点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文针对声音图像分割问题(audio-visual segmentation[AVS])提出了一种更高效合成数据集VPO以及一个像素级对比学习训练策略来更有地验证AVS问题并且有效地提升声音图像关联. 单位: 阿德莱德大学,萨里大学.

A Closer Look at Audio-Visual Semantic Segmentation
文章链接:https://arxiv.org/abs/2304.02970
视听分割任务(audio-visual segmentation[AVS])主要是把声音信号和图像进行像素级别的匹配。成功的视听学习需要两个基本组成部分:1)具有高质量像素级多类标签的无偏数据集,2)能够有效地将音频信息与其相应的视觉对象链接起来的模型。然而,当前的方法仅部分解决了这两个要求。我们通过验证发现, 现有的模型并没有效地学习视觉和声音信号的关联性。例如下图的一个例子,尽管声音的信号发生了改变, 但是模型的预测始终没有改变。基于这一现象, 我们怀疑1) 数据集合潜藏的一种规律(特定物体在特定场景永远是发生源)影响了模型的泛化性。2) 模型更倾向于建立视频中运动物体于发生物体的关联。此外, 视听分割问题需要大量有标注数据进行模型训练, 考虑到标注师需要在标注的同时监听音频来进行选择性标注, 因此其标注的时间成本会较大。针对以上问题, 通过实验我们发现, 我们可以根据图像的视觉对象的语义类别来匹配图像 (COCO)和音频来获得音视频数据 (VGGSound)利用现有的数据集来构建AVS数据集, 并且这种离散的声音视觉配对可以把物体的移动信息排除在外。除此之外, 我们再次利用这种声音图像配对的方法来为监督对比学习提供更丰富的正集和负集从而提升表征的表现和模型性能。

主要贡献
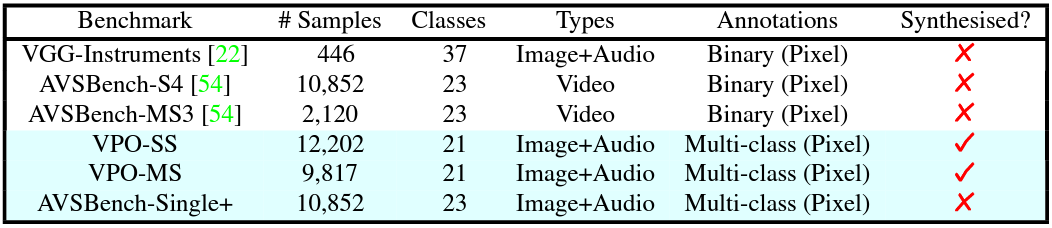
A new strategy to build cost-effective and relatively unbiased semantic segmentation benchmarks, called Visual Post-production (VPO). The VPO benchmark pairs image (from COCO) and audio (from VGGSound) based on the semantic classes of the visual objects of the images. We propose two new VPO benchmarks based on this strategy: the single sound source (VPO-SS) and multiple sound sources (VPO-MS).
An extension of the benchmark AVSBench-Single called AVSBench-Single+, which restores the original image resolution and represents semantic segmentation masks with multi-class annotations.
A new AVS method trained with the new objective function CAVP that randomly matches audio and visual pairs to form rich ``positive'' and ``negative'' contrastive pairs to better constrain the learning of the audio-visual embeddings.
视听分割合成数据集 Visual Post-production (VPO)
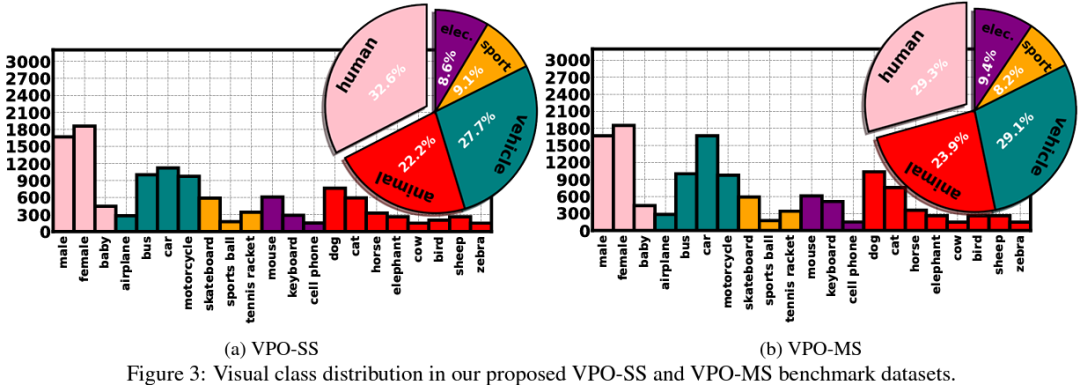
我们提出一种更丰富以及更高效的合成数据集VPO来更有效地验证视觉和听觉的对应关系。相较于之前的数据集,VPO可以在最低的收集成本上获得大量优质segmentation ground-truth以及更为复杂的场景。

