目录
1、智能指针
【C++】智能指针详解_Billy12138的博客-CSDN博客_智能指针
深入实践C++11智能指针_code_peak的博客-CSDN博客
shared_ptr<int> p1 = new int(1024);//错误:必须使用直接初始化形式
shared_ptr<int> p2(new int(1024));//正确:使用了直接初始化形式
C++ 中有四种智能指针:auto_pt、unique_ptr、shared_ptr、weak_ptr 其中后三个是 C++11 支持,第一个已经被 C++11 弃用且被 unique_prt 代替,不推荐使用。下文将对其逐个说明。
既然 std::unique_ptr 不能复制,那么如何将一个 std::unique_ptr 对象持有的堆内存转移给另外一个呢?答案是使用移动构造,示例代码如下:
int main()
{
std::unique_ptr<int> up1(std::make_unique<int>(123));
std::unique_ptr<int> up2(std::move(up1));
std::cout << ((up1.get() == nullptr) ? "up1 is NULL" : "up1 is not NULL") << std::endl;
std::unique_ptr<int> up3;
up3 = std::move(up2);
std::cout << ((up2.get() == nullptr) ? "up2 is NULL" : "up2 is not NULL") << std::endl;
return 0;
}
2、unordermap hashmap
哈希函数
我们通常使用数组或者链表来存储元素,一旦存储的内容数量特别多,需要占用很大的空间,而且在查找某个元素是否存在的过程中,数组和链表都需要挨个循环比较,而通过 哈希 计算,可以大大减少比较次数。
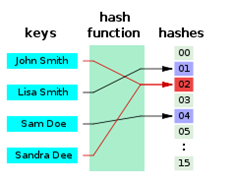
举个栗子:
现在有 4 个数 {2,5,9,13},需要查找 13 是否存在。
1.使用数组存储,需要新建个数组 new int[]{2,5,9,13},然后需要写个循环遍历查找:
这样需要遍历 4 次才能找到,时间复杂度为 O(n)。
2.而假如存储时先使用哈希函数进行计算,这里我随便用个函数:
H[key] = key % 3;
四个数 {2,5,9,13} 对应的哈希值为:
-
H[2] = 2 % 3 = 2; -
H[5] = 5 % 3 = 2; -
H[9] = 9 % 3 = 0; -
H[13] = 13 % 3 = 1;
然后把它们存储到对应的位置。
当要查找 13 时,只要先使用哈希函数计算它的位置,然后去那个位置查看是否存在就好了,本例中只需查找一次,时间复杂度为 O(1)。
因此可以发现,哈希 其实是随机存储的一种优化,先进行分类,然后查找时按照这个对象的分类去找。
哈希通过一次计算大幅度缩小查找范围,自然比从全部数据里查找速度要快。
比如你和我一样是个剁手族买书狂,家里书一大堆,如果书存放时不分类直接摆到书架上(数组存储),找某本书时可能需要脑袋从左往右从上往下转好几圈才能发现;如果存放时按照类别分开放,技术书、小说、文学等等分开(按照某种哈希函数计算),找书时只要从它对应的分类里找,自然省事多了。
由于unordered_map内部采用的hashtable的数据结构存储,所以,每个特定的key会通过一些特定的哈希运算映射到一个特定的位置,我们知道,hashtable是可能存在冲突的(多个key通过计算映射到同一个位置),在同一个位置的元素会按顺序链在后面。所以把这个位置称为一个bucket是十分形象的(像桶子一样,可以装多个元素)。可以参考这篇介绍哈希表的文章
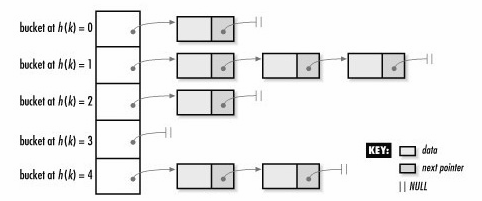
所以unordered_map内部其实是由很多哈希桶组成的,每个哈希桶中可能没有元素,也可能有多个元素。
3、基于IO的并发
4、C++11
noexcept
禁止隐式构造函数。
移动构造
在C++11之前,如果要将源对象的状态转移到目标对象只能通过复制。
而现在在某些情况下,我们没有必要复制对象——只需要移动它们。
C++11引入移动语义:
~源对象资源的控制权全部交给目标对象
对比一下复制构造和移动构造:
复制构造是这样的:

在对象被复制后临时对象和复制构造的对象各自占有不同的同样大小的堆内存,就是一个副本。
移动构造是这样的:

