本文内容主要是人工翻译自MySQL5.7官网手册——Innodb内存架构部分,读者可以结合官文手册阅读。如有错误请指出,感谢阅读,欢迎讨论!
1. Innodb架构图(MySQLv5.7 取自官网)

说明:上图包含了Innodb内存架构和磁盘架构,各自在后面作详细介绍。
1.1 Innodb内存架构
主要分一下几个要点
- Buffer Pool(buffer池)
- Change Buffer(更改buffer)
- Adaptive Hash Index(自适应hash索引)
- Log Buffer(日志buffer)
注:一般不对buffer作翻译
1.2 Buffer Pool
注意:为了编写方便,下文以bp代指Buffer Pool
Buffer Pool是mysql运行时使用的一块内存区域,用来存储/修改/访问Table和Index数据的内存区域。mysql用它存储了被频繁访问的数据。
理论上来说,它能使用的内存空间越大,mysql性能越好;所以在专门的mysql服务器上,一般分配物理内存的80%给Buffer Pool。
为了提升大容量数据的访问性能,bp内部分为可以容纳多行的页(Page)。
为了方便缓存数据的管理,bp又实现了由页组成的链表(linked list),数据的过期策略采用LRU算法实现。
了解如何利用缓冲池将经常访问的数据保存在内存中是 MySQL 调优的一个重要方面。
新链表与老链表(以下称new链表和old链表)
在单链表的基础上,bp又划分了new子链表和old子链表
- new子链表处于单链表的头部,占5/8;old处于尾部,占3/8
- new是经常被访问部分,old反之
- new和old分开管理
下图来自mysql官网
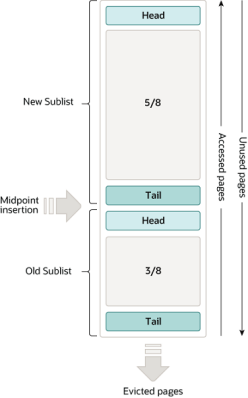

- 图中的midpoint是new和old的交接点
- 当从磁盘中读取的数据被插入链表时,第一次是插入old子链表的头部,old子链表中的数据被访问时会被移动到new子链表的头部(预读操作除外)
- new和old子链表中的页面会随着其他页面的更新而老化,未使用或少使用的页逐渐到达old子链表的尾部,然后并被驱逐(evicted)。
为什么要用双链表?
单链表情况下的缓存池污染
- 默认的机制是,page只要被读取就会被移动到链表头部。这在某些情况下会造成缓冲池污染!比如mysqldump操作或者不带WHERE的SELECT查询会一次性往bp页链表中存入大量的数据,并导致等量的数据老化失效。而这些操作是临时性的,读取的大量数据基本很长时间都不会被再次读取,这就造成了bp池污染,严重降低了mysql性能!
- 同样的原理,预读操作也会造成bp池污染!
双链表方案
- 区分new和old链表,使用old链表存储那些刚从磁盘加载的数据
- 不管是什么操作,数据从磁盘加载后,都是先存储old链表中,若这些数据在淘汰前再次被读取,说明它们的确是热数据,需要移到new链表的头部;否则就一直处于old链表,会以比new链表更快的速度被淘汰。
- 监控Buffer Pool状态
mysql> SHOW ENGINE INNODB STATUS
这条命令的输出较多,bp池的数据在BUFFER POOL AND MEMORY部分,以下数据截取自真实环境
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 137363456 // buffer pool总大小,所有空间的单位都是字节,这里是137MB左右
Dictionary memory allocated 16255176 // 为innodb字典分配的内存大小
Buffer pool size 8191 // 能容纳的page数量
Free buffers 1024 // free链表中有多少个空闲页
Database pages 6983 // LRU链表的总数据页数量
Old database pages 2557 // LRU链表中old链表的页数量
Modified db pages 191 // flush链表中的页数量
Pending reads 0 // 等待从磁盘加载的缓存页数量
Pending writes: LRU 0, flush list 0, single page 0 // 即将从LRU以及flush链表中刷入磁盘的数量,single page是buffer pool中正在写入的页数量
