本文来源于:Multi-Task Learning for Dense Prediction Tasks: A Survey
深度学习中的多目标优化问题
MTL中的一个重大挑战源于优化过程本身。特别是,我们需要仔细平衡所有任务的联合训练过程,以避免一个或多个任务在网络权值中具有主导影响的情况。极端情况下,当某个任务的loss非常的大而其它任务的loss非常的小,此时多任务近似退化为单任务目标学习,网络的权重几乎完全按照大loss任务来进行更新,逐渐丧失了多任务学习的优势.
人工定义多任务loss的权重是之前主要的使用方法,这种方法存在许多问题。模型性能对权重的选择非常敏感,这些权重作为超参数调整起来非常的费事费力,每次测试通常需要很多的时间。如图所示:
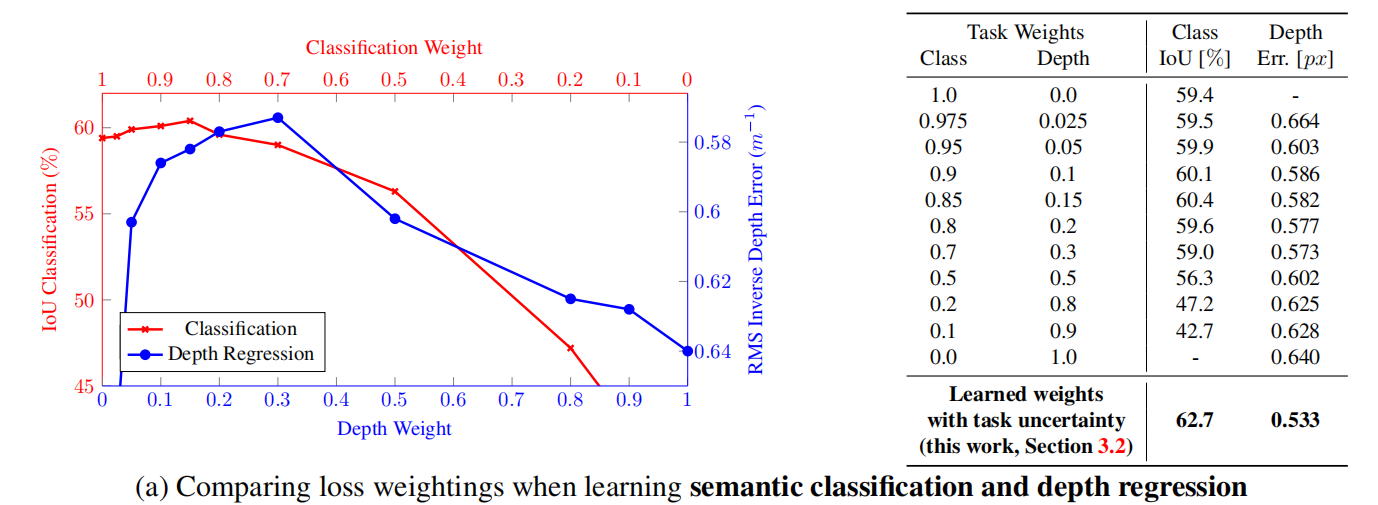
首先,当两个任务的梯度冲突时,网络权值的更新可能是次优的,或者当一个任务的梯度值比其他任务大得多时,网络权值的更新可能被一个任务主导。这促使研究者 [8],[19],[20],[21] 通过设置特定任务的权重来平衡梯度大小。为此,其他文献 [22],[26],[70] 也考虑了任务梯度方向的影响。
3.1.1 不确定性权重
Kendall et al. [19] 使用同方差的不确定性( homoscedastic uncertainty)来平衡单任务损失。同方差的不确定性或任务相关不确定性不是模型的输出,而是同一任务的不同输入示例保持不变的数量。优化过程是进行最大的高斯似然目标,说明同方差的不确定性。特别是对模型权重 W 和噪声参数 σ1、σ2 进行优化,以达到最小化以下目标,即公式(6)。
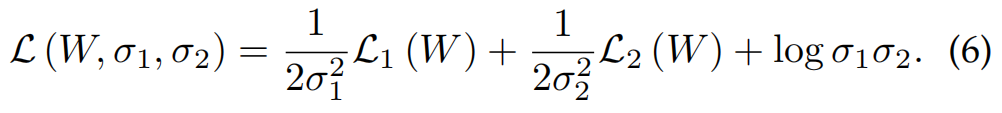
loss function L1 属于第一个 task, L2 属于第二个 task。通过最小化噪声参数 σ1、σ2 的损耗,可以在训练过程中基本平衡各任务的损耗。公式(6)中的优化目标也可以很容易地扩展到两个以上的任务。在训练过程中通过标准反向传播更新噪声参数。
需要注意的是,增加噪声参数 σi 会降低任务 i 的权值,因此当任务的同方差不确定性较高时,任务i对网络权值更新的影响较小。这在处理 noisy annotations 时很有优势,因为针对这类任务,特定于任务的权重将自动降低。
