本文包含王道考研讲课中所涉及的数据结构中的所有代码,当PPT代码和书上代码有所区别时以咸鱼的PPT为主,个人认为PPT上的代码比王道书上的代码要便于理解,此外,本博客也许会补充一些额外的代码进来(不仅受限于王道考研),408中冷门考点频出,应该会囊括所有涉及到的代码,这也是我的DS的第二轮复习,希望与大家共勉之,由于博客体量的问题,原先打算此文也将收录诸如os中的吸烟者问题等的一系列伪代码,具体看到时候本文字数而定。如果一篇博客放不下的话会拆分成为两三篇文章发布。
(2023/05/15)编译器发出内容过多的警告,开始拆分博客内容,本博客仅记录数据结构前四章,准确来说只有三章的内容,后续内容见博客:
王道考研数据结构代码总结(第四章)
王道考研数据结构代码总结(第六章)
线性表
基本操作
InitList(&L) // 初始化表。构造一个空的线性表L,分配内存空间。
DestroyList(&L) // 销毁操作。销毁线性表,并释放线性表L所占用的内存空间。
ListInsert(&L,i,e) // 插入操作。在表L中的第i个位置上插入指定元素e。
ListDelete(&L,i,&e) // 删除操作。删除表L中第i个位置的元素,并用e返回删除元素的值。
LocateElem(L,e) // 按值查找操作。在表L中查找具有给定关键字值的元素。
GetElem(L,i) // 按位查找操作。获取表L中第i个位置的元素的值。
Length(L) // 求表长。返回线性表L的长度,即L中数据元素的个数。
PrintList(L) // 输出操作。按前后顺序输出线性表L的所有元素值。
Empty(L) // 判空操作。若L为空表,则返回true,否则返回false。
顺序表
顺序表的定义
f r e e ( ) free() free() 和 m a l l o c ( ) malloc() malloc()
# include <stdlib.h> // malloc, free
L.data = (ElemType *) malloc (sizeof(ElemType) * InitSize);
// malloc 函数返回一个指针,需要强制转型为你定义的数据元素类型指针
free(L.data);
静态分配定义顺序表:
#define MaxSize 10 // 定义最大长度
typedef struct{
ElemType data[MaxSize]; // 用静态的“数组”存放数据元素
int length; // 顺序表的当前长度
}SqList; // 顺序表的类型定义(静态分配方式)
静态分配初始化顺序表:
void InitList(SqList &L){
for (int i = 0; i < MaxSize; i ++ )
L.data[i] = 0;
L.length = 0;
}
动态分配定义顺序表:
#define InitSize 10 //顺序表的初始长度
typedef struct{
ElemType *data; //指示动态分配数组的指针
int MaxSize; //顺序表的最大容量
int length; //顺序表的当前长度
}SeqList; //顺序表的类型定义(动态分配方式)
动态分配初始化顺序表:
void InitList(SeqList &L){
L.data = (int *)malloc(InitSize * sizeof(int));
L.length = 0;
L.MaxSize = InitSize;
}
顺序表的插入
在顺序表 L L L 的第 i i i 个位置插入新元素 e e e
bool ListInsert (SqList &L, int i, ElemType e){
if (i < 1 || i > L.length + 1)
return false;
if (L.length >= MaxSize)
return false;
for (int j = L.length; j >= i; j -- )
L.data[j] = L.data[j - 1];
L.data[i - 1] = e;
L.length ++;
return true;
}
顺序表的删除
bool ListDelete(SqList &L, int i, int &e){
if(i < 1 || i > L.length) //判断i的范围是否有效
return false;
e = L.data[i - 1]; //将被删除的元素赋值给e
for(int j = i; j < L.length; j ++ ) //将第i个位置后的元素前移
L.data[j - 1] = L.data[j];
L.length --;
return true;
}
插入删除可执行代码:
#include <stdio.h>
#define MaxSize 10
typedef struct{
int data[MaxSize];
int length;
}SqList;
void InitList(SqList &L){
for (int i = 0; i < MaxSize; i ++ )
L.data[i] = 0;
L.length = 0;
}
bool ListInsert (SqList &L, int i, int e){
if (i < 1 || i > L.length + 1)
return false;
if (L.length >= MaxSize)
return false;
for (int j = L.length; j >= i; j -- )
L.data[j] = L.data[j - 1];
L.data[i - 1] = e;
L.length ++;
return true;
}
bool ListDelete(SqList &L, int i, int &e){
if(i < 1 || i > L.length)
return false;
e = L.data[i - 1];
for(int j = i; j < L.length; j ++ )
L.data[j - 1] = L.data[j];
L.length --;
return true;
}
int main()
{
SqList L;
InitList(L);
for (int i = 1; i <= 6; i ++ )
ListInsert(L, i, i);
for (int i = 0; i < L.length; i ++ )
printf("%d ", L.data[i]);
puts("");
int e = 1, pos = 0;
scanf("%d", &pos);
if (ListDelete(L, pos, e)) {
printf("e = %d\n", e);
for (int i = 0; i < L.length; i ++ )
printf("%d ", L.data[i]);
}
else printf("NOT FUND");
return 0;
}
静态分配顺序表的按位查找
ElemType GetElem(SqList L, int i){
return L.data[i - 1];
}
动态分配顺序表的按位查找
ElemType GetElem(SeqList L, int i){
return L.data[i - 1];
}
动态分配顺序表的按值查找
在顺序表 L L L 中查找第一个元素值等于 e e e 的元素,并返回其位序
int LocateElem(SeqList L, ElemType e){
for(int i = 0; i < L.length; i ++ )
if(L.data[i] == e)
return i+1; //数组下标为i的元素值等于e,返回其位序i+1
return 0; //退出循环,说明查找失败
}
链表
用代码定义一个单链表
链表的基本定义和一些表示规则:
typedef struct LNode{
// 定义单链表节点类型
ElemType data; // 每个结点存放一个数据源元素
struct LNode *next; // 指针指向下一个节点
}LNode, *LinkList;
LNode *p = (LNode *)malloc(sizeof(LNode)); // 增加一个新的节点
LNode *L; // 声明一个指向单链表第一个节点的指针
LinkList L; // 声明一个指向单链表第一个节点的指针
// 强调这是一个单链表:LinkList
// 强调这是一个节点: LNode *
个人对于创造结点or创造指针的理解:分配出来一个内存空间的就是创造节点,指针仅为定义指针变量,虽然指针也是分配了内存的,但这个内存是虚的,即用完后就会消失的,并不能满足存储下来数据的要求,所以在定义结点的时候必须调用malloc函数,在定义指针的时候无需malloc函数。
不带头节点的单链表
初始化一个空的单链表:
bool InitList(LinkList &L) {
L = NULL; // 空表,展示还没有任何结点
return true;
}
判断单链表是否为空:
bool Empty(LinkList L){
if (L == NULL) return true;
else return false;
}
初始化不带头节点的单链表可执行代码:
#include <stdio.h>
#include <stdlib.h>
#define ElemType int
typedef struct LNode{
ElemType data;
struct LNode *next;
}LNode, *LinkList;
bool InitList(LinkList &L) {
L = NULL;
return true;
}
bool Empty(LinkList L){
if (L == NULL) return true;
else return false;
}
int main()
{
LinkList L;
InitList(L);
if (Empty(L)) puts("YES");
else puts("NOT");