就是让这个临时对象它原本控制的内存的空间转移给构造出来的对象,这样就相当于把它移动过去了。
#include<iostream>
using namespace std;
class IntNum{
public:
IntNum(int x = 0):xptr(new int(x)){//构造函数
cout<<"Calling constructor..."<<endl;
}
IntNum(const IntNum &n):xptr(new int(*n.xpr)){//复制构造函数
cout<<"Calling copy constructor..."<<endl;
}
~IntNum(){//析构函数
delete xpr;
cout<<"Destructing..."<<endl;
}
IntNum(IntNum && n):xptr(n.xptr){//移动构造函数
n.xptr = nullptr;
cout<<"Calling move constructor..."<<endl;}
int getInt(){return *xptr;}//返回指针所指向的值,而不是返回指针本身
private:
int *xptr;
};
//返回值为IntNum类对象
IntNum getNum(){
//定义了一个局部对象,然后将局部对象作为结果返回
IntNum a;
//返回值是IntNum类型
return a;
}
int main(){
//getNum()函数返回了一个IntNum类型的对象(临时无名对象),之后调用类的函数
cout<<"getNum().getInt()"<<endl;
return 0;
} 版本一通过深层复制构造函数实现的返回含有指针成员的对象,在这个过程中,做了一些无用功,既需要构造临时无名(注:是无名对象,不是上例中的对象a)对象,还要对其进行析构。
在上例中不构造临时无名对象不行吗?其实呢我们也不用构造临时无名对象了,对象a反正是要消亡的,我们把要消亡的对象a占用的资源转移给临时对象,不行吗?!这样的方案就是使用移动构造
看函数体里面,我们发现再做完xptr(n.xptr)这种指针对指针的复制(也就是把参数指针所指向的对象转给了当前正在被构造的指针)后,接着就把参数n里面的指针置为空指针(n.xptr = nullptr;),对象里面的指针置为空指针后,将来析构函数析构该指针(delete xpr;)时,是delete一个空指针,不发生任何事情,这就是一个移动构造函数。移动构造函数中的参数类型,&&符号表示是右值引用;即将消亡的值就是右值,函数返回的临时变量也是右值,这样的单个的这样的引用可以绑定到左值的,而这个引用它可以绑定到即将消亡的对象,绑定到右值
5、linux命令
查看内存 top
在Linux下面,我们常用top命令来查看系统进程,top也能显示系统内存。我们常用的Linux下查看内容的专用工具是free命令。
查看进程 ps
linux系统查看服务内存,cpu,硬盘命令_张哈哈爱吃肉的博客-CSDN博客_linux 查看内存
硬盘:是磁存储,靠磁头读写。硬盘可以长期存储数据,不受断电影响。存储容量大。
一.linux系统查看内存命令:cat /proc/meminfo
free命令是一个快速查看内存使用情况的方法,它是对 /proc/meminfo 收集到的信息的一个概述

如何判断系统内存不足:如果Swap used值大于0,代表服务器物理内存已经遇到内存瓶颈了,已开始使用虚拟内存了,要么优化代码,要么加内存
1. 内存
total:内存总数
used:已使用的内存数
free:空闲的内存数
shared:当前已废弃不用
buffers:系统分配但未被使用的缓冲区
cached:系统分配但未被使用的缓存
(buffers和cached区别:A buffer is something that has yet to be “written” to disk. A cache is something that has been “read” from the disk and stored for later use(缓冲区还没有被写入磁盘。 缓存是从磁盘“读取”并存储以备后用的))
2. 程序已用内存数:
-(buffers/cached):used 第一部分mem行 used-buffers-cached (反应的被程序实实在在吃掉的内存)
程序可用内存数
+(buffers/cached):free 第一部分 mem行 free+buffers+cached (可以挪用的内存总数)
3.交换区
二.cpu:top(即可查看cpu也可查看内存占用率1.)

