目录
1、进程线程同步
共享内存
信号量
互斥锁
死锁的发现、调试、处理
互斥锁 条件锁
2、wireshark
wireshark
3、算法题
n的阶乘,求末尾0的个数
long zeros(long n)
{
long sum =0;
while(n!=0)
{
sum+=n/5;
n=n/5;
}
return sum;
}一亿个用户,每个用户都有粉丝,关注。怎样设计存储结构 存储结构的大小。
100个数字,生成100个 不重复的随机数。最快方法。
1、按顺序生成100个数,打乱顺序
2、分成十份,排列范围进行生成。
3、rand
4、洗牌原理
rand()函数不需要参数,它将会返回0到RAND_MAX之间的任意的整数。如果我们想要生成一个在区间[0, 1]之内的数,那么我们可以写出如下代码:
rand_num = rand()/RAND_MAX;time(0)的返回的是从1970 UTC Jan 1 00:00到当前时刻的秒数,为unsigned int类型。当我们在不同时刻运行程序时,就会有不同的随机数种子,因此就可以得到不同的结果:
srand(time(0));,如果我们设置某个固定的seed,那么虽然在同一次运行时,会有不同的随机数产生,但是对于这段程序的多次运行所得到的结果是不变的。
洗牌原理
可以对应到的就是“洗扑克牌”,在算法中也叫“洗牌原理”,我们知道洗扑克牌的方式就是随机的交换扑克牌的位置,又叫做"切牌",当你切了 很多次后,我们的扑克牌就可以认为是足够乱了,复杂度也就变成了O(N),用代码实现就是这样的。
<1> 先有序的生成52张牌,然后有序的放到数组中。
<2>从1-52中随机的产生一个数,然后将当前次数的位置跟随机数的位置进行交换,重复52次,我们的牌就可以认为足够乱了
用random_shuffle()算法打乱元素排列顺序。random_shuffle()定义在标准的头文件<algorithm.h>中。因为
所有的STL算法都是在名字空间std::中声明的,所以你要注意正确地声明数据类型。random_shuffle()有两个参数,第一个参数是指向序列首元素的迭代器,第二个参数则指向序列最后一个元素的下一个位置。下列代码段用random_shuffle()算法打乱了先前填充到向量中的元素:
#include <algorithm>
using std::random_shuffle;
random_shuffle(vi.begin(), vi.end()); /* 打乱元素 *————————————————
循环链表:双指针
————————————————
两个装满水的8升容器和一个空的3升容器.如何只利用他们三个容器平均分到4个不规则的容器中(大于4L)
5 8 0 3 0 0 0
0 8 3 3 2 0 0
6 5 0
6 2 3
8 2 1
8 0 2 3 2 1 0
7 0 3
4 6 0
1 6 3
0 6 3 4 2 1 0
0 8 1
0 8 0 4 2 1 1
0 2 0 4 2 4 4
0 0 0 4 4 4 4
————————————————
反转链表
ListNode* reverseList(ListNode* head) {
ListNode* prev = nullptr;
ListNode* curr = head;
while (curr) {
ListNode* next = curr->next;
curr->next = prev;
prev = curr;
curr = next;
}
return prev;
4、mysql
连接
两个表进行外连接查询时,以主表为基准(将主表的数据全部显示),从表显示与主表对应的数据,如果对应的没有,则以null补齐
LEFT JOIN(左连接):返回左边表中的所有记录和右表中与连接字段相等的记录。(左边是主表)
RIGHT JOIN(右连接):返回右边表中的所有记录和右表中与连接字段相等的记录。(右边是主表)
inner join
连接两个都有的
全连接 union
MYSQL优化方式
索引的失效方式
事物的四个特点
5、 GCC
makefile
gcc编译器
g++编译命令选项
core dmp的调试
日志
sced命令
awed命令
查看端口是否被占用
查看内存
6、常见
空类的大小
1、为何空类的大小不是0呢?