[19] A. Kendall, Y. Gal, and R. Cipolla, “Multi-task learning using uncertainty to weigh losses for scene geometry and semantics,” in CVPR, 2018
3.1.2 梯度标准化
梯度归一化 (GradNorm) [20] 提出通过刺激特定任务的梯度达到相似的量级来控制多任务网络的训练。通过这样做,网络被鼓励以相同的速度学习所有的任务。
[20] Z. Chen, V. Badrinarayanan, C.-Y. Lee, and A. Rabinovich, “Gradnorm: Gradient normalization for adaptive loss balancing in deepmultitask networks,” in ICML, 2018.
3.1.3 动态权重平均
与 GradNorm 类似,Liu et al. [8] 提出了一种技术,称为动态加权平均 (DWA),以平衡学习任务的速度。不同的是,DWA 只需要访问特定于任务的损失值。这就避免了在训练过程中为了获得特定于任务的梯度而执行单独的向后传递。在 DWA 中,将第 t 步任务 i 的任务特定权重 wi 设置为:
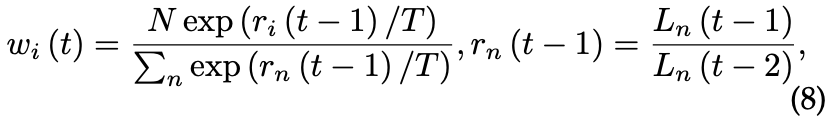
N是任务数。标量 rn(·) 估计任务特定损失值 Ln 的相对下降率。温度 T 控制 softmax 操作符中任务权重的柔软度。当一个任务的丢失速度比其他任务慢时,丢失中特定于任务的权重就会增加。
请注意,特定于任务的权重仅基于特定于任务的损失变化的速率。这种策略需要事先平衡总体损失的大小,否则在训练过程中,有些任务仍然可能压倒其他任务。GradNorm 通过单一目标平衡训练速率和梯度大小来避免这个问题 (见公式 7)。
[8] S. Liu, E. Johns, and A. J. Davison, “End-to-end multi-task learning with attention,” in CVPR, 2019.