return 0;
}
带头节点的单链表
初始化一个空的单链表(带头节点):
bool InitList(LinkList &L) {
L = (LNode *)malloc(sizeof(LNode)); // 分配一个头节点
if (L == NULL) return false; // 内存不足,分配失败
L -> next = NULL; // 头节点之后暂时还没有节点
}
判断单链表是否为空(带头节点):
bool Empty(LinkList L){
if (L -> next == NULL) return true;
else return false;
}
初始化带头节点的单链表可执行代码:
#include <stdio.h>
#include <stdlib.h>
#define ElemType int
typedef struct LNode{
ElemType data;
struct LNode *next;
}LNode, *LinkList;
bool InitList(LinkList &L) {
L = (LNode *)malloc(sizeof(LNode));
if (L == NULL) return false;
L -> next = NULL;
}
bool Empty(LinkList L){
if (L -> next == NULL) return true;
else return false;
}
int main()
{
LinkList L;
InitList(L);
if (Empty(L)) puts("YES");
else puts("NOT");
return 0;
}
链表的插入
按位序插入(带头结点)
在第 i i i 个位置插入元素 e e e (带头结点)
bool ListInsert(LinkList &L, int i, ElemType e){
if (i < 1) return false; // i值不合法
LNode *p = L; // p记录当前扫描到的节点,初值为头节点
int j = 0; // p指向的是第几个节点
while (p != NULL && j < i - 1){
// 循环找到第i-1个节点
j ++;
p = p -> next;
}
if (p == NULL) return false; // i值不合法,超过了链表长
LNode *s = (LNode *)malloc(sizeof(LNode));
s -> data = e;
s -> next = p -> next;
p -> next = s;
return true;
}
按位序插入(不带头结点)
在第 i i i 个位置插入元素 e e e (不带头结点)
bool ListInsert(LinkList &L, int i, ElemType e){
if (i < 1) return false; // i值不合法
if (i == 1){
LNode *s = (LNode *)malloc(sizeof(LNode));
s -> data = e;
s -> next = L;
L = s;
return true;;
}
LNode *p = L; // p记录当前扫描到的节点,初值为头节点
// 注意这里和带头结点的不同,j是从1开始的
int j = 1; // p指向的是第几个节点
while (p != NULL && j < i - 1){
// 循环找到第i-1个节点
j ++;
p = p -> next;
}
if (p == NULL) return false; // i值不合法,超过了链表长
LNode *s = (LNode *)malloc(sizeof(LNode));
s -> data = e;
s -> next = p -> next;
p -> next = s;
return true;
}
往后的代码默认是带头节点的!
指定节点的后插
在 p p p 节点后插入元素 e e e
bool InsertNextNode (LNode *p, ElemType e){
if (p == NULL) return false;
LNode *s = (LNode *)malloc(sizeof(LNode));
/*
if (s == NULL) return false; // 分配内存失败
*/
s -> data = e;
s -> next = p -> next;
p -> next = s;
return true;
}
故可把上述的 按位序插入(带头节点) 封装为:
bool ListInsert(LinkList &L, int i, ElemType e){
if (i < 1) return false; // i值不合法
LNode *p = L; // p记录当前扫描到的节点,初值为头节点
int j = 0; // p指向的是第几个节点
while (p != NULL && j < i - 1){
// 循环找到第i-1个节点
j ++;
p = p -> next;
}
return InsertNextNode (p, e);
}
指定节点的前插
这里采取一个取巧的办法执行前插:插入到该节点后方然后交换两个节点的值
bool InsertPriorNode(LNode *p, ElemType e){
if (p == NULL) return false;
LNode *s = (LNode *)malloc(sizeof(LNode));
/*
if (s == NULL) return false;
*/
s -> next = p -> next;
p -> next = s;
s -> data = p -> data;
p -> data = e;
return true;
}
王道书版本(其实就是传入参数又差别导致代码有微小改动):
bool InsertPriorNode(LNode *p, LNode *s){
if (p == NULL || s == NULL) return false;
s -> next = p -> next;
p -> next = s;
ElemType tmp = p -> data;
p -> data = s -> data;
s -> data = tmp;
return true;
}
按位序删除(带头节点)
删除表 L L L 中第 i i i 个位置的元素,并用 e e e 返回删除元素的值:
bool ListDelete(LinkList &L, int i, ElemType &e){
if (i < 1) return false; // 不合法
LNode *p = L; // 当前扫描到了哪个节点
int j = 0; // 当前是第几个节点
while (p != NULL && j < i - 1){
// 找到第 i-1 个节点
j ++;
p = p -> next;
}
if (p == NULL) return false; // 不合法
if (p -> next == NULL) return false; // 不存在i号节点
LNode *q = p -> next;
e = q -> data;
p -> next = q -> next;
free(q);
return true;
}
关于 f r e e ( ) free() free() ,大抵是传入一个指针,就可以释放这个指针所指向的内存空间。
按位序删除(不带头节点)
删除表 L L L 中第 i i i 个位置的元素,并用 e e e 返回删除元素的值:
bool ListDelete(LinkList &L, int i, ElemType &e){
if (i < 1) return false;
else if (i == 1){
// 特殊判断删除头节点的情况
LNode *p = L;
if (p == NULL) return false;
L = p -> next;
e = p -> data;
free(p);
return true;
}
else{
LNode *p = L;
int j = 1;
while (p != NULL && j < i - 1){
j ++;
p = p -> next;
}
if (p == NULL) return false;
if (p -> next == NULL) return false;
LNode *q = p -> next;
e = q -> data;
p -> next = q -> next;
free(q);
return true;
}
}
指定节点的删除
删除结点 p p p,需要修改其前驱结点的 n e x t next next 指针
方法1:传入头指针,循环寻找 p p p 的前驱结点
方法2:偷天换日(类似于结点前插的实现)
方法2代码:
bool DeleteNode (LNode *p){
if (p == NULL) return false;
LNode *q = p -> next;
p -> data = q -> data;
p -> next = q -> next;
free(q);
return true;
}
不难看出,这个方法2实际上是借用了删除节点的后一个节点,所以当删除节点为最后一个节点的时候,本方法并不适用,只能从表头开始依次寻找 p p p 的前驱,时间复杂度 O ( n ) O(n) O(n)
单链表的查找
GetElem(L,i):按位查找操作。获取表 L L L 中第 i i i 个位置的元素的值。
LocateElem(L,e):按值查找操作。在表 L L L 中查找具有给定关键字值的元素。
按位查找
按位查找,返回第 i i i 个元素(带头节点)
LNode * GetElem(LinkList L, int i){
if (i < 0) return NULL;
LNode *p = L; // 指针p指向当前扫描到的节点
int j = 0; // 当前指针p指向的是第几个节点
while (p != NULL && j < i){