为了确保两个不同对象的地址不同,必须如此。1个字节
类的实例化是在内存中分配一块地址,每个实例在内存中都有独一无二的二地址。同样,空类也会实例化,所以编译器会给空类隐含的添加一个字节,这样空类实例化后就有独一无二的地址了。所以,空类的sizeof为1,而不是0.(空类也能被实例化,只要实例化就必须在内存中占据内存地址,而空类本身没有任何构造函数和虚函数,编译器会默认给空类隐含加上一个字节。系统会认为他被实例化。)
————————————————
父类的虚析构函数的作用
虚函数表的实现
C++中的虚函数的作用主要是实现了多态的机制。关于多态,简而言之就是用父类型别的指针指向其子类的实例,然后通过父类的指针调用实际子类的成员函数。这种技术可以让父类的指针有“多种形态”,这是一种泛型技术。所谓泛型技术,说白了就是试图使用不变的代码来实现可变的算法。比如:模板技术,RTTI技术,虚函数技术,要么是试图做到在编译时决议,要么试图做到运行时决议
对于派生类的实例,其虚函数表会是下面的一个样子:
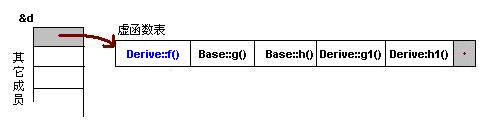
我们从表中可以看到下面几点,
1)覆盖的f()函数被放到了虚表中原来父类虚函数的位置。
2)没有被覆盖的函数依旧。
由b所指的内存中的虚函数表的f()的位置已经被Derive::f()函数地址所取代,于是在实际调用发生时,是Derive::f()被调用了。这就实现了多态。
多重继承:
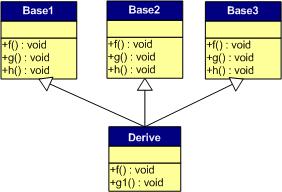
下面是对于子类实例中的虚函数表的图:
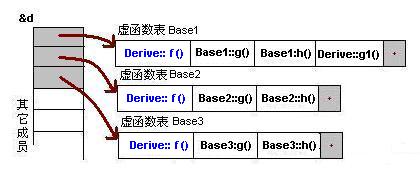
最后
一、通过父类型的指针访问子类自己的虚函数
我们知道,子类没有重载父类的虚函数是一件毫无意义的事情。因为多态也是要基于函数重载的。虽然在上面的图中我们可以看到Base1的虚表中有Derive的虚函数,但我们根本不可能使用下面的语句来调用子类的自有虚函数:
Base1 *b1 = new Derive();
b1->f1(); //编译出错
任何妄图使用父类指针想调用子类中的未覆盖父类的成员函数的行为都会被编译器视为非法,所以,这样的程序根本无法编译通过。但在运行时,我们可以通过指针的方式访问虚函数表来达到违反C++语义的行为。(关于这方面的尝试,通过阅读后面附录的代码,相信你可以做到这一点)
————————————————
析构函数能被重载吗
构造函数可以被重载,因为构造函数可以有多个且可以带参数。
析构函数不可以被重载,因为析构函数只能有一个,且不能带参数。
————————————————
初始化列表和构造函数赋值的区别
1. 每个成员变量在初始化列表中只能出现一次(初始化只能初始化一次)
2. 类中包含以下成员,必须放在初始化列表位置进行初始化:
- 引用成员变量
- const成员变量
- 自定义类型成员(该类没有默认构造函数)
如果不显示初始化, 我们编译器不知道该怎样去初始化自定义类型成员
其他的成员变量不进行初始化 都是可以的, 但是上面这三个必须在初始化列表中进行初始化
// 成员的初始化顺序和声明顺序一致,与其在初始化列表中的顺序没有关系 // 所以在写初始化列表时, 尽量让初始化顺序和声明顺序保持一致, 避免造成错误
class A{
public:
A(int a)
:_a(a)
{}
private:
int _a;
};
class B{
public:
B(int a, int ref)
:_aobj(a) // 如果不初始化自定义类型的成员会报错, 因为B中没有自定义类型成员的默认构造
,_ref(ref) // 引用类型必须在初始化列表中初始化,
,_n(10) // const成员必须在初始化列表中初始化
{}
private:
// 这里相当于是对成员变量的声明, 而成员变量属于对象, 对象只有在调构造函数时才初始化创建
// 相当于我们的成员变量也是在对象初始化时被构造出来, 真正定义成员变量的地方就是我们的初始化列表