3.1.4 动态任务优先级
第 3.1.1-3.1.3 节中的任务平衡技术选择优化特定任务的权重 wi 作为高斯似然目标的一部分,或者为了平衡学习不同任务的速度 [8],[20]。相反,动态任务优先级(DTP) [21] 选择通过分配更高的特定任务权重来优先考虑 “困难” 任务的学习。这样做的动机是,网络应该花更多的精力去学习 “困难” 的任务。注意,这与不确定性加权是相反的,不确定性加权会给 “简单” 的任务分配更高的权重。这两种技术并不一定冲突,但是不确定性加权似乎更适合于任务有噪声标记数据的情况,而当能够访问干净的真实注释时,DTP 更有意义。
为了测量任务难度,可以考虑使用由 GradNorm 定义的 loss ratio 在每个任务上的进展。然而,由于损耗率取决于初始损耗 ,它的值可能会有很大的噪声和初始化依赖。此外,使用损耗率度量任务进度可能不能准确地反映定性结果方面的任务进度。
因此,DTP 提出使用关键绩效指标 (KPIs) 来量化每个任务的难度。特别地,为每个任务 i 选择一个 KPI ,其中 0 < < 1。选择 是为了使其具有直观的含义,例如分类任务的准确性。对于回归任务,可以对预测误差进行阈值设置,以获得介于 0 和 1 之间的 KPI。
进一步,定义了一个任务级别的聚焦参数 ≥0,允许调整权重,在该权重下,容易或困难的任务被降低权重。DTP 将步骤t中任务i的任务特定权重 wi 设置为公式(9)
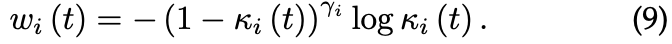
注意,公式 9 使用了一个焦损表达式(focal loss expression)[71] 来降低 “简单” 任务的特定任务权重。特别是,随着 KPI 的值增加,任务i的权重 wi 正在降低。DTP 需要仔细选择 KPI。例如,考虑选择一个阈值来度量回归任务的性能。根据阈值的值,特定于任务的权重在训练过程中会有所提高或降低。
得出结论,DTP 中 KPI 的选择不是以一种直接的方式确定的。此外,与 DWA 类似,DTP 需要事先平衡损失值的总体大小。毕竟,公式 9 在计算特定于任务的权重时没有考虑损失的大小。因此, DTP 仍然需要手动调优以设置特定于任务的权重。
[21] M. Guo, A. Haque, D.-A. Huang, S. Yeung, and L. Fei-Fei, “Dynamic task prioritization for multitask learning,” in ECCV, 2018
3.1.5 多任务学习作为多目标优化
对于公式 4 中的多任务优化目标,很难找到全局最优解。由于这个问题的复杂性,提高一个任务性能的某个选择可能会导致另一个任务的性能下降。之前讨论的任务平衡方法试图通过一些启发式的方法来设置损失中特定任务的权重来解决这个问题。不同的是,Sener 和 Koltun[22] 将 MTL 视为一个多目标优化问题,其总体目标是在所有任务中找到一个 Pareto 最优解。
在MTL中,只要满足以下条件,即在不增加任何任务损失的情况下,任何任务的损失都能减少,就能得到一个Pareto最优解。在 [22] 中提出了一种多重梯度下降算法 (MGDA)[72] 来寻找一个 Pareto 平稳点:通过在特定任务的梯度中找到一个共同的方向来更新共享的网络权重。只要有一个共同的方向可以降低特定任务的损失,还没有达到帕累托最优点。这种方法的优点是,由于共享网络权值只沿着特定任务梯度的共同方向更新,在权值更新步骤中避免了冲突梯度。
Lin et al. [23] 观察到 MGDA 只能从众多 Pareto 最优解中找到一个。此外,也不能保证所得到的解决方案能够满足用户的需求。为了解决这个问题,他们将 MGDA 推广到生成一组具有代表性的帕累托解,从中可以选择一个更优的解。然而,到目前为止,该方法仅适用于小规模数据集 (如 Multi-MNIST)。
[22] O. Sener and V. Koltun, “Multi-task learning as multi-objective optimization,” in NIPS, 2018.
[23] X. Lin, H.-L. Zhen, Z. Li, Q.-F. Zhang, and S. Kwong, “Pareto multi-task learning,” in NIPS, 2019.
[72] J.-A. D´esid´eri, “Multiple-gradient descent algorithm (mgda) for multiobjective optimization,” Comptes Rendus Mathematique, 2012
密集预测任务的多任务学习(Multi-Task Learning)研究综述 - 优化方法篇_Phoenixtree_DongZhao的博客-CSDN博客