// 找到第i个节点
j ++;
p = p -> next;
}
return p;
}
所以上述 按位序插入(带头节点) 代码可封装为两部分:
- 找到第 i − 1 i-1 i−1 个元素
- 在该元素后面插入一个元素:
bool ListInsert(LinkList &L, int i, ElemType e){
if (i < 1) return false; // i值不合法
LNode *p = GetElem(L, i - 1);
return InsertNextNode (p, e);
}
按值查找
按值查找,找到数据域 = = e ==e ==e 的节点
LNode * LocateElem(LinkList L, ElemType e){
LNode *p = L -> next; // 头节点是没有值的
while (p != NULL && p -> data != e)
p = p -> next;
return p; // 返回的是一个节点指针,没找到就是NULL
}
如果 E l e m T y p e ElemType ElemType 是结构体类型,则不能简单的用 p -> data != e 去进行比较,但这并不是数据结构所关注的内容
求表的长度
int Length(LinkList L){
int len = 0;
LNode *p = L;
while (p -> next != NULL){
p = p -> next;
len ++;
}
return len;
}
单链表的建立
Step 1:初始化一个单链表
Step 2:每次娶一个数据元素,插入到表尾/表头
下面涉及代码均为带头节点代码
尾插法
由于是针对于表尾进行插入操作,如果仅知道头指针,那么每次在进行尾插操作前,都需要遍历一遍当前链表找到尾节点之后才可进行尾插操作,这样是很低效的,于是设置一个表尾指针:
LNode *r = L; // 初始时头指针与尾指针都指向头节点
void List_TailInsert(LinkList &L){
int x;
LNode *s, *r = L; // r为表尾指针
while (scanf("%d", &x) != EOF){
//输入结点的值
s = (LNode *)malloc(sizeof (LNode));
s -> data = x;
r -> next = s;
r = s; // 更新尾指针为新插入节点
}
r -> next = NULL; // 尾节点置空
}
尾插法可执行代码:
#include <stdio.h>
#include <stdlib.h>
#define ElemType int
typedef struct LNode{
ElemType data;
struct LNode *next;
}LNode, *LinkList;
bool InitList(LinkList &L){
L = (LNode *)malloc(sizeof(LNode)); // 分配一个头节点
if (L == NULL) return false; // 内存不足,分配失败
L -> next = NULL; // 头节点后无节点
return true;
}
void List_TailInsert(LinkList &L){
int x;
LNode *s, *r = L; // r为表尾指针
while (scanf("%d", &x) != EOF){
//输入结点的值, Ctrl+z 停止输入
s = (LNode *)malloc(sizeof (LNode));
s -> data = x;
r -> next = s;
r = s; // 更新尾指针为新插入节点
}
r -> next = NULL; // 尾节点置空
}
void print_list(LinkList &L){
puts("");
LNode *s = L -> next;
while (s != NULL){
printf("%d ", s -> data);
s = s -> next;
}
}
int main()
{
LinkList L;
InitList(L); // 初始化
List_TailInsert(L); // 尾插
print_list(L); // 打印
return 0;
}
头插法
直接在 L L L 后面插入元素即可,下述代码为核心函数:
注:该函数是为了和可执行代码配套,如果根据题干要求函数返回值可把函数改为 b o o l bool bool , L i n k L i s t LinkList LinkList 等类型, 上述中的尾插法代码同理
void List_HeadInsert(LinkList &L){
int x;
LNode *s;
while (scanf("%d", &x) != EOF){
//输入结点的值
s = (LNode *)malloc(sizeof (LNode));
s -> data = x;
s -> next = L -> next;
L -> next = s;
}
}
头插法可执行代码:
#include <stdio.h>
#include <stdlib.h>
#define ElemType int
typedef struct LNode{
ElemType data;
struct LNode *next;
}LNode, *LinkList;
bool InitList(LinkList &L){
L = (LNode *)malloc(sizeof(LNode)); // 分配一个头节点
if (L == NULL) return false; // 内存不足,分配失败
L -> next = NULL; // 头节点后无节点
return true;
}
void List_HeadInsert(LinkList &L){
int x;
LNode *s;
while (scanf("%d", &x) != EOF){
//输入结点的值, Ctrl+z 停止输入
s = (LNode *)malloc(sizeof (LNode));
s -> data = x;
s -> next = L -> next;
L -> next = s;
}
}
void print_list(LinkList &L){
puts("");
LNode *s = L -> next;
while (s != NULL){
printf("%d ", s -> data);
s = s -> next;
}
}
int main()
{
LinkList L;
InitList(L); // 初始化
List_HeadInsert(L); // 头插
print_list(L); // 打印
return 0;
}
尾插法的重要应用:链表的逆置
双链表
单链表:无法逆向检索,有时候不太方便
双链表:可进可退,存储密度更低一丢丢
双链表的定义
typedef struct DNode{
ElemType data;
struct LNode *prior, *next; // 前驱和后继指针
}DNode, *DLinklist;
双链表的初始化(带头结点)
初始化一个空的双链表:
bool InitDLinkList (DLinklist &L){
L = (DNode *)malloc(sizeof(DNode));
if (L == NULL) return false;
L -> prior = NULL; // 头节点的 prior 永远指向 NULL
L -> next = NULL; // 头节点之后暂时还没有节点
return true;
}
判断双链表是否为空(带头节点)
bool Empty(DLinklist L){
if (L -> next == NULL) return true;
else return false;
}
初始化带头节点的双链表可执行代码:
#include <stdio.h>
#include <stdlib.h>
#define ElemType int
typedef struct DNode{
ElemType data;
struct LNode *prior, *next;
}DNode, *DLinklist;
bool InitDLinkList (DLinklist &L){
L = (DNode *)malloc(sizeof(DNode));
if (L == NULL) return false;
L -> prior = NULL;
L -> next = NULL;
return true;
}
bool Empty(DLinklist L){
if (L -> next == NULL) return true;
else return false;
}
int main()
{
DLinklist L;
InitDLinkList(L);
if (Empty(L)) puts("YES");
else puts("NOT");
return 0;
}
双链表的插入
在 p p p 节点之后插入 s s s 节点
bool InsertNextDNode (DNode *p, DNode *s){
if (p == NULL || s == NULL) return false;
s -> next = p -> next;
if (p -> next != NULL) // 如果 p 之后有后继节点
p -> next -> prior = s;
s -> prior = p;
p -> next = s;
return true;
}
双链表的删除
删除一个双链表,其实就是依次删除各个节点,最后删除头节点,即写出删除节点的函数,遍历一次链表同时调用删除节点函数,最后删除头节点即可实现双链表的删除
删除 p p p 节点的后继节点:
bool DeleteNextDNode(DNode *p){
if (p == NULL) return false;
DNode *q = p -> next; // 后续要一直使用 p->next, 故简化起见记为 q