A _aobj; // 这就是我们的自定义类型成员 没有默认构造函数
int& _ref; // 引用 必须在定义的时候初始化, 即可以在构造函数的初始化列表实现初始化
const int _n; // const成员也必须在定义时(初始化列表中)初始化
};
自己实现的hashtable
hash
7、网络协议
第五层——应用层(application layer) 报文
应用层(application layer):是体系结构中的最高层。直接为用户的应用进程提供服务(例如电子邮件、文件传输和终端仿真)。
在因特网中的应用层协议很多,如支持万维网应用的HTTP协议,支持电子邮件的SMTP协议,支持文件传送的FTP协议,DNS,POP3,SNMP,Telnet等等。
第四层——运输层(transport layer) 报文段/用户数据报
运输层(transport layer):负责向两个主机中进程之间的通信提供服务。由于一个主机可同时运行多个进程,因此运输层有复用和分用的功能。
复用:就是多个应用层进程可同时使用下面运输层的服务。
分用:就是把收到的信息分别交付给上面应用层中相应的进程。
运输层主要使用以下两种协议:
(1) 传输控制协议TCP(Transmission Control Protocol):面向连接的,数据传输的单位是报文段,能够提供可靠的交付。
(2) 用户数据包协议UDP(User Datagram Protocol):无连接的,数据传输的单位是用户数据报,不保证提供可靠的交付,只能提供“尽最大努力交付”。
第三层——网络层(network layer)数据报
网络层(network layer)主要包括以下 两个任务:
(1) 负责为分组交换网上的不同主机提供通信服务。 在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组或包进行传送。在TCP/IP体系中,由于网络层使用IP协议,因此分组也叫做IP数据报,或简称为数据报。
(2) 选中合适的路由,使源主机运输层所传下来的分组,能够通过网络中的路由器找到目的主机。
协议:IP,ICMP,IGMP,ARP,RARP
第二层——数据链路层(data link layer) 帧
1.数据链路层(data link layer):常简称为链路层,我们知道,两个主机之间的数据传输,总是在一段一段的链路上传送的,也就是说,在两个相邻结点之间传送数据是直接传送的(点对点),这时就需要使用专门的链路层的协议。
2.在两个相邻结点之间传送数据时,数据链路层将网络层交下来的IP数据报组装成帧(framing),在两个相邻结点之间的链路上“透明”地传送帧中的数据。
3.每一帧包括数据和必要的控制信息(如同步信息、地址信息、差错控制等)。典型的帧长是几百字节到一千多字节。
第一层——物理层(physical layer) 比特
物理层(physical layer):在物理层上所传数据的单位是比特。物理层的任务就是透明地传送比特流。
————————————————
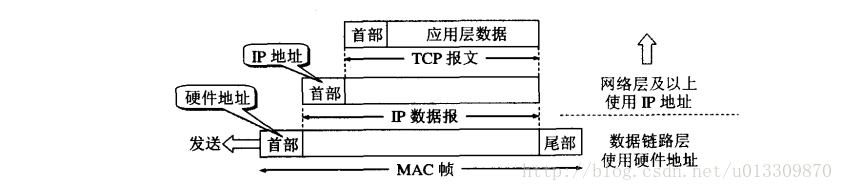
ARP
ARP(Address Resolution Protocol)地址解析协议,目的是实现IP地址到MAC地址的转换。
在计算机间通信的时候,计算机要知道目的计算机是谁(就像我们人交流一样,要知道对方是谁),这中间需要涉及到MAC地址,而MAC是真正的电脑的唯一标识符。
为什么需要ARP协议呢?因为在OSI七层模型中,对数据从上到下进行封装发送出去,然后对数据从下到上解包接收,但是上层(网络层)关心的IP地址,下层关心的是MAC地址,这个时候就需要映射IP和MAC。
在以太网协议中规定,同一局域网中的一台主机要和另一台主机进行直接通信,必须要知道目标主机的MAC地址。而在TCP/IP协议中,网络层和传输层只关心目标主机的IP地址。这就导致在以太网中使用IP协议时,数据链路层的以太网协议接到上层IP协议提供的数据中,只包含目的主机的IP地址。于是需要一种方法,根据目的主机的IP地址,获得其MAC地址。这就是ARP协议要做的事情。所谓地址解析(address resolution)就是主机在发送帧前将目标IP地址转换成目标MAC地址的过程。

