目录
1、缓冲区管理
缓冲区是一个存储区域,它可以由专门的硬件寄存器组成,也可以由内存组成。
由寄存器组成的缓冲区较小,成本较高,一般仅用在对速度要求非常高的场合,如存储器管理中所用的联想存储器,设备控制器中用的数据缓冲区等。更多情况下,都是使用内存作为缓冲区。
(1)单缓冲区和双缓冲区
如果在生产者与消费者之间未设置任何缓冲,生产者与消费者之间在时间上会相互限制。例如,生产者已经完成了数据的生产,但消费者尚未准备好接收,生产者无法把所生产的数据交付给消费者,此时生产者必须暂停等待,直到消费者就绪。如果在生产者与消费者之间设置了一个缓冲区,则生产者无需等待消费者就绪,便可把数据输出到缓冲区。//例如消息队列
1.1 - 单缓冲区
当用户进程发出 I/O请求时,操作系统便在主存中为之分配一个缓冲区。

由于缓冲区是共享资源,生产者与消费者在使用缓冲区时必须互斥。如果消费者尚未取走缓冲区中的数据,即使生产者又生产出新的数据,也无法将它送入缓冲区,生产者等待。
1.2 - 双缓冲区
为了加快输入和输出速度,提高设备利用率,又引入了双缓冲区机制,也称为缓冲对换(Buffer Swapping)。在设备输入时,先将数据送入第一缓冲区,装满后便转向第二缓冲区。//表面上看,无非就是多了一份缓冲区容量
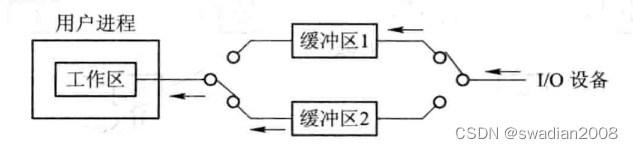
双缓冲区在两台机器之间的通信应用
如果两台机器之间的通信仅使用单缓冲区,那么它们之间在任一时刻都只能实现单方向的数据传输。例如,只允许把数据从 A 传送到 B 或者从 B 传送到 A,而绝不允许双方同时向对方发送数据。//半双工通信

为了实现双向数据传输,必须在两台机器中都设置两个缓冲区,一个用作发送缓冲区,另一个用作接收缓冲区。

(2)环形缓冲区/多缓冲区
环形缓冲区由多个缓冲区的组成,其每个缓冲区的大小相同。其中的缓冲区可分为三种类型:空缓冲区 R、已装满数据的缓冲区 G 以及正在使用的缓冲区 C,如下图所示。//多缓冲区

