论文:https://link.springer.com/chapter/10.1007/978-3-030-58580-8_34
代码:原来的不维护了,升级后的PointContrast,https://github.com/facebookresearch/ContrastiveSceneContexts
1. 介绍
目前3D自监督学习落后于2D的原因主要有以下几点:
- 缺乏大规模和高质量的数据: 与2D图像相比,3D数据更难收集,标签更昂贵,并且传感设备的多样性可能会带来巨大的领域差距 。
- 缺乏统一的主干(backbone),不像2D中有的Resnet是微调和预训练的主干网络。
- Lack of a 全面的数据集 and high-level tasks for evaluation(评估)
针对上面问题提出的想法:
研究无监督预训练和有监督微调来推动 3D 场景理解。
-
选择大型数据集(ScanNet)用于预训练
-
确定可以跨许多不同任务共享的骨干架构backbone(稀疏残差U-Net);
-
评估预训练主干网络的无监督指标( 评估预训练效果的方法 ) Hardest-contrastive loss + PointInfoNCE loss
-
定义了一组用于不同下游任务的评估办法
–>语义分割:S3DIS,ScanNetV2,ShapeNetPart,Synthia 4D
–>目标检测: SUN RGB-D, ScanNetV2
作者的做法:
预训练使用Scannet
主干网络:U-Net
预训练目标中两个对比损失:Hardest-contrastive loss [10], and PointInfoNCE [42](2D中的)
目标数据集和下游任务,包括: S3DIS [2],ScanNetV2 [11],ShapeNetPart [77] 和Synthia 4D [52] 上的语义分割; 以及SUN rgb-d [57、55、32、70] 和ScanNetV2上的对象检测。
语料 此外,我们发现在监督下进行预培训的优势相对较小。这意味着未来在收集数据以进行预培训方面的努力应偏向于规模而不是精确的注释。
作者的贡献:
- 首次评估了3D点云的高级表达在不同场景中的转移性 .
- 实验结果表明,无监督预训练可以有效提高不同下游任务、数据集的性能
- 在强大的无监督预训练下,在6各不同的基准(benchmarks)上实现最佳效果。
- 本文的成功可以推动更多在相关方面的研究 。
2. 相关工作
3D表示学习
深度神经网络渴望数据。这使得在数据集和任务之间传输学习到的表示的能力非常强大。
在这里,我们希望通过专注于在更复杂的场景中对更高级别的任务的可传递性来推动3D表示学习的研究。
点云处理的深度架构
在这项工作中,我们专注于学习点云数据的有用表示 。。。 在这项工作中,我们在所有实验中使用由Minkowski引擎构建的统一U-Net [51] 体系结构作为骨干网络,并表明它可以在任务和数据集之间优雅地传输。
3. 方法
(第 3.1 节) 试点研究: ShapeNet的预训练有用吗?