if (q == NULL) return false; // p 没有后继
p -> next = q -> next;
if (q -> next != NULL) // q 节点不是最后一个节点
q -> next -> prior = p;
free(q); // 释放节点空间
return true;
}
删除双链表(带头节点):
void DstoryList(DLinklist &L){
while (L -> next != NULL) // 只要存在首元节点就删掉,于是结束循环时仅剩下了头节点
DeleteNextDNode(L); // 删除 L 的后继节点即首元节点
free(L); // 释放头节点
L = NULL; // 头指针指向NULL
}
双链表的遍历
后向遍历:
while (p != NULL){
//对结点 p 做相应处理,如打印
p = p -> next;
}
前向遍历:
while (p != NULL){
//对结点 p 做相应处理
p = p -> prior;
}
前向遍历(跳过头结点):
while (p -> prior != NULL){
//对结点 p 做相应处理
p = p -> prior;
}
循环链表
循环单链表
初始化一个循环单链表:
bool InitList(LinkList &L){
L = (LNode *)malloc(sizeof(LNode)); // 分配一个头节点
if (L == NULL) return false; // 内存不足
L -> next = L; // 头节点的 next 指向头节点
return true;
}
判断循环单链表是否为空:
bool Empty(LinkList L){
if (L -> next == L) return true;
else return false;
}
判断节点 p p p 是否为循环单链表的表尾节点:
bool isTail(LinkList L, LNode *p){
if (p -> next == L) return true;
else return false;
}
有时可以让 L L L 指向表尾元素(插入、删除时可能需要修改 L L L)
循环双链表
初始化一个循环双链表:
bool InitDLinklist(DLinklist &L){
L = (DNode *)malloc(sizeof(DNode)); // 分配一个头节点
if (L == NULL) return false; // 内存不足,分配失败
L -> prior = L;
L -> next = L;
return true;
}
判断循环双链表是否为空:
bool Empty(DLinklist L){
if (L -> next == L) return true;
else return false;
}
判断节点 p p p 是否为循环双链表的表尾节点:
bool isTail(DLinklist L, DNode *p){
if (p -> next == L) return true;
else return false;
}
静态链表
静态链表的初始化
#define MaxSize 10 // 静态链表的最大长度
typedef struct{
ElemType data; // 存储数据元素
int next; // 下一个元素的数组下标
}SLinkList[MaxSize];
void testSLinkList(){
SLinkList a; // 定义了一个长度为 MaxSize 的数组
}
静态链表基本操作简述
初始化静态链表:
1.把 a[0] 的 next 设为 -1
2.把其他结点的 next 设为一个特殊值用来表示结点空闲,如 -2
插入位序为 i i i 的结点:
1.找到一个空的结点,存入数据元素
2.从头结点出发找到位序为 i-1 的结点
3.修改新结点的 next
4.修改 i-1 号结点的 next
删除某个结点:
1.从头结点出发找到前驱结点
2.修改前驱结点的游标
3.被删除结点 next 设为 -2
静态链表:用数组的方式实现的链表
优点:增、删 操作不需要大量移动元素
缺点:不能随机存取,只能从头结点开始依次往后查找;容量固定不可变
适用场景:①不支持指针的低级语言;②数据元素数量固定不变的场景(如操作系统的文件分配表FAT)
顺序表 VS 链表
表长难以预估、经常要增加/删除元素 ——链表
表长可预估、查询(搜索)操作较多 ——顺序表
从逻辑结构来看:
都属于线性表,都是线性结构
从存储结构来看:
顺序表:
优点:支持随机存取、存储密度高
缺点:大片连续空间分配不方便,改变容量不方便
链表:
优点:离散的小空间分配方便,改变容量方便
缺点:不可随机存取,存储密度低
从基本操作来看:
创建操作:
顺序表:需要预分配大片连续空间。若分配空间过小,则之后不方便拓展容量;若分配空间过大,则浪费内存资源
链表:只需分配一个头结点(也可以不要头结点,只声明一个头指针),之后方便拓展
销毁操作:
顺序表:修改 Length = 0;静态分配:静态数组(系统自动回收空间);动态分配:动态数组( m a l l o c 、 f r e e malloc、free malloc、free)(需要手动 f r e e free free)
链表:依次删除各个结点( f r e e free free)
增 o r or or 删:
顺序表:插入 o r or or 删除元素要将后续元素都后移 o r or or 前移;时间复杂度O(n),时间开销主要来自移动元素;若数据元素很大,则移动的时间代价很高
链表:插入 o r or or 删除元素只需修改指针即可;时间复杂度 O(n),时间开销主要来自查找目标元素;查找元素的时间代价更低
查找操作:
顺序表:按位查找:O(1);按值查找:O(n)若表内元素有序,可在O(logn) 时间内找到
链表:按位查找:O(n);按值查找:O(n)
栈,队列,数组
栈
栈是只允许在一端进行插入或删除的线性表
特点:后进先出 L a s t Last Last I n In In F i r s t First First O u t ( L I F O ) Out(LIFO) Out(LIFO)
基本操作
lnitStack(&S) // 初始化栈。构造一个空栈 S,分配内存空间
DestroyStack(&S) // 销毁栈。销毁并释放栈S所占用的内存空间
Push(&S, x) // 进栈,若栈S未满,则将x加入使之成为新栈顶
Pop(&S, &x) // 出栈,若栈S非空,则弹出栈顶元素,并用x返回。
GetTop(S, &x) // 读栈顶元素。若栈 S非空,则用x返回栈顶元素
StackEmpty(S) //判断一个栈S是否为空。若S为空,则返回true,否则返回false。
n n n 个不同元素进栈,出栈元素的不同排列个数为: 1 n + 1 C 2 n n \frac{1}{n+1}C^{n}_{2n} n+11C2nn
顺序栈
顺序栈的定义
#define MaxSize 10 // 定义栈中元素的最大个数
typedef struct{
ElemType data[MaxSize]; // 静态数组存放栈中元素
int top; // 栈顶指针
}SqStack;
void testStack(){
SqStack S; // 声明一个顺序栈(分配空间)
}
初始化操作
// 初始化栈
void InitStack(SqStack &S){
S.top = -1; // 初始化栈顶指针, top 指向的是已放元素的位置
}
// 判断栈空
bool StackEmpty(SqStack S){
if (S.top == -1) return true;
else return false;
}
进栈操作
这里先做一个区分:
1、A -> a 表示 A 是指向结构体的指针
2、A.a 表示 A 是结构体
// 新元素入栈
bool Push(SqStack &S, ElemType x){
if (S.top == MaxSize - 1) return false;
S.data[++ S.top] = x;
/*
S.top = S.top + 1;
S.data[S.top] = x;
*/
return true;
}
出栈操作
//元素出栈
bool Pop(SqStack &S, ElemType &x){
if (S.top == -1) return false;
x = S.data[S.top --]
/*
x = S.data[S.top];
S.top = S.top - 1;
*/
return true;
}
读栈顶元素
// 读栈顶元素
bool GetTop(SqStack S, ElemType &x){
if (S.top == -1) return false;
x = S.data[S.top];
return true;
}
易错
注意题目定义栈的时候,对于栈顶指针设置为几,还有一种常见的设置为设其为 0 0 0,此时栈顶指针代表着即将插入元素的位置,对代码有相关更改:
// 初始化栈
void InitStack(SqStack &S){
S.top = 0; // 初始化栈顶指针
}
// 判断栈空
bool StackEmpty(SqStack S){
if (S.top == 0) return true;
else return false;
}
// 入栈操作
S.data[S.top ++] = x;
// 出栈操作
x = S.data[-- S.top];
共享栈
即两个栈共享同一片空间
#define MaxSize 10 // 定义栈中元素的最大个数
typedef struct{
ElemType data[MaxSize]; // 静态数组存放栈中元素
int top0; // 0号栈顶指针
int top1; // 1号栈顶指针
}ShStack;
// 初始化栈
void InitStack(ShStack &S){
S.top0 = -1; // 初始化栈顶指针