因此,环形缓冲区也包含多个指针。如,用于指示下一个有数据的缓冲区 G 的指针 Nextg,指示下次可用的空缓冲区 R 的指针 Nexti,以及用于指示正在使用的缓冲区 C 的指针 Current。
// 对空间的循环使用,比如循环队列等
(3)缓冲池(Buffer Pool)
当系统较大时,会有许多的循环缓冲区,这不仅要消耗大量的内存空间,而且其利用率不高。为了提高缓冲区的利用率,可以使用既可用于输入又可用于输出的公用缓冲池,在池中设置了多个可供进程共享的缓冲区。//统一管理缓冲区
缓冲池与缓冲区的区别在于:缓冲区仅仅是一组内存块的链表,而缓冲池则是包含了一个管理的数据结构及一组操作函数的管理机制,用于管理多个缓冲区。//好比管程的思想,统一管理一组信号量
3.1 - 缓冲池的组成
缓冲池管理着多个缓冲区,每个缓冲区由缓冲首部和缓冲体两部分组成。
- 缓冲首部:用于标识和管理缓冲区,一般包括缓冲区号、设备号、设备上的数据块号、同步信号量以及队列链接指针等。
- 缓冲体:用于存放数据。
为了管理上的方便,一般将缓冲池中具有相同类型的缓冲区链接成一个队列,于是可形成以下三个队列:
- 空白缓冲队列 emq。由空缓冲区所链成的队列。其队首指针 F(emg) 和队尾指针 L(emq) 分别指向该队列的首缓冲区和尾缓冲区。
- 输入队列 inq。由装满输入数据的缓冲区所链成的队列。其队首指针 F(ing) 和队尾指针 L(inq) 分别指向输入队列的队首和队尾缓冲区。
- 输出队列 outq。由装满输出数据的缓冲区所链成的队列。其队首指针 F(outq) 和队尾指针 L(outq) 分别指向该队列的首、尾缓冲区。
除了上述三个队列外,还应具有四种工作缓冲区:用于收容输入数据的工作缓冲区、用于提取输入数据的工作缓冲区、用于收容输出数据的工作缓冲区,以及用于提取输出数据的工作缓冲区。
3.2 - 缓冲池的工作方式
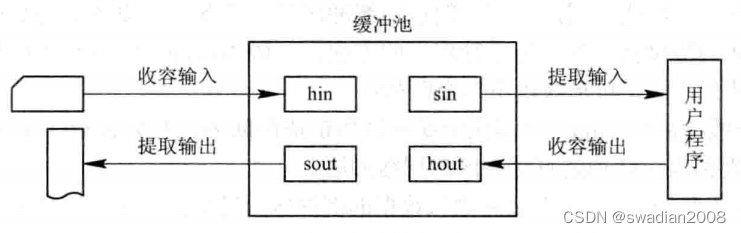
- 收容输入。从空缓冲队列 emq 的队首摘下一空缓冲区,作为收容输入工作缓冲区 hin。当缓冲区 hin 数据装满后,把它挂在输入队列 inq 队列上。//空队列->输入队列
- 提取输入。从输入队列 inq 的队首取得一缓冲区作为提取输入工作缓冲区 sin,从缓冲区 sin 中取完数据后,将它挂到空缓冲队列 emq 上。//输入队列->空队列
- 收容输出。从空缓冲队列 emq 的队首取得一空缓冲区,作为收容输出工作缓冲区 hout。当缓冲区 hout 装满输出数据后,将它挂在输出队列 outq 的末尾。//空队列->输出队列
- 提取输出。从输出队列 outq 的队首取得一装满输出数据的缓冲区,作为提取输出工作缓冲区 sout。缓冲区 sout 数据提取完后,将它挂在空缓冲队列末尾。//输出队列->空队列
// 缓冲池的工作,就是对三种队列的操作和转换过程。
2、磁盘存储器的性能和调度
磁盘 I/O 速度的高低和磁盘系统的可靠性,将直接影响到系统的性能。
可以通过多种途经来改善磁盘系统的性能。首先可通过选择好的磁盘调度算法,以减少磁盘的寻道时间;其次是提高磁盘 I/O 速度,以提高对文件的访问速度;第三采取冗余技术,提高磁盘系统的可靠性,建立高度可靠的文件系统。
(1)磁盘的数据组织和格式
磁盘设备可包括一个或多个物理盘片,每个磁盘片分一个或两个存储面(Surface),每个盘面上有若干个磁道(Track),磁道之间留有必要的间隙(Gap)。//物理盘片->存储面->磁道->扇区(数据块)

为使处理简单起见,在每条磁道上可存储相同数目的二进制位。这样,磁盘密度即每英寸中所存储的位数,显然是内层磁道的密度较外层磁道的密度高。
每条磁道又被从逻辑上划分成若干个扇区(Sectors),软盘大约为 8 至 32 个扇区,硬盘则可多达数百个。一个扇区称为一个盘块(或数据块),各扇区之间保留一定的间隙(Gap)。
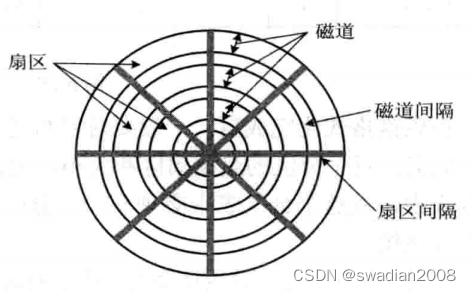
一个物理记录存储在一个扇区上,磁盘上能存储的物理记录块数目是由扇区数、磁道数以及磁盘面数所决定的。例如,一个 10GB 容量的磁盘,有 8 个双面可存储盘片,共 16 个存储面(盘面),每面有 16383 个磁道(也称柱面),63个扇区。// 10G/16 = 64M/存储面
(2)磁盘格式化和磁盘分区
为了在磁盘上存储数据,必须先将磁盘低级格式化。// 磁盘的容量划分
下边为一条磁道格式化的情况。其中每条磁道(Track)含有 30 个固定大小的扇区(Sectors),每个扇区容量为 600 个字节,其中 512 个字节存放数据,其余的用于存放控制信息。