三.显示磁盘 :df -h

四、vmstat查看机器实时的综合情况:load,内存,swap,cpu使用率等方面

6、OpenGL
7、其他
Docker&Docker命令学习 - caoduaxi的个人空间 - OSCHINA - 中文开源技术交流社区
nginx学习,看这一篇就够了:下载、安装。使用:正向代理、反向代理、负载均衡。常用命令和配置文件,很全_冯insist的博客-CSDN博客
看完这篇Kafka,你也许就会了Kafka_心的步伐的博客-CSDN博客_kafka看完

8、C++11 可调用对象
在 C++11 中经常提及 Callable object ,即所谓的可调用对象,这里就总结一下常见的可调用对象都有哪些。
常见的可调用对象:
C++11新特性之七:bind和function_草上爬的博客-CSDN博客_bind和function
————————————————
一.std::bind
//function object内部调用plus<>(也就是operator+),以占位符(placeholders)_1为第一个参数,
//以10为第二个参数,占位符_1表示实际传入此表达式的第一实参,返回“实参+10”的结果值
auto plus10 = std::bind(std::plus<int> (), std::placeholders::_1, 10);
std::cout << plus10(7) << std::endl;// 输出17
// (x + 10)*2,下面的代码中x=7
std::bind(std::multiplies<int>(),
std::bind(std::plus<int>(), std::placeholders::_1, 10),// i+10
2)(7); 使用std::bind要注意的地方
(1)bind预先绑定的参数需要传具体的变量或值进去,对于预先绑定的参数,是pass-by-value的。除非该参数被std::ref或者std::cref包装,才pass-by-reference。
(2)对于不事先绑定的参数,需要传std::placeholders进去,从_1开始,依次递增。placeholder是pass-by-reference的;
(3)bind的返回值是可调用实体,可以直接赋给std::function对象;
(4)对于绑定的指针、引用类型的参数,使用者需要保证在可调用实体调用之前,这些参数是可用的;
(5)类的this可以通过对象或者指针来绑定
二.std::function
类模版std::function是一种通用、多态的函数封装。std::function的实例可以对任何可以调用的目标实体进行存储、复制、和调用操作,这些目标实体包括普通函数、Lambda表达式、bind表达式、函数指针以及其它函数对象,。std::function对象是对C++中现有的可调用实体的一种类型安全的包装(我们知道像函数指针这类可调用实体,是类型不安全的)。
最简单的理解就是:
通过std::function对C++中各种可调用实体(普通函数、Lambda表达式、函数指针、以及其它函数对象等)的封装,形成一个新的可调用的std::function对象;让我们不再纠结那么多的可调用实体。
#include <functional>
#include <iostream>
struct Foo {
Foo(int num) : num_(num) {}
void print_add(int i) const { std::cout << num_+i << '\n'; }
int num_;
};
void print_num(int i)
{
std::cout << i << '\n';
}
struct PrintNum {
void operator()(int i) const
{
std::cout << i << '\n';
}
};
int main()
{
// store a free function
std::function<void(int)> f_display = print_num;
f_display(-9);
// store a lambda
std::function<void()> f_display_42 = []() { print_num(42); };
f_display_42();
// store the result of a call to std::bind
std::function<void()> f_display_31337 = std::bind(print_num, 31337);
f_display_31337();
// store a call to a member function
std::function<void(const Foo&, int)> f_add_display = &Foo::print_add;
const Foo foo(314159);
f_add_display(foo, 1);
f_add_display(314159, 1);
// store a call to a data member accessor
std::function<int(Foo const&)> f_num = &Foo::num_;
std::cout << "num_: " << f_num(foo) << '\n';
// store a call to a member function and object
using std::placeholders::_1;
std::function<void(int)> f_add_display2 = std::bind( &Foo::print_add, foo, _1 );
f_add_display2(2);
// store a call to a member function and object ptr
