorch实现手写数字识别
2.7.1 目标
- 知道如何使用Pytorch完成神经网络的构建
- 知道Pytorch中激活函数的使用方法
- 知道Pytorch中torchvision.transforms 中常见图形处理函数的使用
- 知道如何训练模型和如何评估模型
2.7.2 思路和流程分析
流程:
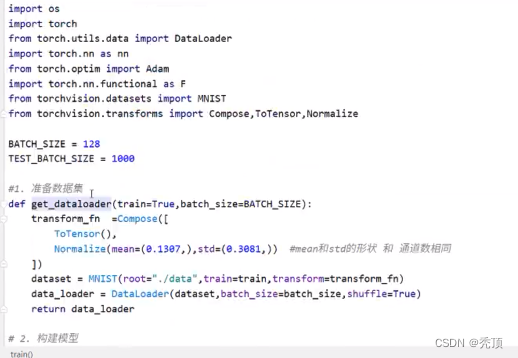
- 准备数据,这些需要准备DataLoader
- 构建模型,这里可以使用torch构造一个深层的神经网络
- 横型的训练
- 横型的保存,保存模型,后续持续使用
- 横型的评估,使用测试集,观察横型的好坏
2.7.3 准备训练集和测试集
准备数据集的方法前面已经讲过,但是通过前面的内容可知,调用MNIST返回的结果中图形数据是个Image对象需要对其进行处理
为了进行数据的处理,接下来学习torchvision.transfroms 的方法
2.7.3.1 torchvision.transforms的图形数据处理方法
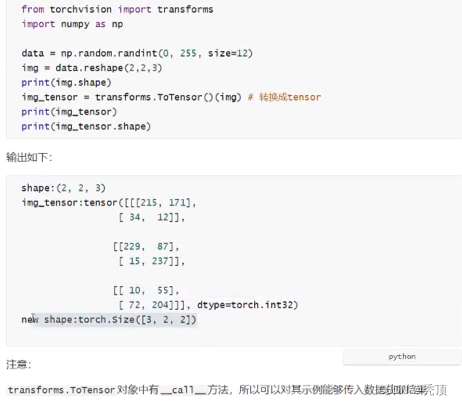
- torchvision.transforms .ToTensor
把一个取值范围是[0,255]的PIL.Image或者shape为(H,w,C)的numpy.ndarray,转换成形状为[c,H,w],取值范围是[0,1.0]的torch.FloatTensor
其中(H,w,C)意思为(高,宽,通道数》,黑白图片的通道数只有1,其中每个像索点的取值为[0,255]彩色图片的通道数为(R,G,B),每个通道的每个像素点的取值为[0,255],三个通道的颜色相与兽加,形成了各种额色
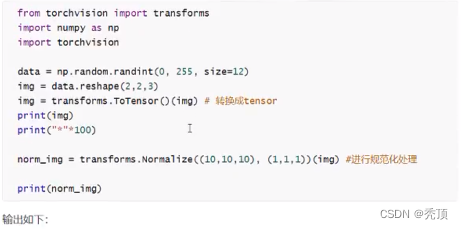
示例如下:
2.7.3.2 torchvision.transforms.Normalize(mean,std)
给定均值: mean,shape和图片的通道数相同(指的是每个通道的均值),方差: std,和图片的通道数相同(指的是每个通道的方差),将会把Tensor 规范化处理
即: NormaTized_image=(image-mean)/std。
例如:

2.7.3.3 torchvision.transforms .Compose(transforms)
将多个transform组合起来使用
例如

2.7.4 准备MNIST数据集的资料组和数据加载器
准备训练集

准备测试集

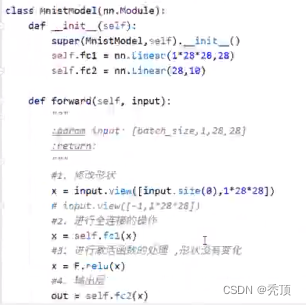
2.7.5 构建模型
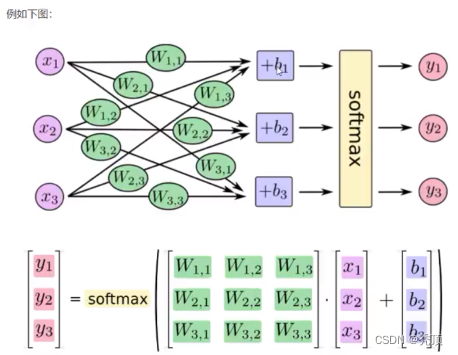
补充:全连接层:当前一层的神经元和前一层的神经元相互链接,其核心损作就是y =wx ,即矩阵的乘法,实现对前一层的数据的变换
模型的构建使用了一个三层的神经网络,其中包括两个全连接层和一个输出层,第一个全连接层会经过激活函数的处理,将处理后的结果交给下一个全连接层,进行变换后输出结果
那么在这个模型中有两个地方需要注意:
- 激活函数如何使用
- 每一层数据的形状
- 横型的损失函数
2.7.5.1 激活函数的使用