以前关于点云的无监督学习都集中在ShapeNet上。ShapeNet本身是一个单对象的CAD数据集。 作者在ShapeNet上做了一个有监督的预训练,并在下游数据集S3DIS上进行微调。实验结果表明预训练几乎没有给下游任务带来任何收益,反倒看上去有一定的反作用。
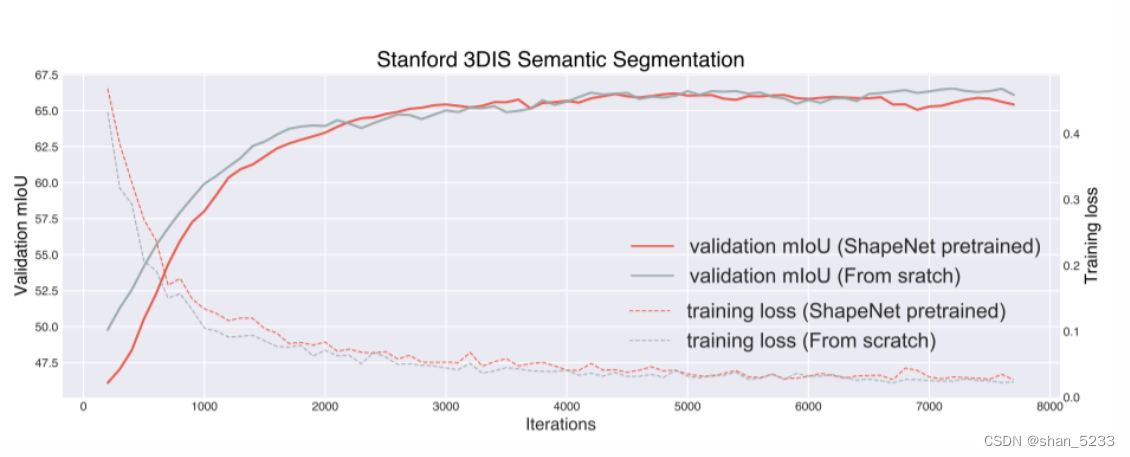
我们强调了 shapenet预训练对于downstream没有帮助的两个主要原因和解决办法:
-
源数据和目标数据之间的域差距:ShapeNet 中的对象是合成的、比例标准化、姿势对齐并且缺乏场景上下文。这使得预训练和微调数据分布截然不同。 针对域差距:可以在具有复杂场景的数据集scannet中训练,而不是ShapeNet那样的"干净"的数据集
-
点级表示很重要:在 3D 深度学习中,局部几何特征,例如那些由点及其邻居编码的点,已被证明对 3D 任务很重要 [47, 48]。直接训练对象实例以获得全局表示可能是不够的。 针对这个问题pointcontrast,为了捕获点级别的信息,需要相应的任务和框架,这个框架不仅仅是基于实例/全局表示的,而且可以在点级别捕获密集/局部的特征 。
(第 3.2 节)回顾(FCGF)局部特征学习全卷积几何特征
在论文中,作者采用一种稀疏tensor来表示3D数据,采用Minkowski卷积代替传统卷积,提出了ResUNet用于提取输入点云中每个点的特征,另外提出了新的loss用于全卷积度量学习。该网络不需要数据预处理(提取简单特征),也不需要patch的输入,而且能够产生具有SOTA区分性的高分辨率特征。作者在3DMatch数据集和KITTI数据集中验证了FCGF(Fully Convolutional Geometric Features)的表示能力和提取特征的速度。
FCGF优点:
(1) 全卷积设计和 (2) 点级度量学习。通过全卷积网络 (FCN) [38] 设计,FCGF 在整个输入点云(例如完整的室内或室外场景)上运行,而无需像以前的工作那样将场景裁剪成补丁;通过这种方式,局部描述符可以聚合来自大量相邻点的信息(达到感受野大小的范围)。因此,点级度量学习变得很自然。 FCGF 使用具有全分辨率输出的 U-Net 架构(即对于 N 个点,网络输出 N 个相关的特征向量),并且在点级别定义用于度量学习的正/负对。尽管心中有一个根本不同的目标,但 FCGF 提供了可能解决借口任务设计挑战的灵感:全卷积设计将使我们能够对涉及具有大量点的复杂场景的目标数据分布进行预训练,并且我们可以直接在点上定义代理任务。在这个视角下,我们提出了一个问题:我们能否将 FCGF 重新用作高级 3D 理解的借口任务?
