SimMatch: Semi-supervised Learning with Similarity Matching
现有的半监督学习策略:
- 在一个大规模数据集上进行预训练,并用少量标签数据微调
(缺点在于,完全未利用到标签信息) - 使用有标签数据训练一个语义分类器,并通过这个分类器为无标签数据生成伪标签(pseudo label)。伪标签通常由弱视图或多个增强视图的平均预测产生。最后目标通过多个强增强视图和伪标签之间的交叉熵来构建
(缺点在于,当标签数据十分有限时,所训练的语义分类器并不可靠,由此生成的伪标签将会出现“overconfidence”问题,即模型会去拟合那些置信度很好但是错误的伪标签,由此导致性能下降)
本文方法
- 首先,希望强增强视图和弱增强视图具有相同的语义相似性(预测的标签)
- 强增强视图与弱增强视图具有相同的实例特征(即实例之间的相似性),以便于进行更多的内在特征匹配

方法
语义相似性
对于有标签样本,
- 对batch中所有样本随机应用一种弱增强 T w ( ⋅ ) T_w(\cdot) Tw(⋅)(例如旋转或裁剪)
- 用一个encoder F ( ⋅ ) F(\cdot) F(⋅)提取特征信息,即 h = F ( T ( x ) ) h=\mathcal{F}(T(x)) h=F(T(x))
- 采用一个全连接类别预测头 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)将 h b \mathbf{h}_b hb映射为语义相似度 ,即 p = ϕ ( h ) p=\phi{(\mathbf{h})} p=ϕ(h)
其中,有标签样本直接使用交叉熵损失进行优化:
L s = 1 B ∑ H ( y , p ) \mathcal{L}_s=\frac{1}{B}\sum{\mathrm{H}(y,p)} Ls=B1∑H(y,p)
对于无标签样本,
-
随机应用弱增强或强增强的一种,并使用和有标签样本相同的处理方式,得到语义相似度 p w p^w pw和 p s p^s ps
-
计算两种标签之间的无监督损失:
L u = 1 μ B ∑ 1 ( max D A ( p w ) > τ ) H ( D A ( p w ) , p s ) \mathcal{L}_{u}=\frac{1}{\mu B} \sum \mathbb{1}\left(\max D A\left(p^{w}\right)>\tau\right) \mathrm{H}\left(D A\left(p^{w}\right), p^{s}\right) Lu=μB1∑1(maxDA(pw)>τ)H(DA(pw),ps)
这里 τ \tau τ作为置信度阈值,且仅保留在伪标签中最大类别概率大于 τ \tau τ的无标签样本。 D A ( ⋅ ) DA(\cdot) DA(⋅)表示分布对齐策略,用于平衡伪标签的分布。
实例相似性
目的是希望强增强视图与弱增强视图具有类似的相似性分布。
-
这里引入一个非线性映射头 g ( ⋅ ) g(\cdot) g(⋅),能将特征表示 h \mathbf{h} h映射为一个低维嵌入,即 z b = g ( h b ) \mathbf{z}_b=g(\mathbf{h}_b) zb=g(hb)
-
遵循基于anchoring的方法,这里将 z b w \mathbf{z}^w_b zbw和 z b s \mathbf{z}^s_b zbs分别表示为来自弱增强和强增强的嵌入
-
现在,假设对于一簇不同的样本 z k : k ∈ ( 1 , … , K ) {\mathbf{z}_k:k \in(1, \dots,K)} zk:k∈(1,…,K),具有K个弱增强嵌入,使用相似度函数 s i m ( ⋅ ) sim(\cdot) sim(⋅)计算 z w \mathbf{z}^w zw和第i个实例 z i \mathbf{z}_i zi之间的相似度:
sim ( u , v ) = u T ^ v ∥ u ∥ ∥ v ∥ \operatorname{sim}(\mathbf{u}, \mathbf{v})=\frac{\mathbf{u}^{\hat{T}} \mathbf{v}}{ \|\mathbf{u}\|\|\mathbf{v}\|} sim(u,v)=∥u∥∥v∥uT^v
使用softmax函数处理相似度计算结果,得到相似度分布:
