计算图(Computational Graph),叶子节点和运算节点
仅仅只是个人对于pytorch中计算图的理解
一个计算图由两部分构成:数据节点和运算节点,数据节点包含叶子节点和非叶子节点,运算节点也称运算操作。数据可以在计算图上正向传播也可以反向更新。
- 叶子节点: 凡是具有
requires_grad = False属性的Tensor都是叶子节点,但是并不是所有叶子节点的requires_grad都是False; - 那些由使用者自己定义的
requires_grad = True的数据节点也是叶子节点,这以为着该数据节点不是一个operation的结果; - 参与操作的输入中,只要有一个Tensor的
requires_grad = True,那么得到的结果中也有requires_grad = True; - 只有
requires_grad = True的叶子节点在.backward()的过程中,属性grad才会存储其梯度的值。
我们用pytorch定义一个简单的神经网络:
import torch
import torch.nn as nn
# 手动初始化w=1和b=0
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.constant_(m.weight.data, 1.0)
if hasattr(m, "bias") and m.bias is not None:
torch.nn.init.constant_(m.bias.data, 0.0)
elif classname.find("BatchNorm2d") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(1,2,3)
self.linear = nn.Linear(2,2)
def forward(self, x):
h = self.conv(x)
y = self.linear(h.view(x.size()[0], -1))
return y
我们先定义了一个包含conv层和linear层的神经网络。
x = torch.rand(1,1,3,3)
labels = torch.tensor([[0],[1]])
y = net(x)
然后定义其输入,输出。那么在这个计算图中哪些是数据节点,哪些是运算节点呢?很明显所有显式定义所的数据都是数据节点,也就是:x,labels,y,loss,同时还应该包括conv.weight,conv.bias等。那么其中的叶子节点包括x,labels,conv.weight, conv.bias等。其实我觉得非叶子节点应该算是操作节点的一部分,它只不过是开辟了一个数据内存用于保存操作节点的输出。我们可以打印此时网络中的数据:
print('x.requires_grad: {}; x.is_leaf: {}.'.format(x.requires_grad, x.is_leaf))
print('y.requires_grad: {}; y.is_leaf: {}.'.format(y.requires_grad, y.is_leaf))
print('y.grad_fn: ', y.grad_fn)
print('layer conv\'s weights: ', net.conv.weight)
print('layer conv\'s weights\' grad: ', net.conv.weight.grad)
print('layer conv\'s bias: ', net.conv.bias)
print('layer conv\'s bias\' grad: ', net.conv.bias.grad)
其结果为:
x.requires_grad: False; x.is_leaf: True.
y.requires_grad: True; y.is_leaf: False.
y.grad_fn: <AddmmBackward object at 0x7f84d082c1d0>
layer conv's weights: Parameter containing:
tensor([[[[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]]],