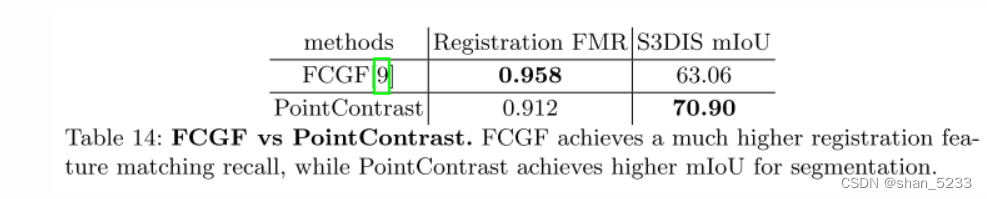
我们采用了在 [10] 中发布的性能最佳的FCGF模型,该模型实现了: 0.958的高注册特征匹配召回 (FMR)。但是,该模型对于S3DIS分割效果不佳。另一方面,在应用于注册任务时,对分割性能最佳的点对比模型可实现较低的FMR。我们得出的结论是,3D中的低级任务和高级任务可能需要不同的设计选择。
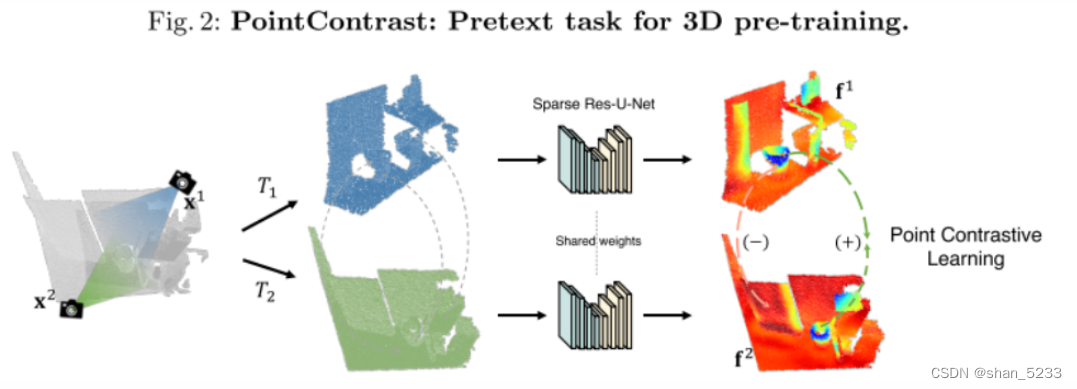
(第 3.3 节)无监督预训练PointContrast作为一个代理任务
在自监督任务的设计上,文章参考了FCGF,对一个点云进行两种变换(旋转、平移和尺度缩放), 通过变换,可以让网络适应变化的方差,有助于迁移到任何数据集 ,然后使用contrastive loss对两种视角下点云的点进行对比学习,最小化匹配的点对之间的距离,同时最大化不匹配的点之间的距离,网络需要学习到几何变换下的不变性。
算法流程 :此代理任务是在两个转换后的点云之间进行对比 (在点级别)。 从概念上讲,给定从某个分布采样的点云x , 我们首先扫描生成两个点云x1和x2,它们在相同的世界坐标中对齐(保证30%的重叠)。 然后分别对x1和x2进行随机刚体变换T1和T2,进一步将两个点云变成不同的视角加大任务的难度,然后分别对两个点云进行编码,进行对比学习训练。
下面的官方代码表明,直接处理的是点云数据哦不是图片。
通过这个方法训练的网络能够捕获点的局部信息,又能适应较大的变化方差,就可以进行一系列的下游任务了。
(第 3.4 节)设计的两个对比损失函数
Hardest-Contrastive Loss : 参考了FCGF中效果最好的损失函数,是一种基于难例挖掘的margin-based对比损失函数 。
PointInfoNCE Loss : 参考自CV中的InfoNCE,它将对比学习考虑为一个分类问题,并使用softmax loss进行建模 。
相比于Hardest-Contrastive Loss,PointInfoNCE训练更稳定。