S.top1 = MaxSize; // 初始化栈顶指针
}
// 栈满的条件
top0 + 1 = top1;
链栈
链栈的定义
typedef struct Linknode{
ElemType data; // 数据域
struct Linknode *next; // 指针域
} *LiStack; // 栈类型定义
链栈的基本操作
链栈的插入操作和单链表的头插操作类似;
链栈的删除操作和单链表在头节点后的删除类似
这里直接给出可执行代码,具体函数不做说明,和单链表无异
链栈的基本操作可执行代码:
注:下述代码第一个输入的是要出栈几次,然后才是输入要入栈的元素
#include <stdio.h>
#include <stdlib.h>
typedef struct Linknode{
int data;
struct Linknode *next;
}Linknode, *LiStack;
void InitLiStack(LiStack &S){
S = (Linknode *)malloc(sizeof(Linknode));
S -> next = NULL;
}
bool IsEmpty(LiStack S){
if (S -> next == NULL) return true;
else return false;
}
void PushLiStack(LiStack &S, int x){
Linknode *q = (Linknode *)malloc(sizeof(Linknode));
q -> data = x;
q -> next = S -> next;
S -> next = q;
}
bool PopLiStack(LiStack &S, int &x){
if (S -> next == NULL) return false;
Linknode *q = S -> next;
x = q -> data;
S -> next = q -> next;
free(q);
return true;
}
int main()
{
LiStack S; // 定义一个链栈
InitLiStack(S); // 初始化链栈(带头节点)
// 判空操作
if (IsEmpty(S)) puts("YES");
else puts("NOT");
int cnt;
scanf("%d", &cnt); // 输入要出栈的次数
// 输入元素执行入栈操作
int x;
while (scanf("%d", &x) != EOF) PushLiStack(S, x);
//遍历链栈,查看是否真的为链栈里输入了元素
Linknode *p = S -> next;
while (p != NULL){
printf("%d ", p -> data);
p = p -> next;
}
puts("");
int num = 0;
for (int i = 1; i <= cnt; i ++ ){
PopLiStack(S, num);
printf("%d : %d\n", i, num);
}
// 遍历删除元素后的链栈,查看是否真的删除
p = S -> next;
while (p != NULL){
printf("%d ", p -> data);
p = p -> next;
}
return 0;
}
队列
队列是只允许在一端进行插入,在另一端进行删除的线性表
特点:先进先出 F i r s t First First I n In In F i r s t First First O u t ( F I F O ) Out(FIFO) Out(FIFO)
基本操作
lnitQueue(&Q) // 初始化队列,构造一个空队列Q
DestroyQueue(&Q) // 销毁队列。销毁并释放队列Q所占用的内存空间
EnQueue(&Q, x) // 入队,若队列Q未满,将x加入,使之成为新的队尾
DeQueue(&Q, &x) // 出队,若队列Q非空,删除队头元素,并用x返回。
GetHead(Q, &x) // 读队头元素,若队列Q非空,则将队头元素赋值给x
QueueEmpty(Q) // 判队列空,若队列Q为空返回true,否则返回false。
队列的顺序存储
定义
#define MaxSize 10 // 定义队列中元素的最大个数
typedef struct{
ElemType data[MaxSize]; // 用静态数组存放队列元素
int front, rear; // 队头指针和队尾指针
}SqQueue;
void testQueue(){
SqQueue Q; // 声明一个队列(顺序存储)
}
初始化操作
void InitQueue(SqQueue &Q){
// 初始时,队头、队尾指针指向0
Q.rear = Q.front = 0;
}
// 判断队列是否为空
bool QueueEmpty(SqQueue Q){
if (Q.rear == Q.front) return true;
else return false;
}
入队操作
队满的标志 不是 Q.rear == MaxSize
这里需要注意因为我们已经定义了 Q.front = Q.rear 代表了队空,巧合的是其实队满的条件也是如此(因为 rear 指向的是下一个元素应该存入的地方),所以我们为了区分队满和队空,这里需要浪费一个空间,即我们设定 (Q.rear + 1) % MaxSIze = Q.front 代表队满
// 入队
bool EnQueue(SqQueue &Q, ElemType x){
if ((Q.rear + 1) % MaxSIze == Q.front) return false;
Q.data[Q.rear] = x; // 新元素入队尾
Q.rear = (Q.rear + 1) % MaxSize;
return true;
}
出队操作
// 出队(删除一个队头元素,并用 x 返回)
bool DeQueue(SqQueue &Q, ElemType &x){
if (Q.rear == Q.front) return false;
x = Q.data[Q.front];
Q.fornt = (Q.front + 1) % MaxSize;
return true;
}
读队头元素
// 获取队头元素的值,用 x 返回
bool GetHead(SqQueue Q, ElemType &x){
if (Q.rear == Q.front) return false;
x = Q.data[Q.front];
return true;
}
其他判别队列已满 or 空的方法
- 改变对队列定义:
#define MaxSize 10
typedef struct{
ElemType data[MaxSize];
int front, rear;
int size; // 队列目前的长度
}SqQueue;
// 初始化
Q.rear = Q.front = 0;
Q.size = 0;
Q.size ++; // 入队成功
Q.size --; // 出队成功
// 判断队空
Q.size == 0;
// 判断队满
Q.size == MaxSize;
- 再次改变对队列定义:
#define MaxSize 10
typedef struct{
ElemType data[MaxSize];
int front, rear;
int tag; // 最近进行的是插入/删除
}SqQueue;
// 只有删除操作,才可能导致队空
// 每次删除操作成功时,都令 tag = 0;
// 只有插入操作,才可能导致队满
// 每次插入操作成功时,都令 tag = 1;
// 初始化
Q.rear = Q.front = 0;
Q.tag = 0;
// 判断队空
Q.rear == Q.front && Q.tag == 0;
// 判断队满
Q.rear == Q.front && Q.tag == 1;
当然,Q.front 和 Q.rear 一开始也不一定必须初始化为 0 0 0,还可以是其他,具体题目具体分析
队列的链式存储
定义
typedef struct LinkNode{
// 链式队列节点
ElemType data;
struct LinkNode *next;
}LinkNode;
typedef struct LinkQueue{
// 链式队列
LinkNode *front, *rear; // 队列的队头和队尾指针
}LinkQueue; // 注意这里是LinkQueue,不是 *LinkQueue,和之前的定义做区分
说下自己的理解:
我们在之前定义链表、链栈(实际上就是单链表)的时候,定义链表和定义链表节点是同时定义的:
typedef struct LNode{
ElemType data;
struct LNode *next;
}LNode, *LinkList;
并没有区分它们的区别,其实是可以做一定的简化操作的。
比如我们在定义链表的时候分开定义:
定义节点:
typedef struct LNode{
ElemType data;
struct LNode *next;
}LNode;
我们知道,我们在定义链表的时候,其实只需要声明一个指针就好了,完全没必要 data 这个变量
所以我们可以把链表定义为:
typedef struct LinkList{
LNode *head;
}LinkList;
即我们定义了一个LinkList结构体,其内部元素就是一个head指针
如我们之前代码中写诸如:
s -> data = x;
s -> next = L -> next;
L -> next = s;
我们都需要更改为:
s -> data = x;
s -> next = L.head -> next;
L.head -> next = s;
说直白点就是要把所有的 L 改为 L.head
这是因为之前定义中 L 就是头指针(虽然也有data,但我们不使用data),现在则是 L 的内部的 head 才是我们的头指针
为什么我们不在链表/链栈中讲述这种定义方式?
