一、使用拼音分词器
1、拼音分词器
 2、docker下安装拼音分词器插件
2、docker下安装拼音分词器插件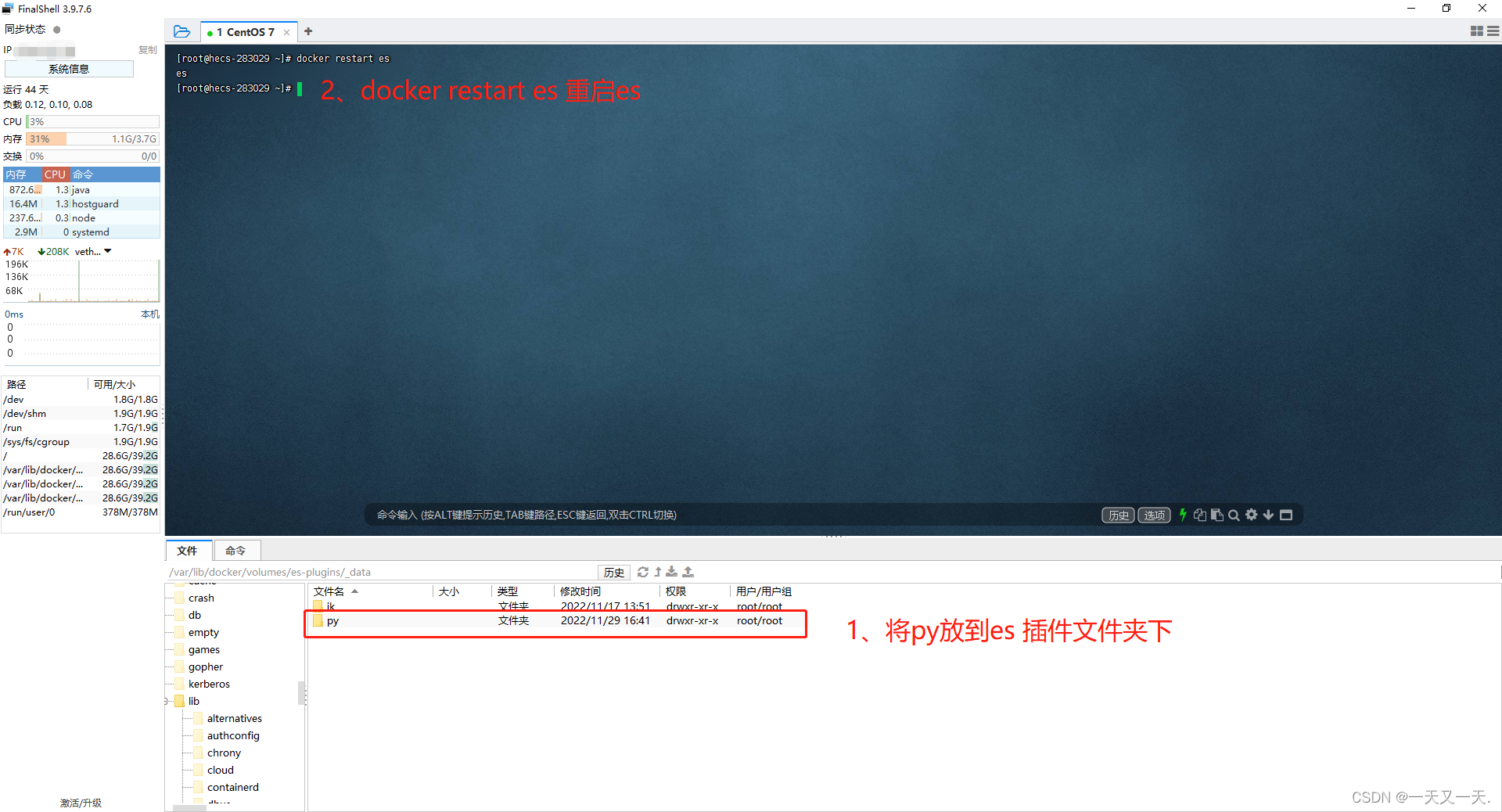
3、测试拼音分词器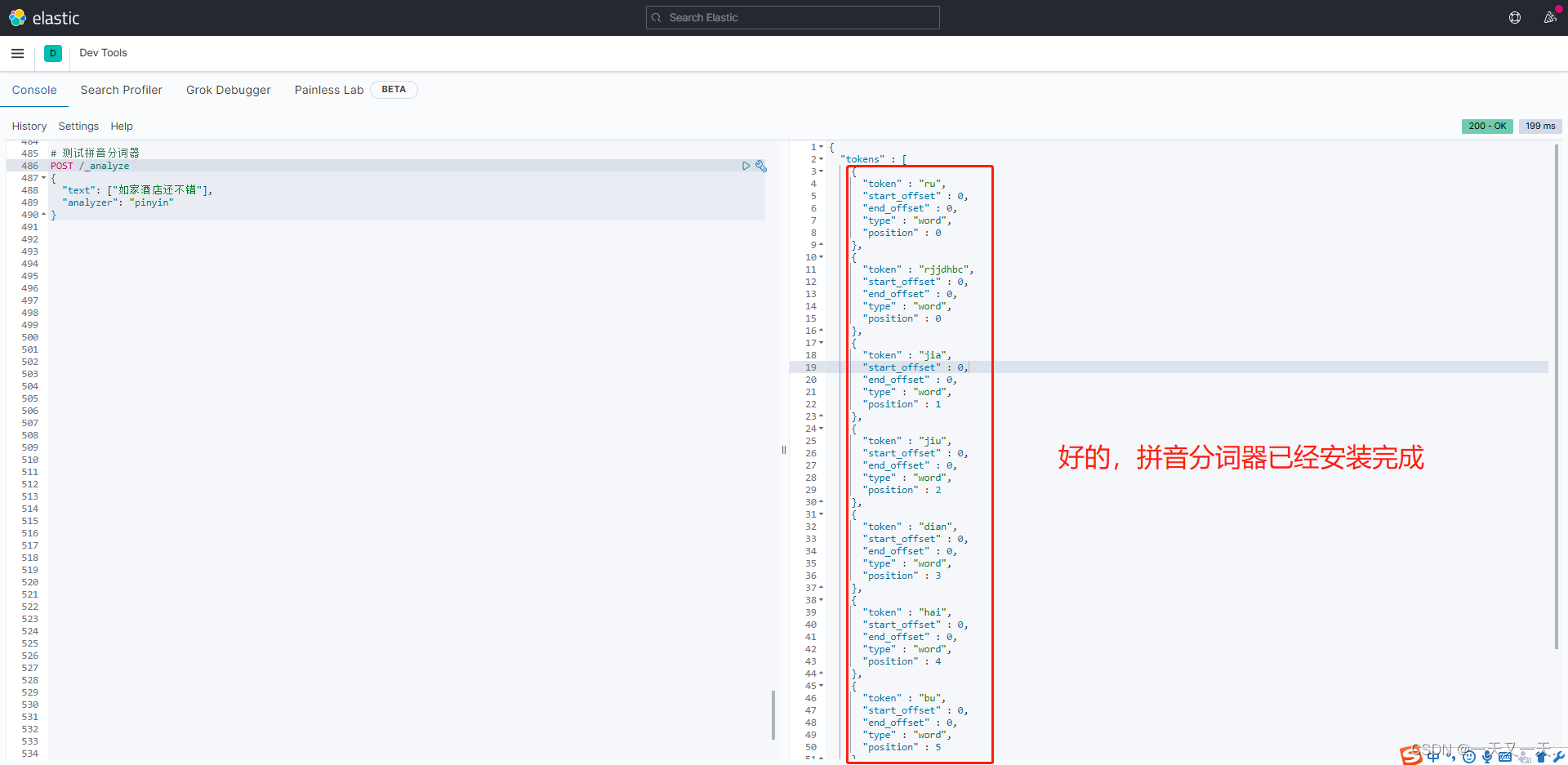
# 测试拼音分词器
POST /_analyze
{
"text": ["如家酒店还不错"],
"analyzer": "pinyin"
}
二、自定义分词器