(第 3.5 节) 稀疏残差U-Net作为共享backbone
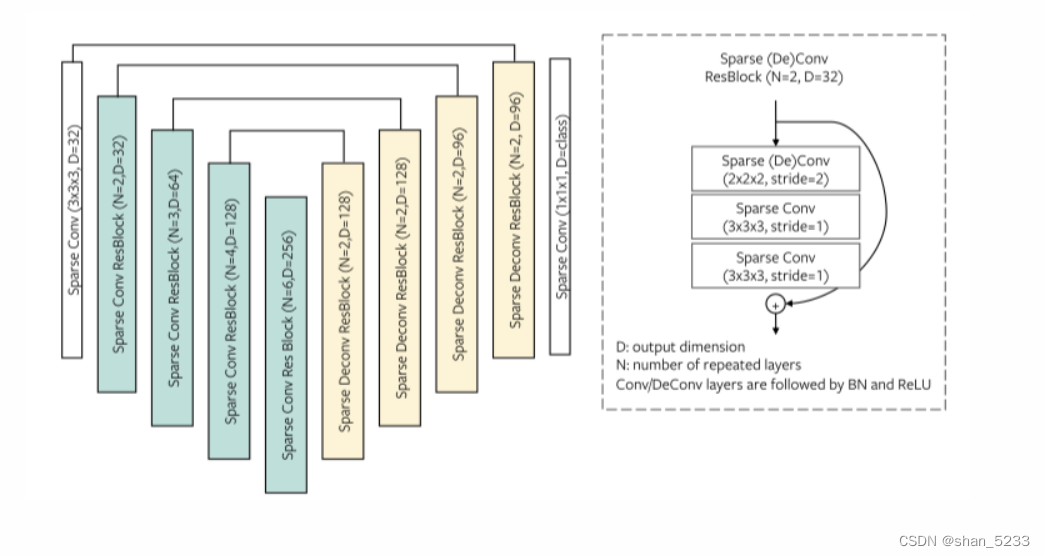
我们在这项工作中使用稀疏残差 U-Net (SR-UNet) 架构。它是一个 34 层的 U-Net [51] 架构,具有 21 个卷积层的编码器网络和 13 个卷积/反卷积层的解码器网络。它遵循 2D ResNet 基本块设计,网络中的每个 conv/deconv 层后跟批量归一化 (BN) [31] 和 ReLU 激活。整个 U-Net 架构有 3785 万个参数。我们在附录中提供了更多信息和网络可视化。 SR-UNet 架构最初是在 [9] 中设计的,在具有挑战性的 ScanNet 语义分割基准测试中,它比之前的方法有了显着改进。在这项工作中,我们探索是否可以将此架构用作预训练任务和一组不同的微调任务的统一设计。
附录可视化SR-UNET结构
我们用SR-UNet体系结构作共享骨干网,用于预培训和微调任务。对于分割和检测任务,编码器和解码器权重均进行微调; 对于分类下游任务,仅保留编码器网络并进行微调
(第 3.6 节)预训练数据集
对于局部几何特征学习方法,包括 FCGF [10],训练和评估通常在领域和任务特定的数据集上进行,例如 KITTI 里程计 [17] 或 3DMatch [81]。常见的注册数据集通常在规模(仅从几十个场景中收集的训练样本)或通用性(专注于一个特定的应用场景,例如室内场景或自动驾驶汽车的 LiDAR 扫描)方面受到限制,或两者兼而有之。为了促进未来对 3D 无监督表示学习的研究,在我们的工作中,我们利用 ScanNet 数据集进行预训练,旨在解决规模问题。 ScanNet 是约 1500 个室内场景的集合。 ScanNet 采用轻量级 RGB-D 扫描程序创建,是目前同类产品中最大的。