std::function<void(int)> f_add_display3 = std::bind( &Foo::print_add, &foo, _1 );
f_add_display3(3);
// store a call to a function object
std::function<void(int)> f_display_obj = PrintNum();
f_display_obj(18);
}三、std::ref和std::cref
std::ref 用于包装按引用传递的值。
std::cref 用于包装按const引用传递的值。
为什么需要std::ref和std::cref
bind()是一个函数模板,它的原理是根据已有的模板,生成一个函数,但是由于bind()不知道生成的函数执行的时候,传递进来的参数是否还有效。所以它选择参数值传递而不是引用传递。如果想引用传递,std::ref和std::cref就派上用场了。
#include <functional>
#include <iostream>
void f(int& n1, int& n2, const int& n3)
{
std::cout << "In function: n1[" << n1 << "] n2[" << n2 << "] n3[" << n3 << "]" << std::endl;
++n1; // 增加存储于函数对象的 n1 副本
++n2; // 增加 main() 的 n2
//++n3; // 编译错误
std::cout << "In function end: n1[" << n1 << "] n2[" << n2 << "] n3[" << n3 << "]" << std::endl;
}
int main()
{
int n1 = 1, n2 = 1, n3 = 1;
std::cout << "Before function: n1[" << n1 << "] n2[" << n2 << "] n3[" << n3 << "]" << std::endl;
std::function<void()> bound_f = std::bind(f, n1, std::ref(n2), std::cref(n3));
bound_f();
std::cout << "After function: n1[" << n1 << "] n2[" << n2 << "] n3[" << n3 << "]" << std::endl;
}重载函数调用运算符
如果类重载了函数调用运算符,则我们可以像使用函数一样使用该类的对象,因为这样的类同时也能存储状态,所以与普通函数相比它们更加灵活,例如下面的PrintString可以定制用于输出的流以及分隔符。
函数调用运算符必须是成语函数,一个类可以定义多个不同版本的调用运算符,相互之间应该在参数数量或类型上有所区别。
当我们编写一个lambda后,编译器将该表达式翻译成一个未命名类的未命名对象,该类中含有一个重载的函数调用运算符
class PrintString
{
public:
PrintString(std::ostream& os, char c) :os_(os), sep_(c) {};
void operator()(const std::string& str) const
{
os_ << str << sep_;
}
private:
std::ostream& os_;
char sep_;
};
int main()
{
PrintString printObj{ std::cout, ',' };
printObj("hello");
printObj("world");
system("pause");
}
noexcept
在C++11中,声明一个函数不可以抛出任何异常使用关键字noexcept.
-
void mightThrow(); // could throw any exceptions. -
void doesNotThrow() noexcept; // does not throw any exceptions.
下面两个函数声明的异常规格在语义上是相同的,都表示函数不抛出任何异常。
-
void old_stytle() throw(); -
void new_style() noexcept;
如果被noexcept修饰的函数抛出了异常,编译器直接选择调用标准库里面的 std::terminate()直接终止程序,比throw()在处理异常的效率要高些 有效的防治了异常的扩散传播
nothrow
在C++中new在申请内存失败时默认会抛出一个std::bad_alloc 异常。
所以,按照C++标准,如果想检查new是否成功,则应该通过try catch捕捉异常。
但有些编译器不支持try catch。
用户一般简单地使用”new(std::nothrow) 类型”。
new在分配内存失败时会抛出异常,
而”new(std::nothrow)”在分配内存失败时会返回一个空指针。
9、Openssl基本原理
openssl基本原理 + 生成证书 + 使用实例_oldmtn的博客-CSDN博客_openssl 生成证书
公钥/私钥/签名/验证签名/加密/解密/非对称加密
我们一般的加密是用一个密码加密文件,然后解密也用同样的密码.这很好理解,这个是对称加密.而有些加密时,加密用的一个密码,而解密用另外一组密码,这个叫非对称加密,意思就是加密解密的密码不一样.初次接触的人恐怕无论如何都理解不了.其实这是数学上的一个素数积求因子的原理的应用,如果你一定要搞懂,百度有大把大把的资料可以看,其结果就是用这一组密钥中的一个来加密数据,可以用另一个解开.是的没错,公钥和私钥都可以用来加密数据,相反用另一个解开,公钥加密数据,然后私钥解密的情况被称为加密解密,私钥加密数据,公钥解密一般被称为签名和验证签名.