每个扇区包括两个字段:
- 标符字段(ID Field):其中一个字节的 SYNCH 具有特定的位图像,作为该字段的定界符,利用磁道号(Track)、磁头号(Head #)及扇区号(Sectors #)三者来标识一个扇区;CRC 字段用于段校验。
- 数据字段(Data Field):存放 512 个字节的数据。
值得强调的是,在磁盘一个盘面的不同磁道(Track)、每个磁道的不同扇区(Sector),以及每个扇区的不同字段(Field)之间,为了简化和方便磁头的辨识,都设置了一个到若干个字节不同长度的间距(Gap,也称间隙)。
磁盘分区:在磁盘格式化完成后,一般要对磁盘进行分区。在逻辑上,每个分区就是一个独立的逻辑磁盘。每个分区的起始扇区和大小都记录在分区表中。// 磁盘分区,就是把物理磁盘分为多个逻辑磁盘
(3)磁盘调度算法
磁盘调度算法的目的:减少对文件的访问时间,使各进程对磁盘的平均访问时间最小。
由于在访问磁盘的时间中主要是寻道时间,因此,磁盘调度的目标是使磁盘的平均寻道时间最少。
3.1 - 先来先服务(FCFS)
最简单的磁盘调度算法。它根据进程请求访问磁盘的先后次序进行调度。
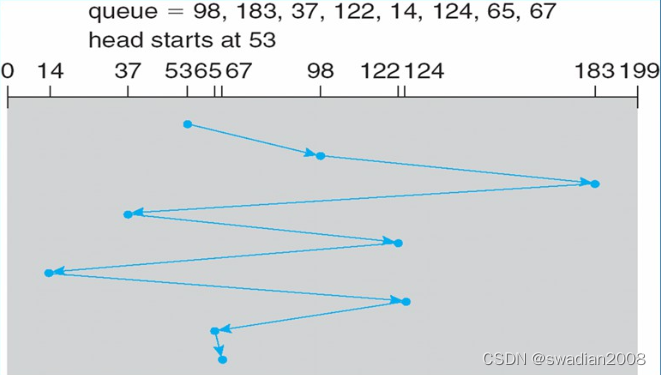
此算法的优点是公平、简单,且每个进程的请求都能依次地得到处理,不会出现某一进程的请求长期得不到满足的情况。
但此算法未对寻道进行优化,致使平均寻道时间可能较长。
3.2 - 最短寻道时间优先(SSTF)
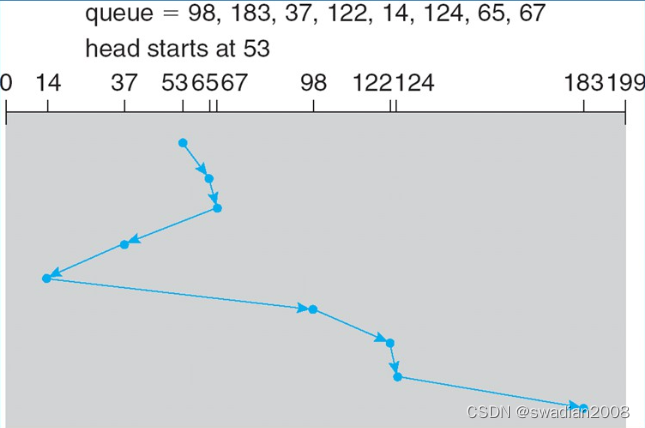
该算法选择要求访问的磁道与当前磁头所在的磁道距离最近的进程进程处理,以使每次的寻道时间最短,但这种算法并不能保证平均寻道时间最短。//可能出现饥饿现象
3.3 - 磁盘扫描(SCAN)算法
SSTF 算法的实质是基于优先级的调度算法,因此就可能导致优先级低的进程发生“饥饿”(Starvation)现象。
扫描(SCAN)算法不仅考虑到欲访问的磁道与当前磁道间的距离,更优先考虑的是磁头当前的移动方向。// 距离+移动方向