Pages made young 13484194, not young 8408292 // young表示LRU链表中从old迁移到new链表的页总数,后者是停留在old链表的缓存页数;这里的数值应该都是累计值。
400.95 youngs/s, 1.25 non-youngs/s // youngs/s是平均每秒从old链表移动到new链表的页数,后者是平均每秒old链表中被访问了但没有移动到new链表的页数
Pages read 411197, created 182724, written 5421234 // 从mysql启动到现在一共读取、创建、写入了的页数
1.12 reads/s, 0.12 creates/s, 7.37 writes/s // 平均每秒读取、创建、写入的页数
Buffer pool hit rate 1000/ 1000, young-making rate 16 / 1000 not 0 / 1000 // 平均每1000次访问mysql,多少次是命中buffer pool的,其中有多少页是访问后迁移到new链表的,多少次是访问old链表页但没迁移的(大部分应该都是访问的new链表)
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s // 预读缓存页的速度,淘汰未访问数据页的数量,随机预读速度
LRU len: 6983, unzip_LRU len: 0 // LRU链表中的总页数,unzip_LRU链表的总页数
I/O sum[369]:cur[0] // sum是缓冲池 LRU链表中被访问的数据页总数(直译),cur是刚刚这段时间间隙内访问的页数
unzip sum[0]:cur[0] // 前者是缓冲池 unzip_LRU链表解压缩的页总数(直译),后者是刚刚这段时间间隙内解压缩的页数
博主针对最后的I/O sum数值释义存疑,数据来自真实环境,这个值远小于“Pages made young”,在网上博主查到另一种解释:最近50s读取磁盘页的总数 (看起来更靠谱,但没在官方找到类似解释)
- Buffer Pool 配置调优
- 使用内存空间大的主机,为mysql配置更大的buffer pool size。因为mysql大部分的操作都是在内存中执行,多数数据只会从磁盘中加载一次,后续都是读内存,所以更大的bp size可以存更多的数据在内存中,性能更高!变量是
innodb_buffer_pool_size查看官网配置(如何配置请自行查询,本文不再赘述) - 如果是64位系统大内存的服务器,推荐配置多个buffer pool实例(instances),可以减小内存中对数据页的读写竞争,提高并发性能!相关变量是
innodb_buffer_pool_instances,不过官方要求是bp size>1GB,这个参数才会生效 查看官网配置 - 你可以将频繁访问的数据保留在内存中,而不考虑将大量不经常访问的数据带入缓冲池的操作,这是在双链表的基础上继续调整,相关变量是
innodb_old_blocks_pct,innodb_old_blocks_time查看官网配置 - 你可以控制如何以及何时执行预读(称作prefetch或read-ahead)请求以异步地将页面预取到缓冲池中,相关变量是
innodb_read_ahead_threshold,innodb_random_read_ahead查看官网配置 - 你可以控制bp中的脏页数据刷盘的时机,以及决定是否允许刷盘速率根据实时负载自动调整,相关变量是
innodb_page_cleaners,innodb_max_dirty_pages_pct_lwm,innodb_max_dirty_pages_pct等 查看官网配置 - 你可以控制bp如何保存当前的buffer pool状态,适当的配置可以避免mysql下次启动后长时间的预热,相关配置变量较多,包含
innodb_buffer_pool_dump_pct,innodb_buffer_pool_dump_at_shutdown等
- 使用内存空间大的主机,为mysql配置更大的buffer pool size。因为mysql大部分的操作都是在内存中执行,多数数据只会从磁盘中加载一次,后续都是读内存,所以更大的bp size可以存更多的数据在内存中,性能更高!变量是