是因为没有必要,链表的定义和链表节点的定义虽然本质上有区别,但完全可以忽视这微小的区别,虽然 头指针L中的 data 没有什么用,但浪费的那点空间可以忽略;至于链栈,因为其本质就是一个单链表,虽然栈相较于链表而言有一个特殊的栈顶指针,但是栈顶指针完全可以类似的去用链表的头指针L 进行类似的等价表示
为什么这里需要?
因为我们定义队列其实就是定义一个 front 指针的一个 rear 指针, 但是队列节点其实就是链表节点,即定义队列和定义队列节点区别是很大的(队列节点是不需要 front, rear 指针的),所以我们需要分开定义。
初始化操作
// 初始化队列(带头节点)
void InitQueue(LinkQueue &Q){
// 初始时 front, rear 都指向头节点
Q.front = Q.rear = (LinkNode *)malloc(sizeof(LinkNode));
Q.front -> next = NULL;
}
// 判断队列是否为空(带头节点)
bool IsEmpty(LinkQueue Q){
if (Q.front == Q.rear) return true;
else return false;
}
// 初始化队列(不带头节点)
void InitQueue(LinkQueue &Q){
// 初始时 front 和 rear 都指向 NULL
Q.front = NULL;
Q.rear = NULL;
}
// 判断队列是否为空(不带头节点)
bool IsEmpty(LinkQueue Q){
if (Q.front == NULL) return true;
else return false;
}
入队操作
// 新元素入队(带头节点)
void EnQueue(LinkQueue &Q, ElemType x){
LinkNode *s = (LinkNode *)malloc(sizeof(LinkNode));
s -> data = x;
s -> next = NULL;
Q.rear -> next = s; // 队尾入队
Q.rear = s; // 新入队节点为表尾
}
// 新元素入队(不带头节点)
void EnQueue(LinkQueue &Q, ElemType x){
LinkNode *s = (LinkNode *)malloc(sizeof(LinkNode));
s -> data = x;
s -> next = NULL;
if (IsEmpty(Q)){
// Q.front == NULL
Q.front = s;
Q.rear = s;
}
else{
Q.rear -> next = s;
Q.rear = s;
}
}
出队操作
// 队头元素出队(带头节点)
bool DeQueue(LinkQueue &Q, ElemType &x){
if (IsEmpty(Q)) return false; // Q.front == Q.rear
LinkNode *p = Q.front -> next; // 队头节点
x = p -> data;
Q.front -> next = p -> next;
if (Q.rear == p){
// 要删除的节点是链队的最后一个节点,即链队仅有一个节点
Q.rear = Q.front;
}
free(p);
return true;
}
// 队头元素出队(不带头节点)
bool DeQueue(LinkQueue &Q, ElemType &x){
if (IsEmpty(Q)) return false; // Q.front == NULL
LinkNode *p = Q.front; // 队头节点
x = p -> data;
Q.front = p -> next;
if (Q.rear == p){
// 要删除的节点是链队的最后一个节点,即链队仅有一个节点
Q.front = NULL;
Q.rear = NULL;
}
free(p);
return true;
}
链队的基本操作可执行代码(带头节点):
#include <stdio.h>
#include <stdlib.h>
#define ElemType int
typedef struct LinkNode{
ElemType data;
struct LinkNode *next;
}LinkNode;
typedef struct LinkQueue{
LinkNode *front, *rear;
}LinkQueue;
void InitQueue(LinkQueue &Q){
Q.front = Q.rear = (LinkNode *)malloc(sizeof(LinkNode));
Q.front -> next = NULL;
}
bool IsEmpty(LinkQueue Q){
if (Q.front == Q.rear) return true;
else return false;
}
void EnQueue(LinkQueue &Q, ElemType x){
LinkNode *s = (LinkNode *)malloc(sizeof(LinkNode));
s -> data = x;
s -> next = NULL;
Q.rear -> next = s;
Q.rear = s;
}
bool DeQueue(LinkQueue &Q, ElemType &x){
if (IsEmpty(Q)) return false;
LinkNode *p = Q.front -> next;
x = p -> data;
Q.front -> next = p -> next;
if (Q.rear == p){
Q.rear = Q.front;
}
free(p);
return true;
}
int main()
{
LinkQueue Q;
InitQueue(Q);
if (IsEmpty) puts("YES");
else puts("NOT");
int num_in = 0, x = 0;
scanf("%d", &num_in);
for (int i = 0; i < num_in; i ++ ){
scanf("%d", &x);
EnQueue(Q, x);
}
LinkNode *p = Q.front -> next;
for (int i = 1; i <= num_in; i ++ ){
printf("%d ", p -> data);
p = p -> next;
}
puts("");
int num_out = 0;
scanf("%d", &num_out);
for (int i = 1; i <= num_out; i ++ ){
DeQueue(Q, x);
printf("%d : %d\n", i, x);
}
p = Q.front -> next;
while (p != NULL){
printf("%d ", p -> data);
p = p -> next;
}
return 0;
}
链队的基本操作可执行代码(不带头节点):
#include <stdio.h>
#include <stdlib.h>
#define ElemType int
typedef struct LinkNode{
ElemType data;
struct LinkNode *next;
}LinkNode;
typedef struct LinkQueue{
LinkNode *front, *rear;
}LinkQueue;
void InitQueue(LinkQueue &Q){
Q.front = NULL;
Q.rear = NULL;
}
bool IsEmpty(LinkQueue Q){
if (Q.front == NULL) return true;
else return false;
}
void EnQueue(LinkQueue &Q, ElemType x){
LinkNode *s = (LinkNode *)malloc(sizeof(LinkNode));
s -> data = x;
s -> next = NULL;
if (IsEmpty(Q)){
Q.front = s;
Q.rear = s;
}
else{
Q.rear -> next = s;
Q.rear = s;
}
}
bool DeQueue(LinkQueue &Q, ElemType &x){
if (IsEmpty(Q)) return false;
LinkNode *p = Q.front;
x = p -> data;
Q.front = p -> next;
if (Q.rear == p){
Q.front = NULL;
Q.rear = NULL;
}
free(p);