[[[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]]]], requires_grad=True)
layer conv's weights' grad: None
layer conv's bias: Parameter containing:
tensor([0., 0.], requires_grad=True)
layer conv's bias' grad: None
可以看到x是叶子节点,且x.requires_grad = False,这说明x不需要计算梯度。y不是叶子节点,但是它的requires_grad = True也就是说它需要计算梯度,同时y.grad_fn不为None,而是AddmmBackward对象,说明它是Addmm操作得到的,是一个中间变量。
小技巧:print一个Tensor,如果没有出现
requires_grad=True,说明requires_grad=False,它是一个叶子节点,同时不需要计算梯度;如果出现的是grad_fn=<AddmmBackward>说明它是一个操作得到的数据,不是叶子节点。
继续完成该网络
from torch.optim import SGD
optimizer = SGD(net.paramters())
criterion = nn.MSELoss()
loss = criterion(y, labels)
# 更新计算图中的参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
如此得到的loss也是非叶子节点,其requires_grad = True。至此我们可以构建如下的计算图。
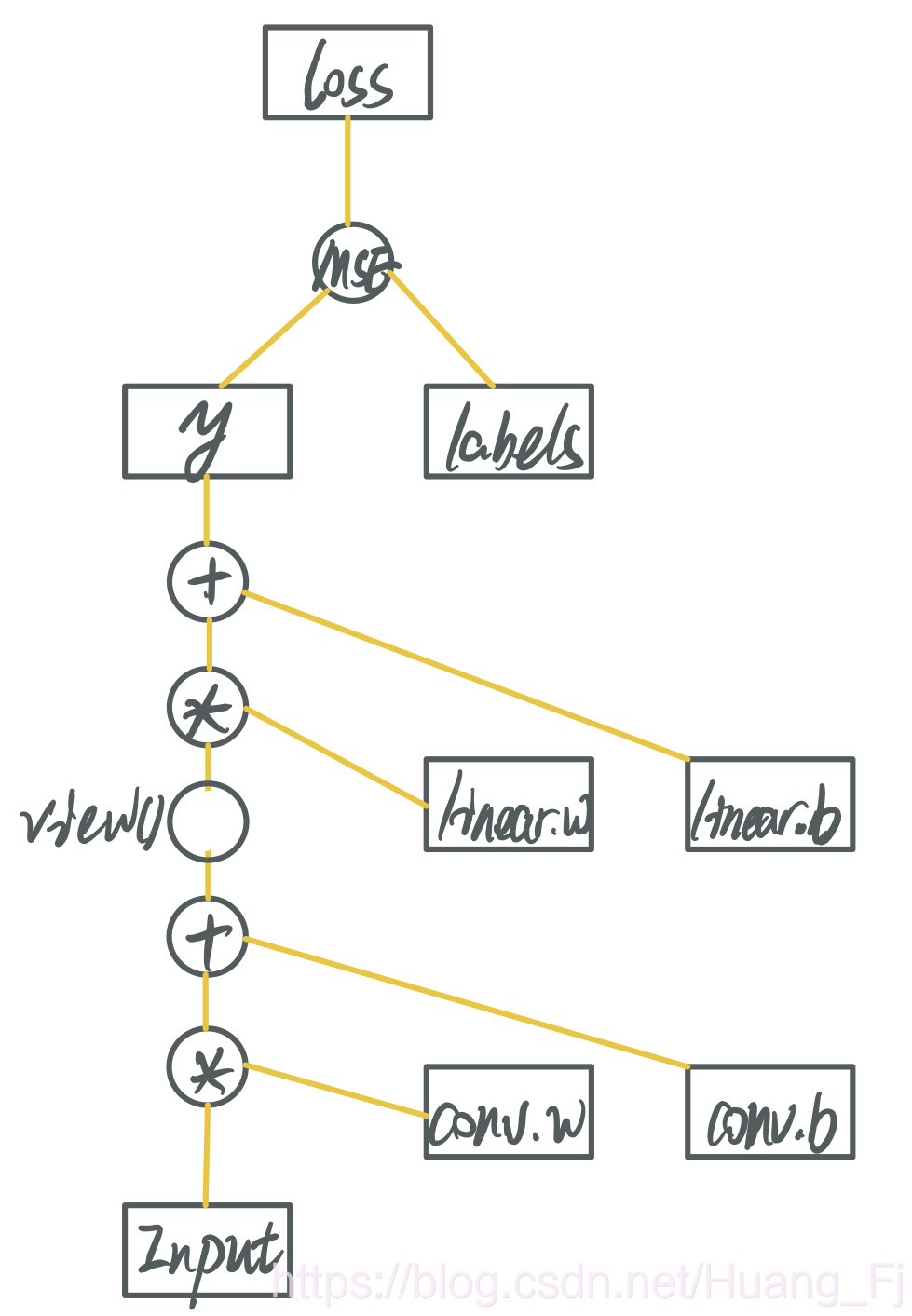
其中矩形为数据节点,圆圈为操作节点,所有的数据都在黄色直线中流动,由下往上是forward过程,由上往下是backward过程。y, loss并非叶子节点,他们只是所在黄线中流动的数据,只不过显式的保存了他们的值。register_hook(hook)其实做的也是这件事:将黄线中流动的数据显式的保存下来。
再来说loss.backward(),它的作用是计算当前计算图中,所有requires_grad = True的叶子节点的梯度,并且将其累加到Tensor.grad中,然后释放当前计算图。比如我们要计算 ∂ ( l o s s ) ∂ ( c o n v . w e i g h t ) \frac{\partial(loss)}{\partial(conv.weight)} ∂(conv.weight)∂(loss),那么根据链式法则,首先要计算loss对当前图中其他数据的偏导,其他数据也就是黄线上的数据。这就是计算图中其他数据的作用——仅仅只是作为计算叶子节点的中间变量。得到计算的偏导数以后存储在每个Tensor对应的.grad中。所谓释放当前计算图,指的是释放掉图1中所有的黄色线条上的数据以及运算操作,保存下来的就只有矩形中的数据。
优化器(SGD)就是将Tensor.grad中的值乘以学习率(learning_rate)加到该Tensor中。所以一般情况下,在调用.backward()之前,需要将所有Tensor中保存的梯度值清零,利用optimizer.zero_grad()他会将该optimizer中参数的.grad值置零。计算完梯度以后,再调用optimizer.step()执行优化。
继续增加代码
z = y.mean()
z.backward()
运行上述代码会报错“RuntimeError: Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time.”这是因为我们之前调用loss.backward()时,释放了当前计算图,再调用z.backward()时,先反向传播到y。由于y.grad_fn = <AddmmBackward at 0x7f6302704310> 也就是说y也是中间节点,而非叶子节点,所以会继续反向传播,但由于此时计算图已经被释放,无法继续追溯,所以产生了错误。利用loss.backword(retain_graph=True)可以保存当前计算图,以便其他数据继续利用。