q i w = exp ( sim ( z b w , z i ) / t ) ∑ k = 1 K exp ( sim ( z b w , z k ) / t ) q_{i}^{w}=\frac{\exp \left(\operatorname{sim}\left(\mathbf{z}_{b}^{w}, \mathbf{z}_{i}\right) / t\right)}{\sum_{k=1}^{K} \exp \left(\operatorname{sim}\left(\mathbf{z}_{b}^{w}, \mathbf{z}_{k}\right) / t\right)} qiw=∑k=1Kexp(sim(zbw,zk)/t)exp(sim(zbw,zi)/t)
其中 t t t为温度系数,用于控制分布的平滑程度。 -
同样计算 z s \mathbf{z}^s zs和 z i \mathbf{z}_i zi之间的相似度分布:
q i s = exp ( sim ( z b s , z i ) / t ) ∑ k = 1 K exp ( sim ( z b s , z k ) / t ) q_{i}^{s}=\frac{\exp \left(\operatorname{sim}\left(\mathbf{z}_{b}^{s}, \mathbf{z}_{i}\right) / t\right)}{\sum_{k=1}^{K} \exp \left(\operatorname{sim}\left(\mathbf{z}_{b}^{s}, \mathbf{z}_{k}\right) / t\right)} qis=∑k=1Kexp(sim(zbs,zk)/t)exp(sim(zbs,zi)/t) -
最后,可以通过最小化 q s q^s qs和 q w q^w qw之间的差异实现一致性正则化(consistency regularization),这里采用交叉熵损失实现:
L i n = 1 μ B ∑ H ( q w , q s ) \mathcal{L}_{i n}=\frac{1}{\mu B} \sum \mathrm{H}\left(q^{w}, q^{s}\right) Lin=μB1∑H(qw,qs)
这里需要注意的是,这种实例的一致性正则化只应用于无标签样本。
最终的损失函数为:
L overall = L s + λ u L u + λ i n L i n \mathcal{L}_{\text {overall }}=\mathcal{L}_{s}+\lambda_{u} \mathcal{L}_{u}+\lambda_{i n} \mathcal{L}_{i n} Loverall =Ls+λuLu+λinLin
其中, λ u \lambda_u λu和 λ i n \lambda_{in} λin是控制两种损失权重的平衡因子。
通过SimMatch 进行标签传播
由于上述过程完全未利用到标签信息,这里进一步介绍一种能利用到标签信息的方法,并允许语义相似性和实例相似性相互交互。
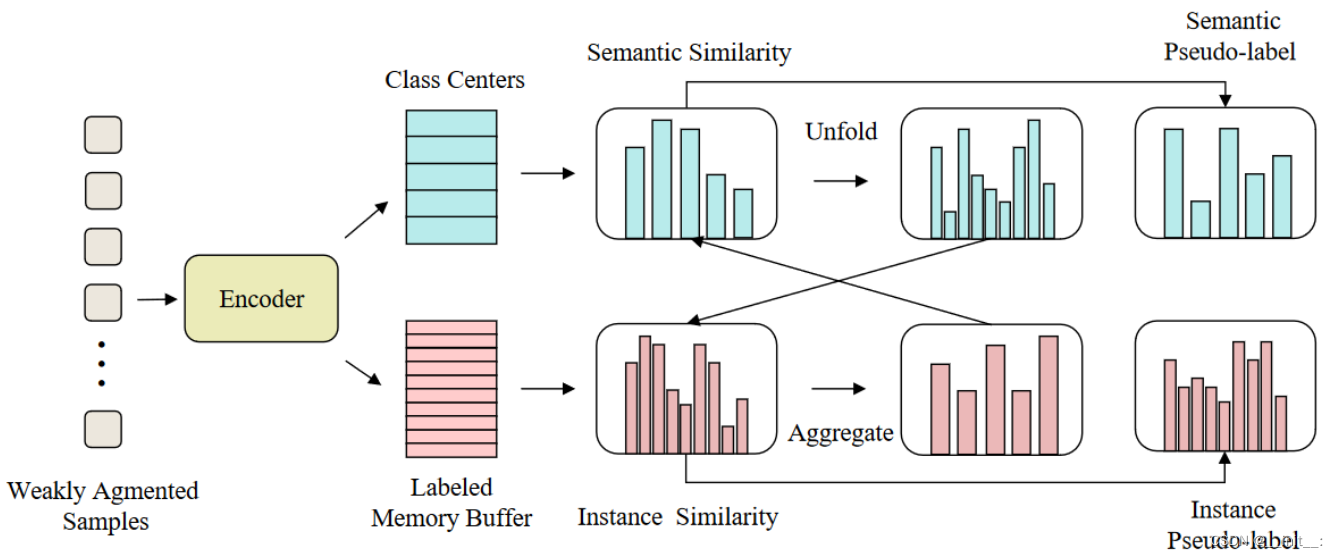
具体做法:
-
实例化一个带标签的内存缓冲区,用于存放所有标注的样本( q i w q_i^w qiw和 q i s q_i^s qis),这样使得每个用到的样本都被指定一个特定的类别。
如果我们将 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)中的向量(由有标签样本生成)解释为"中心化"的类引用,那么我们标记的内存缓冲区中的embedding(由无标签样本生成)可以看作是实例个体引用的集合。
-
给定一个弱增强样本,文中首先计算它的语义相似度(可以认为是类别标签) p w ∈ R 1 × L p^w \in \mathbb{R}^{1 \times L} pw∈R1×L和实例相似度 q w ∈ R 1 × K q^w \in \mathbb{R}^{1 \times K} qw∈R1×K(这里L一定是远小于K的,因为文中希望每个类别至少具有一个样本(L即为类别数))
使用语义相似度来校准实例相似度
-
为了使用 p w p^w pw 校准 q w q^w qw,我们需要将 p w p^w pw展开到 K K K维空间,文中将其表示为 p u n f o l d p^{unfold} punfold。文中通过为每个已标记的嵌入匹配相应的语义相似性来实现这一点,即:
p i u n f o l d = p j w , where class ( q j w ) = class ( p i w ) p_{i}^{u n f o l d}=p_{j}^{w}, \text { where } \operatorname{class}\left(q_{j}^{w}\right)=\operatorname{class}\left(p_{i}^{w}\right) piunfold=pjw, where class(qjw)=class(piw)