return true;
}
int main()
{
LinkQueue Q;
InitQueue(Q);
if (IsEmpty) puts("YES");
else puts("NOT");
int num_in = 0, x = 0;
scanf("%d", &num_in);
for (int i = 0; i < num_in; i ++ ){
scanf("%d", &x);
EnQueue(Q, x);
}
LinkNode *p = Q.front;
for (int i = 1; i <= num_in; i ++ ){
printf("%d ", p -> data);
p = p -> next;
}
puts("");
int num_out = 0;
scanf("%d", &num_out);
for (int i = 1; i <= num_out; i ++ ){
DeQueue(Q, x);
printf("%d : %d\n", i, x);
}
p = Q.front;
while (p != NULL){
printf("%d ", p -> data);
p = p -> next;
}
return 0;
}
栈的应用
括号匹配
括号匹配问题的特点
- 最后出现的左括号最先匹配 ( L I F O ) (LIFO) (LIFO)
- 每出现一个右括号,就要消耗一个左括号 (出栈)
如果我们遇到左括号就让它入栈,那么完美的匹配:栈最终为空(即所有的括号都能两两配对)
可能出现的异常情况:
- 当前扫描到的右括号与栈顶元素的左括号不匹配
- 扫描到了右括号但此时栈为空
- 处理完所有的括号后,栈非空
算法实现:
bool bracketCheck(char str[], int length) {
SqStack S;
InitStack(S);
for (int i = 0; i < length; i ++ ){
if (str[i] == '(' || str[i] == '[' || str[i] == '{')
Push(S, str[i]);
else{
char c;
if (StackEmpty(S)) return false;
Pop(S, c);
if (c == '(' && str[i] != ')') return false;
else if (c == '[' && str[i] != ']') return false;
else if (c == '{' && str[i] != '}') return false;
}
}
if (!StackEmpty(S)) return false;
return true;
}
括号匹配可执行代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MaxSize 10
#define ElemType char
typedef struct{
ElemType data[MaxSize];
int top;
}SqStack;
void InitStack(SqStack &S){
S.top = -1;
}
bool StackEmpty(SqStack S){
if (S.top == -1) return true;
else return false;
}
bool Push(SqStack &S, ElemType x){
if (S.top == MaxSize - 1) return false;
S.data[++ S.top] = x;
return true;
}
bool Pop(SqStack &S, ElemType &x){
if (S.top == -1) return false;
x = S.data[S.top --];
return true;
}
bool bracketCheck(char str[], int length) {
SqStack S;
InitStack(S);
for (int i = 0; i < length; i ++ ){
if (str[i] == '(' || str[i] == '[' || str[i] == '{')
Push(S, str[i]);
else{
char c;
if (StackEmpty(S)) return false;
Pop(S, c);
if (c == '(' && str[i] != ')') return false;
else if (c == '[' && str[i] != ']') return false;
else if (c == '{' && str[i] != '}') return false;
}
}
if (!StackEmpty(S)) return false;
return true;
}
int main()
{
char str[20];
scanf("%s", str);
if (bracketCheck(str, strlen(str))) puts("YES");
else puts("NOT");
return 0;
}
表达式求值
逆波兰表达式 = = = 后缀表达式
波兰表达式 = = = 前缀表达式
我们在输入了一串中缀表达式给了计算机后,计算机先后做两件事:
- 中缀表达式转后缀表达式
- 后缀表达式求值
中缀表达式转后缀表达式
手算
①确定中缀表达式中各个运算符的运算顺序
②选择下一个运算符,按照 [左操作数 右操作数 运算符] 的方式组合成一个新的操作数
③如果还有运算符没被处理,就继续②
“左优先” 原则:只要左边的运算符能先计算,就优先算左边的
注:
- 运算顺序不唯一,因此对应的后缀表达式也不唯一
- 使用 “左优先” 原则可以保证运算结果顺序唯一
机算
初始化一个栈,用于保存暂时还不能确定运算顺序的运算符。
从左到右处理各个元素,直到末尾。可能遇到三种情况:
①遇到操作数。直接加入后缀表达式。
②遇到界限符。遇到 “ ( ( (” 直接入栈:遇到 “ ) ) )” 则依次弹出内运算符并加入后缀表达式,直到弹出 “ ( ( (” 为止。注意: “ ( ( (” 不加入后缀表达式。
③遇到运算符。依次弹出栈中优先级高于或等于当前运算符的所有运算符,并加入后缀表达式,若碰到 “ ( ( (” 或栈空则停止。之后再把当前运算符入栈。
按上述方法处理完所有字符后,将栈中剩余运算符依次弹出,并加入后缀表达式。
后缀表达式的计算
手算
从左往右扫描,每遇到一个运算符,就让运算符前面最近的两个操作数执行对应运算,合体为一个操作数
机算
用栈实现后缀表达式的计算:
①从左往右扫描下一个元素,直到处理完所有元素
②若扫描到操作数则压入栈,并回到①;否则执行③
③若扫描到运算符,则弹出两个栈顶元素,执行相应运算,运算结果压回栈顶,回到①
注:
- 先出栈的是 “右操作数”
- 若表达式合法,则最后栈中只会留下一个元素就是最终结果
表达式求值(组合)
用栈实现中缀表达式的计算:
①初始化两个栈,操作数栈(用来存放运算的结果)和运算符栈(用来存放还不能被确定运算顺序的运算符)
②若扫描到操作数,压入操作数栈
③若扫描到运算符或界限符,则按照“中缀转后缀”相同的逻辑压入运算符栈(期间也会弹出运算符,每当弹出一个运算符时,就需要再弹出两个操作数栈的栈顶元素并执行相应运算,运算结果再压回操作数栈)
关于代码,这里提供如下 ( C P P ) (CPP) (CPP) 代码,不是懒,,,是因为两个栈的话不同的定义的话,关于它们的操作都得分别重写(因为一个 d a t a data data 是 i n t int int 类型,一个 d a t a data data 是 c h a r char char 类型,太麻烦了,考研不太可能考,虽然不难,但是写起来很麻烦。
表达式求值可执行代码 (CPP):
#include <iostream>
#include <cstring>
#include <algorithm>
#include <unordered_map>
#include <stack>
using namespace std;
stack<char> op;
stack<int> num;
void eval()
{
auto b = num.top(); num.pop();
auto a = num.top(); num.pop();
auto c = op.top(); op.pop();
int x;
if (c == '+') x = a + b;
else if (c == '-') x = a - b;
else if (c == '*') x = a * b;
else x = a / b;
num.push(x);
}
int main()
{
string s;
cin >> s;
unordered_map<char, int> pr{
{
'+', 1}, {
'-', 1}, {