因为公钥加密的数据只有它相对应的私钥可以解开,所以你可以把公钥给人和人,让他加密他想要传送给你的数据,这个数据只有到了有私钥的你这里,才可以解开成有用的数据,其他人就是得到了,也看8懂内容.同理,如果你用你的私钥对数据进行签名,那这个数据就只有配对的公钥可以解开,有这个私钥的只有你,所以如果配对的公钥解开了数据,就说明这数据是你发的,相反,则不是.这个被称为签名.
实际应用中,一般都是和对方交换公钥,然后你要发给对方的数据,用他的公钥加密,他得到后用他的私钥解密,他要发给你的数据,用你的公钥加密,你得到后用你的私钥解密,这样最大程度保证了安全性.
具体在使用中,A和B都各有一个public key和一个private key,这些key根据相应的算法已经生成好了。private key只保留在各自的本地,public key传给对方。A要给B发送网络数据,那么A先使用自己的private key(只有A知道)加密数据的hash值(感谢 指正,评论区有说明),之后再用B的public key加密数据。之后,A将加密的hash值和加密的数据再加一些其他的信息,发送给B。B收到了之后,先用自己的private key(只有B知道)解密数据,本地运算一个hash值,之后用A的public key解密hash值,对比两个hash值,以检验数据的完整性。在这个过程中,总共有4个密钥,分别是A的public/private key,和B的public/private key。
如果B的解密结果符合预期,那么至少可以证明,这个信息只有B能获取,因为B的private key参与了解密,而B的private key其他人都不知道。并且,这个信息是来自A,而不是C伪造的,因为A的public key参与了解密。一切看起来似乎很美好。
现实中,通过CA(Certificate Authority)来保证public key的真实性。CA也是基于非对称加密算法来工作。有了CA,B会先把自己的public key(和一些其他信息)交给CA。CA用自己的private key加密这些数据,加密完的数据称为B的数字证书。现在B要向A传递public key,B传递的是CA加密之后的数字证书。A收到以后,会通过CA发布的CA证书(包含了CA的public key),来解密B的数字证书,从而获得B的public key。
CA也可以自己生成,如果两端都是自己编写的情况。
实际使用
非对称加密算法比对称加密算法要复杂的多,处理起来也要慢得多。如果所有的网络数据都用非对称加密算法来加密,那效率会很低。所以在实际中,非对称加密只会用来传递一条信息,那就是用于对称加密的密钥。当用于对称加密的密钥确定了,A和B还是通过对称加密算法进行网络通信。这样,既保证了网络通信的安全性,又不影响效率,A和B也不用见面商量密钥了。
所以,在现代,A和B之间要进行安全,省心的网络通信,需要经过以下几个步骤
- 通过CA体系交换public key
- 通过非对称加密算法,交换用于对称加密的密钥
- 通过对称加密算法,加密正常的网络通信
这基本就是SSL/TLS的工作过程了。
10、TCP
- 应用层协议
HTTP、SNMP、WWW DNS TELNET FTP
- 传输层
udp tcp-传输控制协议(TCP,Transmission Control Protocol)
- 网络层
IP ICMP
- 数据链路层
以太网
- 物理层
三次握手 四次挥手
一文搞懂TCP与UDP的区别 - Fundebug - 博客园

TCP—-SYN、ACK-、FIN、RST、PSH、URG-详解_lamb7758的博客-CSDN博客_ack syn
一、TCP/IP网络模型
TCP/IP 是互联网相关的各类协议族的总称,比如:TCP,UDP,IP,FTP,HTTP,ICMP,SMTP 等都属于 TCP/IP 族内的协议。