其中, c l a s s ( ⋅ ) class(\cdot) class(⋅)是返回ground truth类别的函数。具体来说, c l a s s ( q j w ) class(q^w_j) class(qjw)表示内存缓冲区中第j个元素的标签, c l a s s ( p i w ) class(p^w_i) class(piw)表示第i个类。
-
接下来,通过使用 p u n f o l d p^{unfold} punfold对 q w q^w qw进行缩放来重新生成校准后的实例的伪标签,可以表示为如下形式:
q ^ i = q i w p i u n f o l d ∑ k = 1 K q k w p k unfold \widehat{q}_{i}=\frac{q_{i}^{w} p_{i}^{u n f o l d}}{\sum_{k=1}^{K} q_{k}^{w} p_{k}^{\text {unfold }}} q i=∑k=1Kqkwpkunfold qiwpiunfold -
将校准后的伪标签 q ^ \hat{q} q^作为新的目标并替代之前计算损失 L i n \mathcal{L}_{in} Lin中的 q w q^w qw
使用实例相似度调整语义相似度
-
首先将 q q q汇聚到 L L L维空间,记为 q a g g q^{agg} qagg,通过对具有相同ground-truth的实例求和进行实现:
q i a g g = ∑ j = 0 K 1 ( class ( p i w ) = class ( q j w ) ) q j w q_{i}^{a g g}=\sum_{j=0}^{K} \mathbb{1}\left(\operatorname{class}\left(p_{i}^{w}\right)=\operatorname{class}\left(q_{j}^{w}\right)\right) q_{j}^{w} qiagg=j=0∑K1(class(piw)=class(qjw))qjw -
通过使用 q a g g q^{agg} qagg平滑 p w p^w pw重新生成调整过的语义伪标签,:
p ^ i = α p i w + ( 1 − α ) q i a g g \widehat{p}_{i}=\alpha p_{i}^{w}+(1-\alpha) q_{i}^{a g g} p i=αpiw+(1−α)qiagg
其中 α \alpha α作为超参数控制语义信息和实例信息的权重 -
同样地,将校准后的伪标签 p ^ \hat{p} p^作为新的目标并替代之前计算损失 L u \mathcal{L}_{u} Lu中的 p i w p^w_i piw
-
此时,伪标签 p ^ \hat{p} p^和 q ^ \hat{q} q^便都具有语义和实例级别的信息

其意义在于:当语义相似度和实力相似度接近时,意味着两个分布与彼此的预测一致,由此生成的伪标签将具有更高的置信度,从而更加可靠

整个训练过程如图所示。
细节实现
unfold操作
batch_u = 1
num_class = 10
K = 256
prob_ku_orig = torch.zeros((batch_u, num_class)) #(1, 10)
labels = torch.zeros(K, dtype=torch.long) #(256, )
index = labels.expand([batch_u, -1]) #(1, 256)
factor = prob_ku_orig.gather(1, index) # p^{unfold}
print(prob_ku_orig.shape, factor.shape)
# torch.Size([1, 10]) torch.Size([1, 256])
# e.g.
prob = torch.tensor([[0.15, 0.8, 0.05]])
print(prob)
labels = torch.tensor([1,0,0,2,1])
index = labels.expand([1, -1])
prob.gather(1, index)
# tensor([[0.8000, 0.1500, 0.1500, 0.0500, 0.8000]])
aggregate操作
bs = teacher_prob_orig.size(0) # batch_u
aggregated_prob = torch.zeros([bs, self.num_classes], device=teacher_prob_orig.device)
aggregated_prob = aggregated_prob.scatter_add(1, self.labels.expand([bs,-1]), teacher_prob_orig) #q^{agg}