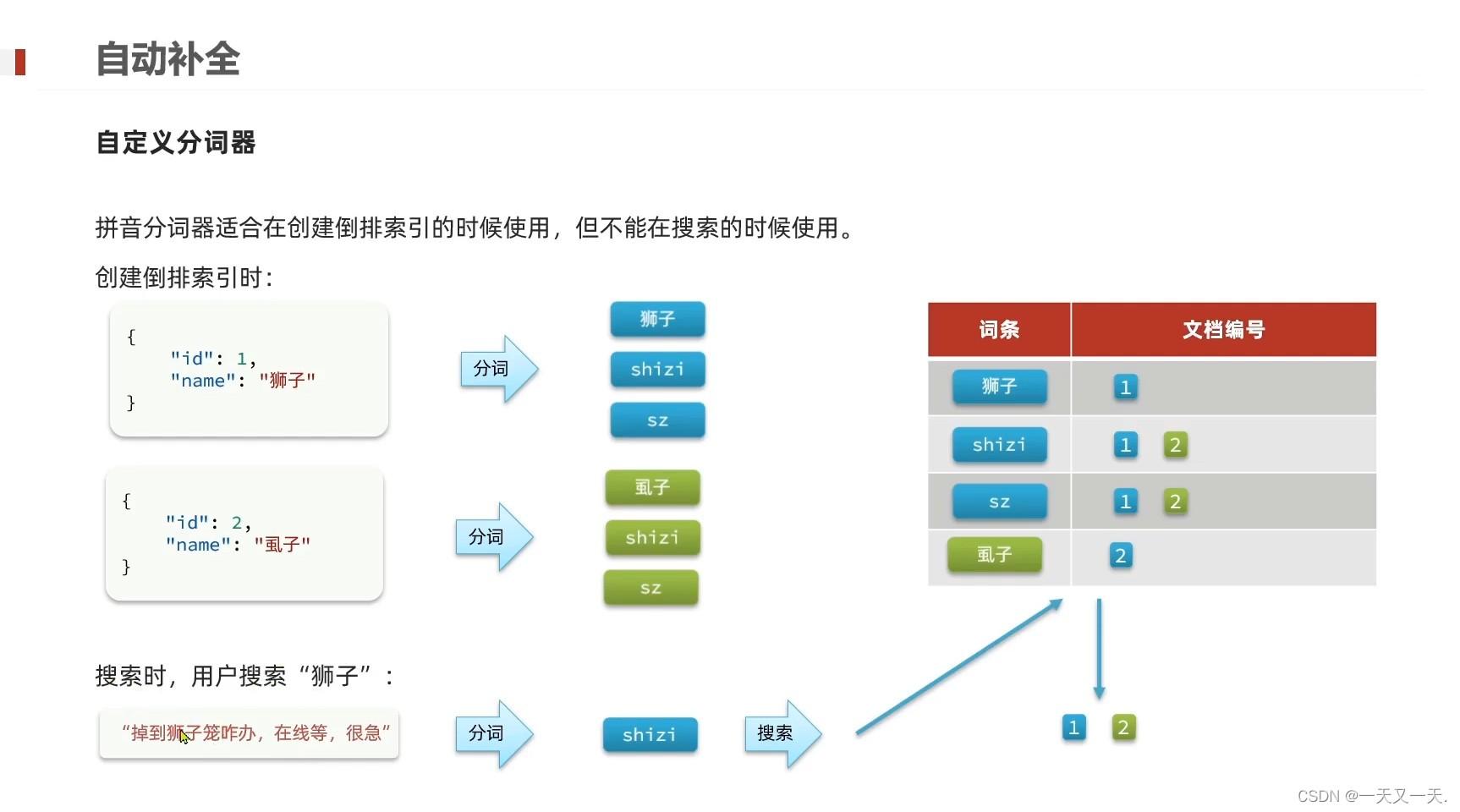
1、 如果只是单独使用拼音分词器,是没办法满足具体业务使用场景的,这时候就需要自定义分词器
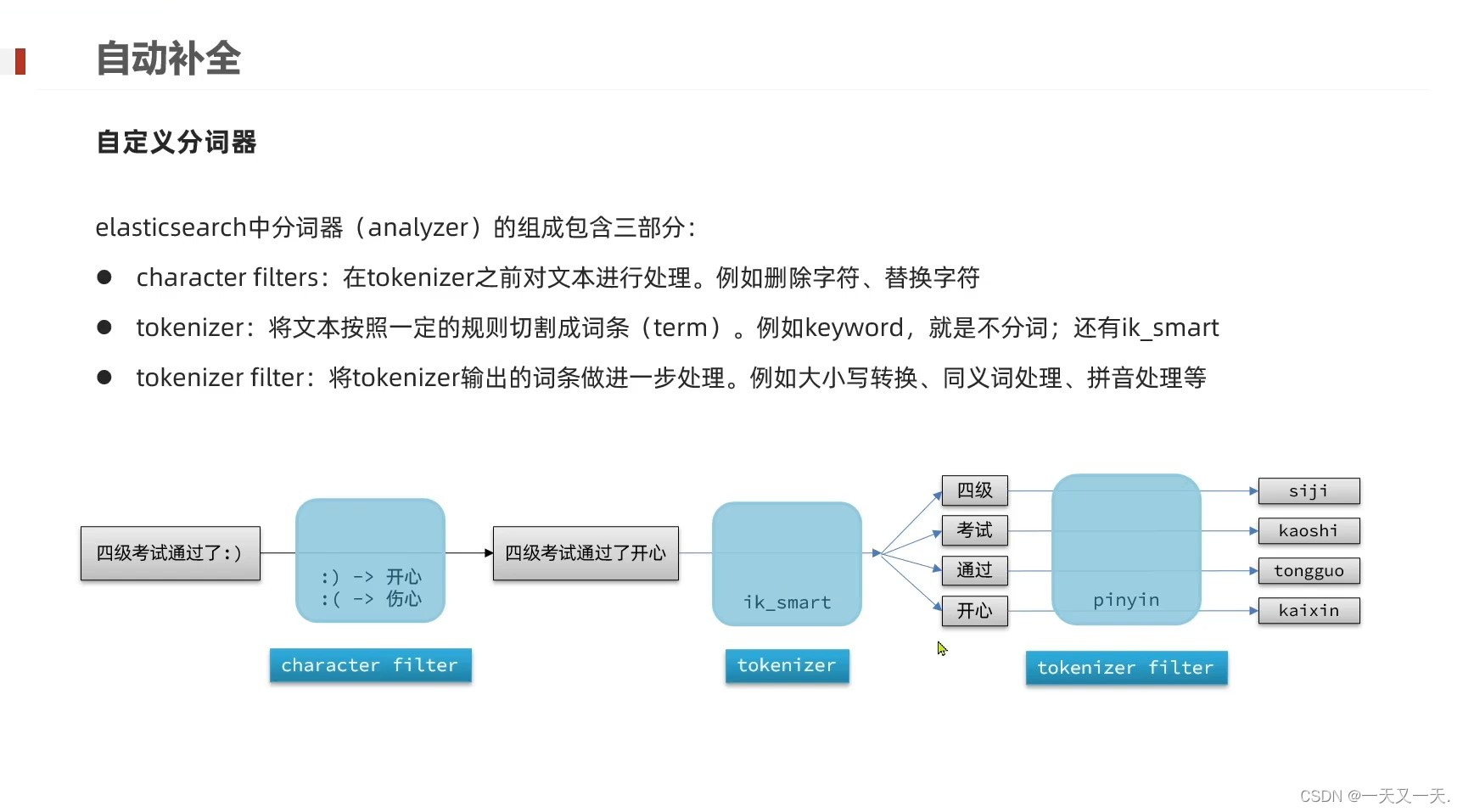
2、通过自定义分词器,将ik分词器与拼音分词器整合起来,来保证我们的搜索既满足汉字也满足拼音
# 自定义拼音分词器
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
}
}

// 酒店数据索引库
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"text_anlyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart"
}
}
}
}
三、总结分析

本章学习了如何安装拼音分词器和自定义分词器。
1、只是汉子搜索是无法满足业务需求的,所以引入了拼音分词器。
2、为了搜索时,同时满足汉字与拼音,所以需要自定义分词器。
3、为了避免搜索到同音词,搜索时不要使用拼音分词器。
拼音分词器插件![]() https://download.csdn.net/download/weixin_40968009/87253646
https://download.csdn.net/download/weixin_40968009/87253646
以上内容来自黑马程序员,课程学习节奏循序渐进。本人学习后觉得非常不错,有兴趣的小伙伴千万不要错过。