TCP/IP模型是互联网的基础,它是一系列网络协议的总称。这些协议可以划分为四层,分别为链路层、网络层、传输层和应用层。
- 链路层:负责封装和解封装IP报文,发送和接受ARP/RARP报文等。
- 网络层:负责路由以及把分组报文发送给目标网络或主机。
- 传输层:负责对报文进行分组和重组,并以TCP或UDP协议格式封装报文。
- 应用层:负责向用户提供应用程序,比如HTTP、FTP、Telnet、DNS、SMTP等。
二、UDP
UDP有不提供数据包分组、组装和不能对数据包进行排序的缺点,
1. 面向无连接
首先 UDP 是不需要和 TCP一样在发送数据前进行三次握手建立连接的,想发数据就可以开始发送了。并且也只是数据报文的搬运工,不会对数据报文进行任何拆分和拼接操作。
具体来说就是:
- 在发送端,应用层将数据传递给传输层的 UDP 协议,UDP 只会给数据增加一个 UDP 头标识下是 UDP 协议,然后就传递给网络层了
- 在接收端,网络层将数据传递给传输层,UDP 只去除 IP 报文头就传递给应用层,不会任何拼接操作
2. 有单播,多播,广播的功能
UDP 不止支持一对一的传输方式,同样支持一对多,多对多,多对一的方式,也就是说 UDP 提供了单播,多播,广播的功能。
3. UDP是面向报文的
发送方的UDP对应用程序交下来的报文,在添加首部后就向下交付IP层。UDP对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。因此,应用程序必须选择合适大小的报文
4. 不可靠性
首先不可靠性体现在无连接上,通信都不需要建立连接,想发就发,这样的情况肯定不可靠。
并且收到什么数据就传递什么数据,并且也不会备份数据,发送数据也不会关心对方是否已经正确接收到数据了。
再者网络环境时好时坏,但是 UDP 因为没有拥塞控制,一直会以恒定的速度发送数据。即使网络条件不好,也不会对发送速率进行调整。这样实现的弊端就是在网络条件不好的情况下可能会导致丢包,但是优点也很明显,在某些实时性要求高的场景(比如电话会议)就需要使用 UDP 而不是 TCP。
三、TCP
当一台计算机想要与另一台计算机通讯时,两台计算机之间的通信需要畅通且可靠,这样才能保证正确收发数据。例如,当你想查看网页或查看电子邮件时,希望完整且按顺序查看网页,而不丢失任何内容。当你下载文件时,希望获得的是完整的文件,而不仅仅是文件的一部分,因为如果数据丢失或乱序,都不是你希望得到的结果,于是就用到了TCP。
TCP协议全称是传输控制协议是一种面向连接的、可靠的、基于字节流的传输层通信协议,由 IETF 的RFC 793定义。TCP 是面向连接的、可靠的流协议。流就是指不间断的数据结构,你可以把它想象成排水管中的水流。
1. TCP连接过程
如下图所示,可以看到建立一个TCP连接的过程为(三次握手的过程):

第一次握手
客户端向服务端发送连接请求报文段。该报文段中包含自身的数据通讯初始序号。请求发送后,客户端便进入 SYN-SENT 状态。
第二次握手
服务端收到连接请求报文段后,如果同意连接,则会发送一个应答,该应答中也会包含自身的数据通讯初始序号,发送完成后便进入 SYN-RECEIVED 状态。
第三次握手
当客户端收到连接同意的应答后,还要向服务端发送一个确认报文。客户端发完这个报文段后便进入 ESTABLISHED 状态,服务端收到这个应答后也进入 ESTABLISHED 状态,此时连接建立成功。
这里可能大家会有个疑惑:为什么 TCP 建立连接需要三次握手,而不是两次?这是因为这是为了防止出现失效的连接请求报文段被服务端接收的情况,从而产生错误。
2. TCP断开链接
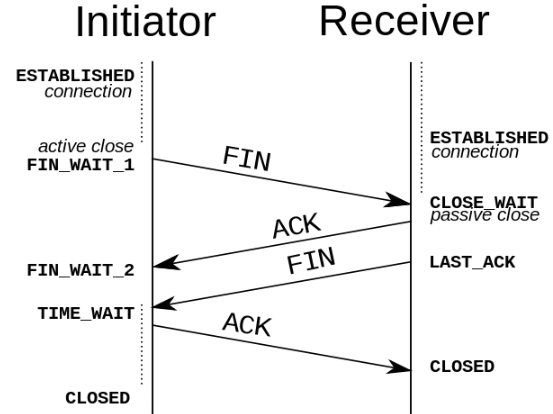