在这里,我们在 ScanNet 之上创建了一个点云对数据集。给定一个场景 x,我们从不同的视图中提取成对的部分扫描 x1 和 x2。更准确地说,对于每个场景,我们首先每 25 帧从原始 ScanNet 视频中对 RGB-D 扫描进行子采样,并在相同的世界坐标中对齐 3D 点云(通过为每个帧使用估计的相机姿势)。然后我们从采样帧中收集点云对,并要求一对中的两个点云至少有 30% 的重叠。我们总共采样了 870K 个点云对。由于局部视图在 ScanNet 场景中是对齐的,因此可以直接计算两个视图之间的对应映射 M 与最近邻搜索。尽管 ScanNet 仅捕获室内数据分布,正如我们将在第 4.4 节中看到的那样,令人惊讶的是它可以推广到其他目标分布。我们在附录中为预训练数据集提供了额外的可视化效果
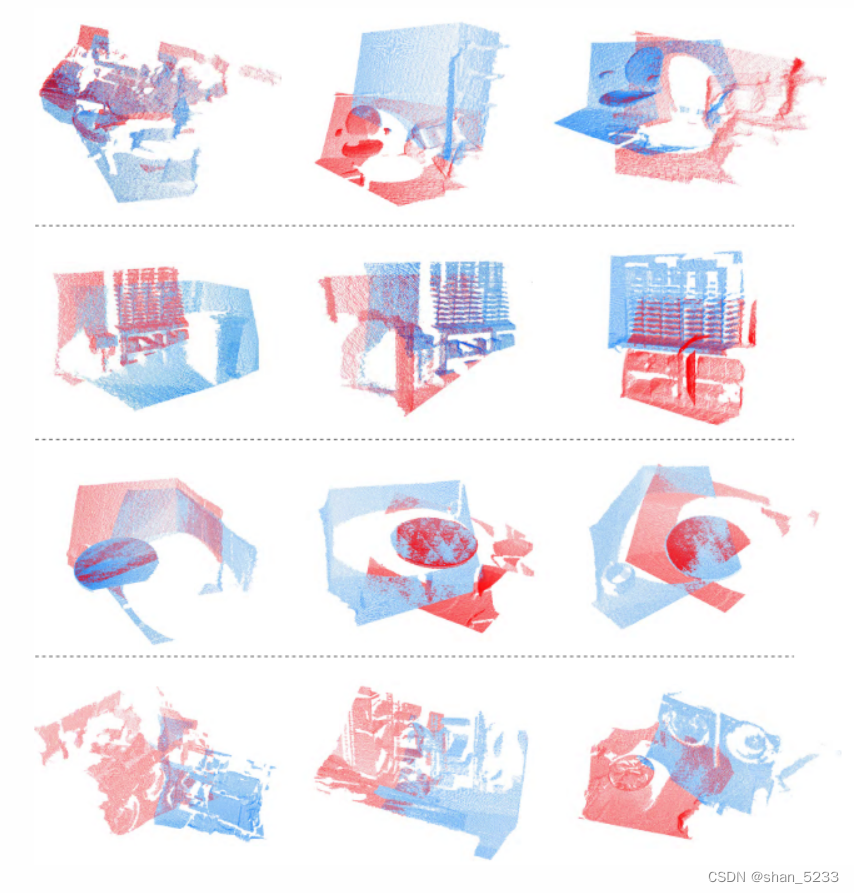
附录:可视化scannet中的点云对
每行都是一个随机采样的场景。每列都是从同一场景中采样的一对不同的点云。不同的颜色对应两个不同的视图(部分扫描)。至少有 30% 的点在两个视图中重叠。
微调下游任务
表示学习的最重要动机是学习可以很好地转移到不同下游任务的功能。可能有不同的评估协议来衡量所学表示的有用性。例如,使用线性分类器进行探测 [19],或者在半监督设置中进行评估 [27]。监督微调策略将预先训练的权重用作初始化,并在目标下游任务上进一步细化,可以说是评估特征可传递性的最实际的方法。通过此设置,良好的功能可能会直接导致下游任务的性能提高。
从这个角度来看,在本节中,我们通过微调多个下游任务和数据集上的预训练权重,对 PointContrast 框架的有效性进行了广泛的评估。我们的目标是涵盖一系列不同性质的高级 3D 理解任务,例如语义分割、对象检测和分类。在所有实验中,我们使用相同的主干网络,使用 PointInfoNCE 和 Hardest-Constrastive 损失目标在建议的 ScanNet 对数据集(第 3.6 节)上进行预训练。
4.2 S3DIS分割
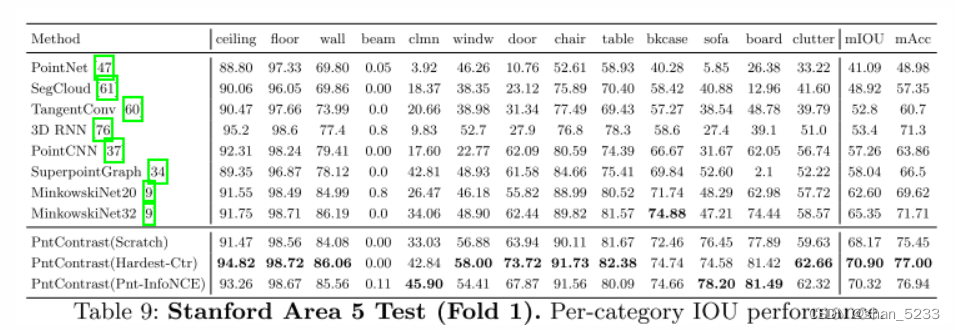