1.3 Change Buffer
Change Buffer(下文简称CB)是一种由多个二级索引页和一颗B+树(存在于共享表空间,ibdata1文件)构成的内存空间,用于缓存针对不存在于buffer pool中的二级索引页的DML操作(INSERT, UPDATE, DELETE),稍后这些变更根据各种机制合并到buffer pool中。
下图是CB与buffer pool的交互图

Change Buffer内部实现
前面说了,CB是由一个B+树构成的,它负责对所有表的二级索引更改进行记录。树的非叶节点存放的是search key,其构造如下图
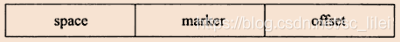
search key一共占用9个字节,其中space表示待插入记录所在表的表空间id,在InnoDB存储引擎中,每个表有一个唯一的space id,可以通过space id查询得知是哪张表。space占用4字节。marker占用1字节,它是用来兼容老版本的Insert Buffer。offset表示页所在的偏移量,占用4字节。
当一个二级索引记录要insert到页( space,offset)时,如果这个页不在缓冲池中,那么InnoDB引擎首先根据上述规则构造一个search key,接下来查询Change Buffer 这棵B+树,然后再将这条记录插入到Change Buffer B+树的叶子节点中。
对于插人到Change Buffer B+树叶子节点的记录,并不是直接将待插入的记录插入,而是需要根据如下的规则进行构造:

前几个字段和searchkey一样就不说了,metadata占4字节,记录了这条变更记录的元数据,比如包含了插入这棵树的顺序值用于replay恢复数据,其他的不做DB开发不需要掌握。后面的secondary index record 部分就是描述本次操作(DML)的内容了。
记住一点:CB保存的只是索引更改数据,不是源数据的更改;所以在update数据时,如果待修改的数据页不再buffer pool中,其必然去磁盘加载源数据页。数据修改完成后,再去更新索引(若字段建立了索引)。
- 为什么需要Change Buffer
实验SQL:update x=1 from t where id=1,这里我假设id是主键,x是普通(二级)索引字段
首先,假设没有CB的情况,我们得知道mysql的UPDATE操作的大致逻辑(中间省去写undo redo log以及加锁环节):阶段一:先更新聚簇索引页
- 因为id是主键,所以直接在buffer pool中的缓存的聚簇(主键)索引树查找对应的叶子节点聚簇索引页(若没有缓存索引树的非叶子节点就从磁盘加载,mysql8.0提供一张表查看目前内存中缓存在bp中的每个索引的索引页数量)
- 找到对应聚簇索引页后,通过二分法找到页里面对应行
- 修改行,同时计算出affected rows(只计算数据发生变化的行)
阶段二:再更新二级索引(字段x建立了索引)
- 先尝试通过内存中的二级索引树查找对应的叶子节点,即二级索引页
- 找到对应二级索引页后,通过二分法找到页里面对应行
- 若索引页未命中缓存,就得去磁盘中把对应索引页读入buffer pool中
- 在内存中更新索引,注意,B+树的节点值变化可能会需要整棵树进行左选右选以维持平衡
阶段三:最后刷盘
- 使用buffer pool自带的机制将聚簇索引脏页和二级索引脏页刷盘
这段逻辑看似没毛病,实则不是最优方案!为什么?
如果是大量随机写(写多读少)的场景,采用上面方案会有大量的磁盘随机I/O读取操作(第6步),以及索引树维护带来的开销,并发写的性能不高!
于是,CB就上场了,如果索引页在buffer pool找不到,干脆使用一个单独的空间(change buffer)来保存针对二级索引的修改(注意不是保存索引本身)。具体保存的数据类型如下:
- insert
- delete-marking
- physical delete(purge操作)
啥,没有update?其实也在上面,update SQL语句的实际操作是先insert再delete。为啥是delete-marking而不是原地修改?这个描述暂未找到相关资料解释!
CB中的索引更改缓存在预定的几个时机会同步到buffer pool中,后者再异步写到磁盘。哪些时机呢?