TCP 是全双工的,在断开连接时两端都需要发送 FIN 和 ACK。
第一次握手
若客户端 A 认为数据发送完成,则它需要向服务端 B 发送连接释放请求。
第二次握手
B 收到连接释放请求后,会告诉应用层要释放 TCP 链接。然后会发送 ACK 包,并进入 CLOSE_WAIT 状态,此时表明 A 到 B 的连接已经释放,不再接收 A 发的数据了。但是因为 TCP 连接是双向的,所以 B 仍旧可以发送数据给 A。
第三次握手
B 如果此时还有没发完的数据会继续发送,完毕后会向 A 发送连接释放请求,然后 B 便进入 LAST-ACK 状态。
第四次握手
A 收到释放请求后,向 B 发送确认应答,此时 A 进入 TIME-WAIT 状态。该状态会持续 2MSL(最大段生存期,指报文段在网络中生存的时间,超时会被抛弃) 时间,若该时间段内没有 B 的重发请求的话,就进入 CLOSED 状态。当 B 收到确认应答后,也便进入 CLOSED 状态。
3. TCP协议的特点
-
面向连接
面向连接,是指发送数据之前必须在两端建立连接。建立连接的方法是“三次握手”,这样能建立可靠的连接。建立连接,是为数据的可靠传输打下了基础。
-
仅支持单播传输
每条TCP传输连接只能有两个端点,只能进行点对点的数据传输,不支持多播和广播传输方式。
- 面向字节流
TCP不像UDP一样那样一个个报文独立地传输,而是在不保留报文边界的情况下以字节流方式进行传输。
-
可靠传输
对于可靠传输,判断丢包,误码靠的是TCP的段编号以及确认号。TCP为了保证报文传输的可靠,就给每个包一个序号,同时序号也保证了传送到接收端实体的包的按序接收。然后接收端实体对已成功收到的字节发回一个相应的确认(ACK);如果发送端实体在合理的往返时延(RTT)内未收到确认,那么对应的数据(假设丢失了)将会被重传。
-
提供拥塞控制
当网络出现拥塞的时候,TCP能够减小向网络注入数据的速率和数量,缓解拥塞
- TCP提供全双工通信
TCP允许通信双方的应用程序在任何时候都能发送数据,因为TCP连接的两端都设有缓存,用来临时存放双向通信的数据。当然,TCP可以立即发送一个数据段,也可以缓存一段时间以便一次发送更多的数据段(最大的数据段大小取决于MSS)
TCP和UDP的比较
1. 对比
| UDP | TCP | |
|---|---|---|
| 是否连接 | 无连接 | 面向连接 |
| 是否可靠 | 不可靠传输,不使用流量控制和拥塞控制 | 可靠传输,使用流量控制和拥塞控制 |
| 连接对象个数 | 支持一对一,一对多,多对一和多对多交互通信 | 只能是一对一通信 |
| 传输方式 | 面向报文 | 面向字节流 |
| 首部开销 | 首部开销小,仅8字节 | 首部最小20字节,最大60字节 |
| 适用场景 | 适用于实时应用(IP电话、视频会议、直播等) | 适用于要求可靠传输的应用,例如文件传输 |
2. 总结
- TCP向上层提供面向连接的可靠服务 ,UDP向上层提供无连接不可靠服务。
- 虽然 UDP 并没有 TCP 传输来的准确,但是也能在很多实时性要求高的地方有所作为
- 对数据准确性要求高,速度可以相对较慢的,可以选用TCP
数据粘包
timewait
TCP UDP区别
ICMP协议
TCP的sync
timewait
11、windwos窗口
d2d
12、多态
多态的三个必要条件:
1.继承
2.重写
3.父类引用指向子类对象
重写和重载:
重载(overloading) 是在一个类里面,方法名字相同,而参数不同。返回类型可以相同也可以不同。
每个重载的方法(或者构造函数)都必须有一个独一无二的参数类型列表。
最常用的地方就是构造器的重载。
重写 Override 是子类对父类的允许访问的方法的实现过程进行重新编写, 返回值和形参都不能改变。即外壳不变,核心重写!