磁头自里向外移动,到达最外磁道后,又从外向里移动,对整个磁盘进行扫描,这种算法中磁头移动的规律颇似电梯的运行,因而又常称之为电梯调度算法。//问题在于,每次都会扫描到最外层,尽管此时已经没有必要
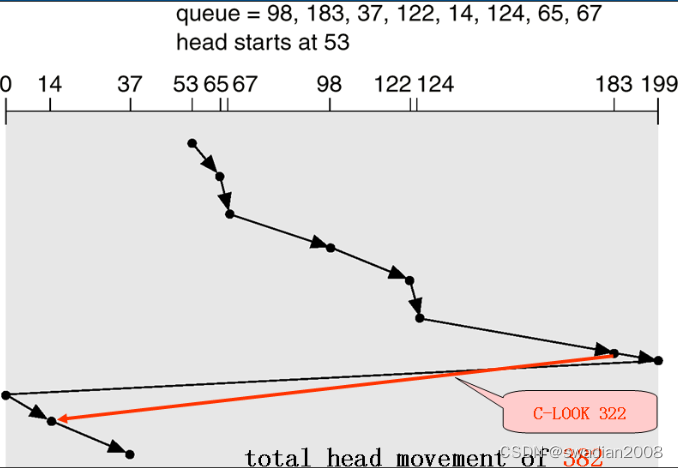
3.4 - 循环扫描(C-SCAN)算法
SCAN 算法既能获得较好的寻道性能,又能防止“饥饿”现象,但是当磁头刚从里向外移动而越过了某一磁道时,恰好又有一进程请求访问此磁道,这时,该进程必须等待,待磁头继续从里向外,然后再从外向里扫描完处于外面的所有要访问的磁道后,才处理该进程的请求,致使该进程的请求被大大地推迟。// 进程请求被推迟
为了减少这种延迟,C-SCAN 算法规定磁头单向移动,例如,只是自里向外移动,当磁头移到最外的磁道并访问后,磁头立即返回到最里的欲访问磁道,亦即将最小磁道号紧接着最大磁道号构成循环,进行循环扫描。//此时,磁头不再回到一个固定的外层起点
3.5 - NStep-SCAN 调度算法
在SSTF、SCAN 及 C-SCAN 几种调度算法中都可能出现磁臂停留在某处不动的情况。例如,有一个或几个进程对某一磁道有较高的访问频率,即反复请求对某一磁道的 I/O 操作,从而垄断了整个磁盘设备。我们把这一现象称为“磁臂粘着”(Armstickiness)。在高密度磁盘上容易出现此情况。
N 步 SCAN 算法将磁盘请求队列分成若干个长度为 N 的子队列,磁盘调度将按 FCFS 算法依次处理这些子队列。而每处理一个队列时按照 SCAN 算法,对一个队列处理完后,再处理其他队列。当正在处理某子队列时,如果又出现新的磁盘 I/O 请求,便将新请求进程放入其他队列,这样就可避免出现粘着现象。//先处理前一个队列中的进程请求,再处理下一个队列中的进程请求,每个队列固定容量
当 N 值取得很大时,会使 N 步扫描法的性能接近于 SCAN 算法的性能;当 N = 1 时,N 步 SCAN 算法便蜕化为 FCFS 算法。
3.6 - F-SCAN 调度算法
F-SCAN 算法实质上是 N 步 SCAN 算法的简化,即 F-SCAN 只将磁盘请求队列分成两个子队列。一个是由当前所有请求磁盘 I/O 的进程形成的队列,由磁盘调度按 SCAN 算法进行处理。另一个是在扫描期间,将新出现的所有请求磁盘 I/O 的进程放入等待处理的请求队列。这样,所有的新请求都将被推迟到下一次扫描时处理。//当前进程队列+扫描期间的进程队列