2.7.5.2 模型中数据的形状([添加形状变化图形])
1.原始输入数据为的形状: [batch_size,1,28,28]
2.进行形状的修改:[batch_size,28*28] (全连接层是在进行矩阵的乘法操作)
3.第一个全连接层的输出形状: [batch_size,28] ,这里的28是个人设定的,你也可以设置为别的
4.微活函数不会修改数据的形状
5.第二个全连接层的输出形状: [batch_size,10],因为手与数字有10个类别
构建模型的代码如下:

可以发现: pytorch在构建模型的时候形状上并不会考虑batch_size
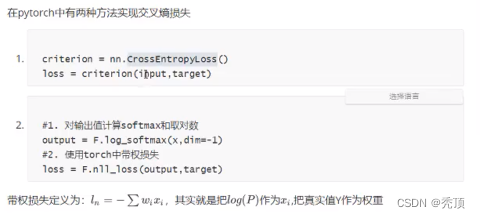
2.7.5.3 模型的损失函数
首先,我们需要明确,当前我们手写字体识别的问题是一个多分类的问题,所谓多分类对比的是之前学习的2分类
回顾之前的课程,我们在逻辑回归中,我们使用sigmoid进行计算对数似然损失,来定义我们的2分类的损失。


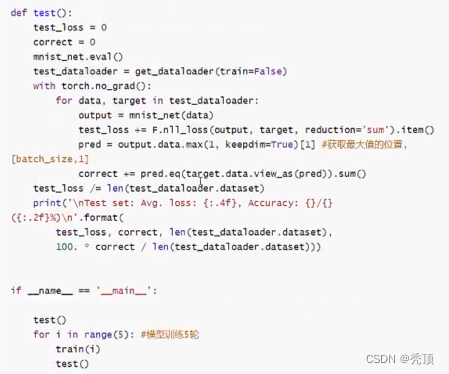
2.7.6 模型的训练
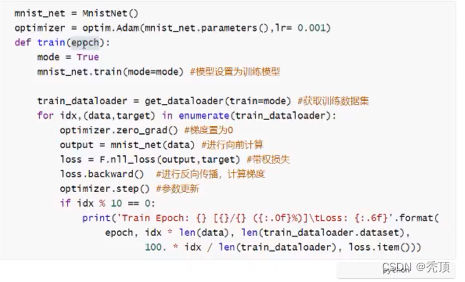
训练的流程:
- 实例化模型,设置模型为训练模式
- 实例化优化器类,实例化损失函数
- 获取,遍历dataloader
- 梯度置为0
- 进行向前计算
- 计算损失
- 反向传播
- 更新参数
2.7.8 模型的保存和加载
2.7.8.1 模型的保存

2.7.8.2 模型的加载

2.7.9 模型的评估
评估的过程和训练的过程相似,但是:
- 不需要计算梯度
- 需要收集损失和准确率,用来计算平均损失和平均准确率
- 损失的计算和训练时候损失的计算方法相同
- 准确率的计算:
- 模型的输出为[batch_size10]的形状
- 其中最大值的位置就是其预测的目标值 (预测值进行过sotfmax后为概率,sotfmax中分母都是相同的,分子越大,概率越大)
- 最大值的位置获取的方法可以使用 torch.max,返回最大值和最大值的位置。
- 返回最大值的位置后,和真实值([batch_size]) 进行对比,相同表示预测成功
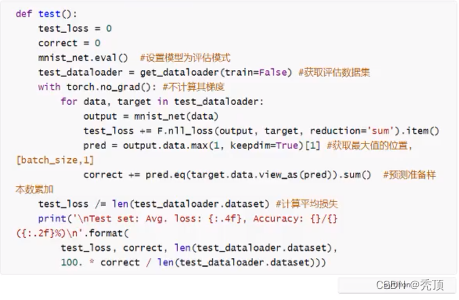
完整的代码