重写的好处在于子类可以根据需要,定义特定于自己的行为。 也就是说子类能够根据需要实现父类的方法。
13、容器
list 和queue的区别
list 链表
两端都可以插入和删除。
queue队列
先进先出
14、sdk
有一杯密封饮料,它的名字叫做“SDK”。
饮料上插着吸管,吸管的名字叫“API”。
把你叫做“XX系统”。
如果你想喝到SDK里的饮料(让系统拥有SDK中的功能),你必须通过API这根吸管来实现(通过API连接你的系统和SDK工具包),否则你就喝不到饮料。
所以:
SDK=放着你想要的软件功能的软件包
API=SDK上唯一的接口
SDK 就是 Software Development Kit 的缩写,翻译过来——软件开发工具包。这是一个覆盖面相当广泛的名词,可以这么说:辅助开发某一类软件的相关文档、范例和工具的集合都可以叫做SDK。
SDK被开发出来是为了减少程序员工作量的。
比如——
有公司开发出某种软件的某一功能,把它封装成SDK(比如数据分析SDK就是能够实现数据分析功能的SDK),出售给其他公司做开发用,其他公司如果想要给软件开发出某种功能,但又不想从头开始搞开发,直接付钱省事。
现在可以谈谈API和SDK的区别了。
总的来说,两者没有值得比较的区别,因为是具有关联性的两种东西。
你可以把SDK想象成一个虚拟的程序包,在这个程序包中有一份做好的软件功能,这份程序包几乎是全封闭的,只有一个小小接口可以联通外界,这个接口就是API。
比如——
我们现在要在企业ERP系统中增加某个功能(比如自动备份、数据分析、云存储等),但又不想耗费大量时间、也没那么多研发亲自去做这个功能。这时我们可以选择使用这个“SDK”软件包,把ERP系统连接上API接口,就可以使用SDK软件包里的功能。
15、_stdcall
__stdcall、__cdecl和__fastcall是三种函数调用协议,函数调用协议会影响函数参数的入栈方式、栈内数据的清除方式、编译器函数名的修饰规则等。
- 调用协议常用场合
-
- __stdcall:Windows API默认的函数调用协议。
- __cdecl:C/C++默认的函数调用协议。
- __fastcall:适用于对性能要求较高的场合。
- 函数参数入栈方式
-
- __stdcall:函数参数由右向左入栈。
- __cdecl:函数参数由右向左入栈。
- __fastcall:从左开始不大于4字节的参数放入CPU的ECX和EDX寄存器,其余参数从右向左入栈。
- 问题一:__fastcall在寄存器中放入不大于4字节的参数,故性能较高,适用于需要高性能的场合。
- 栈内数据清除方式
-
- __stdcall:函数调用结束后由被调用函数清除栈内数据。
- __cdecl:函数调用结束后由函数调用者清除栈内数据。
API中 使用cdecl
C++-dllexport与dllimport介绍和使用_mrbone11的博客-CSDN博客_c++ dllimport
dllimport
dllexport
dllexport与dllimport
dllexport与dllimport存储级属性是微软对C和C++的扩展,可用于从dll中导入或导出函数、数据、对象(objects)这些属性显式地定义了dll提供给客户端的接口,客户端可以是一个可执行文件或者另一个dll。dllexport声明的使用免去了模块定义(.def)文件的使用,def文件至少包含相关导出函数的声明。
dllexport暴露的是函数的修饰名(decorated name)1。如果想避免函数名修饰,使用C函数或者使用extern "C"2修饰C++函数。
_declspec(dllexport)
声明一个导出函数,是说这个函数要从本DLL导出。我要给别人用。一般用于dll中省掉在DEF文件中手工定义导出哪些函数的一个方法。当然,如果你的DLL里全是C++的类的话,你无法在DEF里指定导出的函数,只能用__declspec(dllexport)导出类
__declspec(dllimport)
声明一个导入函数,是说这个函数是从别的DLL导入。我要用。一般用于使用某个dll的exe中 不使用 __declspec(dllimport) 也能正确编译代码,但使用 __declspec(dllimport) 使编译器可以生成更好的代码。编译器之所以能够生成更好的代码,是因为它可以确定函数是否存在于 DLL 中,这使得编译器可以生成跳过间接寻址级别的代码,而这些代码通常会出现在跨 DLL 边界的函数调用中。但是,必须使用 __declspec(dllimport) 才能导入 DLL 中使用的变量。
API中 使用dllexport