实验方法 - Contrastive Audio-Visual Pairing (CAVP)
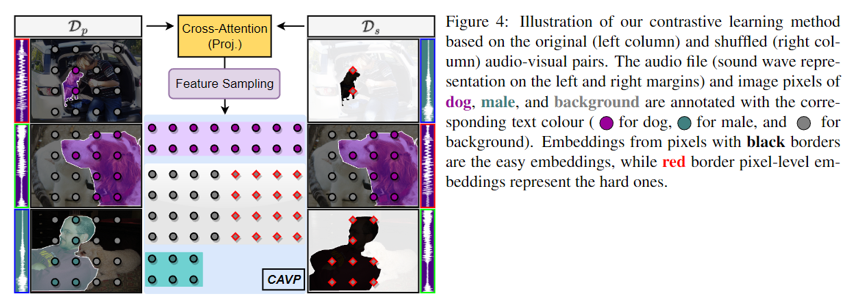
以前为视听定位设计的对比学习方法受到两个问题的挑战:
1)确认偏差,因为发声对象是通过伪标签自动定义的,2)假阳性检测率很高,因为正负关系的建模没有以像素方式明确考虑。我们通过用语义分割数据集中提供的像素级多类注释替换自动伪标签来解决第一个问题。为了解决第二点,我们基于VPO合成的基本思想,利用初始训练集以及一个视听随机分配的混洗集来形成包含不同正负对的丰富对比集以实现监督对比学习。
实验结果
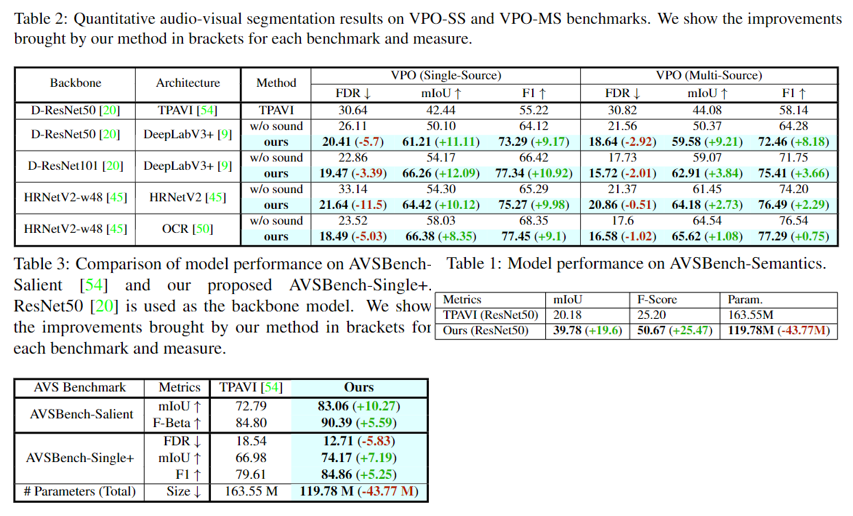
实验主要对比模型在AVSBench-Object, VPO以及AVSBench-Semantic在 mIoU, FDR和F1上的表现。实验结果表明,我们的方法在现有的视听分割数据集上明显优于现有的网络并且包含更少的参数。
最新CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()