SetUp。斯坦福大型3D室内空间 (S3DIS) [2] 数据集包括从3栋办公楼收集的6个大型室内区域的3D扫描。扫描表示为点云,并用13个对象类别的语义标签进行注释。在这里用于评估的数据集中,S3DIS可能与ScanNet最相似。将特征转移到S3DIS代表了微调的典型场景: **下游任务数据集相似,但比预训练数据集小得多。**对于常用的基准分割 (“区域5测试一下”),训练集中只有大约240个样本。我们遵循 [9] 进行预处理,并使用标准数据扩充。详见附录。
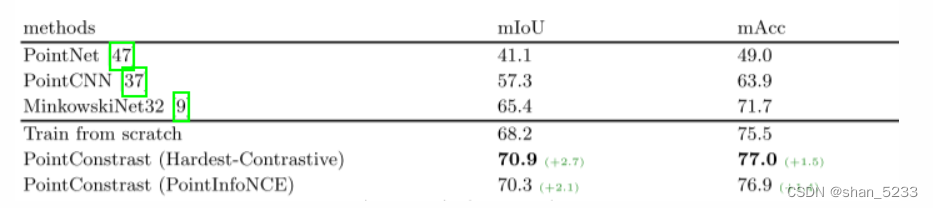
result: 使用 Hardest-Contrastive 损失实现了 2.7% 的 mIoU 增益,并且 PointInfoNCE 变体实现了 2.1% mIoU 的平均改进
附录详细的PointContrast预训练
在我们的实验中,应用于两个视图 x1 和 x2 的 T1 和 T2变换 涉及沿任意轴的随机旋转(0 到 360°)(独立应用于两个视图)。我们将比例增强应用于两个视图(输入比例的 0.8 到 1.2 倍)。我们已经尝试了其他增强功能,例如平移、点坐标抖动和点丢失,但没有发现微调性能有明显差异。
对于最难的对比损失,正样本大小为 1024,最难的负样本大小为 256。更多细节可以在 [10] 中找到。对于 PointInfoNCE 损失,我们在算法 2 中提供了详细的类似 PyTorch 的伪代码(和解释性注释)。
附录:S3DIS 分割实验细节
我们使用相同的超参数设置。具体来说,我们用8 V100 gpu训练模型,并具有10,000迭代的数据并行性。批量大小为48。批标准化在每个GPU上独立应用。我们使用具有初始学习率0.8的SGD动量优化器。我们使用功率因数为0.9的多项式LR调度器。重量衰减是0.0001的,体素大小是0.05的 (5厘米)。我们在 [9] 中使用相同的数据增强技术,例如色相/饱和度增强和抖动,以及比例增强 (0.9 × 至1.1 ×)。在表9中,我们显示了我们的模型和以前的方法的详细的每个类别的性能细分。