- 需要读取这部分索引的时候,比如select…where x=?的语句执行时
- db空闲时
- db正常启动、关闭时
- redo log写满时
当有许多行和许多二级索引要更新时,CB的合并可能会花费几个小时,这段时间会导致磁盘I/O增加,会影响依赖磁盘的查询请求;合并操作也会发送在事务提交,mysql的启动或关机的时候。
purge操作将会在mysql空闲或缓慢关机的时候执行,它将二级索引页按序写入磁盘,这比每次更新都刷盘的效率高出许多。
你会在mysql资料的很多地方看到purge这个描述,通常是指mysql启动单独的线程来做数据/日志刷盘、缓冲区truncate等操作,这个时候一般称这个线程叫做purge线程。
-
什么时候不会用到CB
更新主键索引,或唯一索引。因为都是唯一,所以不能先写缓存。 -
CB带来的收益
因为它可以减少磁盘读取和写入,所以CB对于 I/O 密集型工作负载最有价值;例如,具有大量 DML 操作(如批量插入)的应用程序受益于CB。但是如果你的二级索引数据较少,你应该减少甚至禁用CB,腾出更多的空间给buffer pool用。 -
CB的空间占用
在内存中,CB占用buffer pool空间的一部分;在磁盘中,CB存在system表空间(没错,CB的B+树也会落盘),后者同时也是mysql关闭时索引变更的物理缓存区,即ibdata1。 -
CB配置
- 参数
innodb_change_buffering控制缓存到CB的数据类型,其实是sql类型,默认是all, 可选none,inserts,deletes,changes,purges(purge是指物理删除的操作) - 参数
innodb_change_buffer_max_size控制CB的可用空间大小,类型是int,占用buffer pool空间的百分比,默认25,最大50
- 参数
-
监控CB状态
mysql> SHOW ENGINE INNODB STATUS\G
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 4425293, used cells 32, node heap has 1 buffer(s)
13577.57 hash searches/s, 202.47 non-hash searches/s
- 通过
information_schema.innodb_metrics表获取更详细的数据 - 通过
information_schema.innodb_buffer_page表统计可以看出CB对性能的影响程度,具体sql请参考官网
1.4 自适应Hash索引(Adaptive Hash Index)
简称AHI,具体来说是给经常被访问的索引页(热点页)建立hash索引,可以描述为索引的索引。
它加速了对热点页的查找过程,常规是通过B+tree查找,可能需要2-3次I/O,而通过hash索引可以直接找到随意的索引页,不再需要树查找。
它有几个特点如下:
- 限制场景使用,比如仅包含 = 和 IN 操作符的等值查询
- hash索引的key值是where条件中的索引字段,如果是组合索引字段,可以只包含部分字段。
- 在部分场景下,对自适应哈希索引的访问有时会导致严重的锁竞争,如高并发join查询
- MySQL自动调整,无法干预
5.7版本及以上中,AHI使用了分段锁来减少高并发场景下锁的竞争,提高性能。官文中描述为分区(partitioned),其实一个意思。它由参数innodb_adaptive_hash_index_parts控制,默认8,最高512。
查看相关配置show variables like '%hash_index%'

关闭set global innodb_adaptive_hash_index='off'
监控AHI使用情况show engine innodb status:
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 557, seg size 559, 304617 merges
merged operations:
insert 688133, delete mark 206010, delete 11078
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 276671, node heap has 59 buffer(s)
330.50 hash searches/s, 114.83 non-hash searches/s
通过搜索ADAPTIVE关键字可以找到该部分信息,最后2行描述hash索引信息,non-hash 表示非hash索引查询次数,若高于hash查询说明当前系统不使用AHI,应关闭AHI。
监控AHI的锁竞争情况,在show engine innodb status的输出中的SEMAPHORES部分:
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 2134292
OS WAIT ARRAY INFO: signal count 1847913
Mutex spin waits 3840490, rounds 50352831, OS waits 1188131
RW-shared spins 1279542, rounds 34353371, OS waits 845762
RW-excl spins 170132, rounds 3635212, OS waits 73050
Spin rounds per wait: 13.11 mutex, 26.85 RW-shared, 21.37 RW-excl
If there are numerous threads waiting on rw-latches created in btr0sea.c(如果有许多线程等待在btr0sea.c创建的rw-latches,不过似乎在输出中没看到),可能需要提高innodb_adaptive_hash_index_parts的值。
1.4 Log buffer
是一块用来作为redo log在内存缓冲区的内存区域,增加log buffer size可以提升事务并发性能,减少磁盘I/O(redo log会在log buffer不够用时刷盘)。另外,log buffer也会定期刷盘。
相关可调变量:
innodb_log_buffer_size,默认16MBinnodb_flush_log_at_trx_commit,控制如何将日志缓冲区的内容写入并刷到磁盘,具体细节涉及到redo log部分,暂不细讲。innodb_flush_log_at_timeout,控制日志刷新频率
另外,还有几个变量是调整redo log的物理文件大小
innodb_log_file_size控制单个redo log文件大小,默认48MB,最大512GB,文件名ib_logfile0和ib_logfile1,这两个文件是循环写入的;值越大,能存的redo log越多,就减少了redo log写入到数据页的I/O次数,同时mysql启动时的恢复时间越长,可参考的时间是1G的redo log文件需要5分钟的恢复时间。innodb_log_files_in_group控制redo log文件数量,默认2innodb_log_group_home_dir控制redo log的位置,默认data目录