注意:在点对点链路中不使用ARP,实际上在点对点网络中也不使用MAC地址,因为在此类网络中分别已经获取了对端的IP地址。
icmp
ICMP(Internet Control Message Protocol)Internet控制报文协议。它是TCP/IP协议簇的一个子协议,用于在IP主机、路由器之间传递控制消息
响应请求
我们日常使用最多的ping,就是响应请求(Type=8)和应答(Type=0),一台主机向一个节点发送一个Type=8的ICMP报文,如果途中没有异常(例如被路由器丢弃、目标不回应ICMP或传输失败),则目标返回Type=0的ICMP报文,说明这台主机存在,更详细的tracert通过计算ICMP报文通过的节点来确定主机与目标之间的网络距离
ping 用来测试网络可达性,tracert 用来显示到达目的主机的路径
ping端口:
telnet 192.168.178.2 80
1.Ping 127.0.0.1
127.0.0.1是本地的循环地址,Ping通则说明TCP/IP协议工作正常,否则TCP/IP就不正常。
2.Ping本机的IP地址
使用IPCONFIG命令可查看本机的IP地址,Ping IP地址,若Ping通,说明网络适配器(网卡或MODEM)工作正常,否则就不正常。
3.Ping同网段计算机IP地址
Ping 不通则说明网络线路出现故障,如网络中还有路由器,则应先Ping路由器在本网段端口的IP地址,不通则此段线路有问题,通则再Ping路由器在目标计算机所在网段的端口IP地址,不通则路由出现故障,通再Ping目的机的IP地址。
4.Ping网址
若要检测一下一个带DNS服务的网络
bytes=32"表示ICMP报文中有32个字节的测试数据,"time=4ms"是往返时间。Sent发送多个秒包、Received 收到多个回应包、Lost 丢弃了多少个Minmum 最小值、MAXimun 最大值、Average 平均值。所在图上来看,来回只用了4MS 时间,lost =0 即是丢包数为0
telnet就是查看某个端口是否可访问。我们在搞开发的时候,经常要用的端口就是 8080。那么你可以启动服务器,用telnet 去查看这个端口是否可用。
linux :traceroute hostname
windows: tracert hostname
traceroute是用来检测发出数据包的主机到目标主机之间所经过的网关数量的工具。traceroute的原理是试图以最小的TTL(存活时间)发出探测包来跟踪数据包到达目标主机所经过的网关,然后监听一个来自网关ICMP的应答。发送数据包的大小默认为38个字节。
原理:程序利用增加存活时间(TTL)来实现其功能。每当数据包(3个数据包包括源地址,目的地址和包发出的时间标签)经过一个路由器,其存活时间就会减1。当其存活时间是0时,主机便取消数据包,并传送一个ICMP(Internet控制报文协议。它是TCP/IP协议族的一个子协议,用于在IP主机、路由器之间传递控制消息。控制消息是指网络通不通、主机是否可达、路由是否可用等网络本身的消息。这些控制消息虽然并不传输用户数据,但是对于用户数据的传递起着重要的作用。) TTL数据包给原数据包的发出者。
traceroute程序完整过程:首先它发送一份TTL字段为1的IP数据包给目的主机,处理这个数据包的第一个路由器将TTL值减1,然后丢弃该数据报,并给源主机发送一个ICMP报文(“超时”信息,这个报文包含了路由器的IP地址,这样就得到了第一个路由器的地址),然后traceroute发送一个TTL为2的数据报来得到第二个路由器的IP地址,继续这个过程,直至这个数据报到达目的主机。
————————————————
ip
rtp
RTP协议和RTP控制协议RTCP一起使用,而且它是创建在UDP协议上的