'*', 2}, {
'/', 2}};
for (int i = 0; i < s.size(); i ++ )
{
if (isdigit(s[i]))
{
int j = i, x = 0;
while (j < s.size() && isdigit(s[j]))
x = x * 10 + s[j ++ ] - '0';
num.push(x);
i = j - 1;
}
else if (s[i] == '(') op.push(s[i]);
else if (s[i] == ')')
{
while (op.top() != '(') eval();
op.pop();
}
else
{
while (op.size() && op.top() != '(' && pr[op.top()] >= pr[s[i]])
eval();
op.push(s[i]);
}
}
while (op.size()) eval();
cout << num.top() << endl;
return 0;
}
中缀表达式转前缀表达式
这里仅说明手算:
①确定中缀表达式中各个运算符的运算顺序
②选择下一个运算符,按照 [运算符 左操作数 右操作数] 的方式组合成一个新的操作数
③如果还有运算符没被处理,就继续②
“右优先”原则:只要右边的运算符能先计算,就优先算右边的
前缀表达式的计算
这里仅说明机算:
①从右往左扫描下一个元素,直到处理完所有元素
②若扫描到操作数则压入栈,并回到①;否则执行③
③若扫描到运算符,则弹出两个栈顶元素,执行相应运算,运算结果压回栈顶,回到①
注:
- 先出栈的是 “左操作数”
- 若表达式合法,则最后栈中只会留下一个元素就是最终结果
递归
函数调用的特点:最后被调用的函数最先执行结束 ( L I F O ) (LIFO) (LIFO)
函数调用时,需要用一个栈存储:
①调用返回地址
②实参
③局部变量
适合用“递归”算法解决:可以把原始问题转换为属性相同,但规模较小的问题
太多层递归可能会导致栈溢出,递归调用过程中可能会有很多重复的计算;
可以自定义栈将递归算法改造成为非递归算法
队列的应用
- 树的层次遍历
- 图的广度优先遍历
- 多个进程争抢着使用有限的系统资源时, F C F S ( FCFS( FCFS( F i r s t First First C o m e Come Come F i r s t First First S e r v i c e Service Service先来先服务) 是一种常用策略。 E g Eg Eg:打印数据缓冲区
矩阵的压缩存储
数组的存储结构
一维数组
起始地址: L O C LOC LOC
各数组元素大小相同,且物理上连续存放。
数组元素 a [ i ] a[i] a[i] 的存放地址 = = = L O C LOC LOC + + + i i i ∗ * ∗ s i z e o f ( E l e m T y p e ) sizeof(ElemType) sizeof(ElemType)
注:除非题目特别说明,否则数组下标默认从 0 0 0 开始
二维数组
起始地址: L O C LOC LOC
M M M 行 N N N 列的二维数组 b [ M ] [ N ] b[M][N] b[M][N] 中,若按 行优先 存储,则
b [ i ] [ j ] b[i][j] b[i][j] 的存储地址 = = = L O C LOC LOC + + + ( i (i (i ∗ * ∗ N N N + + + j j j ) ) ) ∗ * ∗ s i z e o f ( E l e m T y p e ) sizeof(ElemType) sizeof(ElemType)
i i i ∗ * ∗ N N N + + + j j j 其实就是从第一个元素到目标元素需要 “跳几个格子”,或者可以更粗暴的理解为从第一个元素到目标元素前一个元素这一共有多少个元素。
因为默认是从 b [ 0 ] [ 0 ] b[0][0] b[0][0] 开始,即 b [ 0 ] [ 0 ] b[0][0] b[0][0] 的存储坐标为 L O C LOC LOC,故 b [ i ] [ j ] b[i][j] b[i][j] 其实是在第 i + 1 i+1 i+1 行,第 j + 1 j+1 j+1 列,故从第一个元素开始算起,前 i i i 行每行 N N N 个元素,即前 i i i 行共 i ∗ N i*N i∗N 个元素,那么到目标元素的前一个元素,还需要 j j j 个元素,故为 ( i (i (i ∗ * ∗ N N N + + + j j j ) ) )
M M M 行 N N N 列的二维数组 b [ M ] [ N ] b[M][N] b[M][N] 中,若按 列优先 存储,则
b [ i ] [ j ] b[i][j] b[i][j] 的存储地址 = = = L O C LOC LOC + + + ( j (j (j ∗ * ∗ M M M + + + i ) i) i) ∗ * ∗ s i z e o f ( E l e m T y p e ) sizeof(ElemType) sizeof(ElemType)
注意:描述矩阵元素时,行、列号通常从 1 开始;而描述数组时通常下标从 0 开始(具体看题目给的条件,注意审题! )
特殊矩阵
对称矩阵
只存储主对角线 + + + 下三角区(或主对角线 + + + 上三角区);
求对称矩阵 a i , j a_{i,j} ai,j 存放在一维数组中的实际下标 [ k ] [k] [k]:具体算法要结合矩阵是从 [ 0 ] [ 0 ] [0][0] [0][0] 开始还是 [ 1 ] [ 1 ] [1][1] [1][1] 开始,数组是从 [ 0 ] [0] [0] 开始还是 [ 1 ] [1] [1] 开始,行优先还是列优先,从 [ 0 ] [0] [0] 开始的算法同上,从 [ 1 ] [1] [1] 开始也不过是相同的算法最后结果 + 1 +1 +1(理解为数组元素整体往后移 1 1 1 格)
求一维数组中 [ k ] [k] [k] 下标中的元素在对称矩阵 a i , j a_{i,j} ai,j 的下标:假设一维数组是从 [ 0 ] [0] [0] 开始的,那么就是第 k + 1 k+1 k+1 个元素,行优先存储,那么有 i ( i − 1 ) 2 < k + 1 ≤ i ( i + 1 ) 2 \frac{i(i-1)}{2}<k+1≤\frac{i(i+1)}{2} 2i(i−1)<k+1≤2i(i+1),我们在处理不等式的时候(包括之后树那边的不等式)都是处理 带等于这边 的,即解 k + 1 ≤ i ( i + 1 ) 2 k+1≤\frac{i(i+1)}{2} k+1≤2i(i+1) ➡ ➡ ➡ 2 ( k + 1 ) ≤ i ( i + 1 ) 2(k+1)≤i(i+1) 2(k+1)≤i(i+1),带个 i i i 的值进去试验一下是否满足,找到一个刚好满足不等式的 i i i 值即可,即找 i i i 的最小值。
三角矩阵
存法同上,并在最后一个位置存储常量 c c c
三对角矩阵
a i , j a_{i,j} ai,j 是第 i i i 行 j − i + 2 j-i+2 j−i+2 个元素
它的两个题型算法其实也和上述一致,这里把第二种再证一遍
求一维数组中 [ k ] [k] [k] 下标中的元素在三对角矩阵 a i , j a_{i,j} ai,j 的下标:假设一维数组是从 [ 0 ] [0] [0] 开始的,那么就是第 k + 1 k+1 k+1 个元素,行优先存储,那么有 3 ( i − 1 ) − 1 < k + 1 ≤ 3 i − 1 3(i-1)-1 < k+1≤3i-1 3(i−1)−1<k+1≤3i−1,同样,我们处理 带等于这边,即解 k + 1 ≤ 3 i − 1 k+1≤3i-1 k+1≤3i−1 ➡ ➡ ➡ i ≥ k + 2 3 i ≥ \frac{k+2}{3} i≥3k+2 ➡ ➡ ➡ i = ⌈ k + 2 3 ⌉ i=⌈\frac{k+2}{3}⌉ i=⌈3k+2⌉,为什么是向上取整?考场可以举个例子:比如我们算出来 i ≥ 2.7 i≥2.7 i≥2.7,那么 i i i 的实际取值其实只能是 3 3 3,故为向上取整。
当然,还有一种思考逻辑,也就是对于前 k k k 个元素,它只能在第 i − 1 i-1 i−1 行的最后一个元素及以后,绝对要小于第 i i i 行最后一个元素的位置,即有 3 ( i − 1 ) − 1 ≤ k < 3 i − 1 3(i-1)-1 ≤ k<3i-1 3(i−1)−1≤k<3i−1,同样,我们处理 带等于这边,即解 3 ( i − 1 ) − 1 ≤ k 3(i-1)-1 ≤ k 3(i−1)−1≤k ➡ ➡ ➡ i < = k + 4 3 i <= \frac{k+4}{3} i<=3k+4 ➡ ➡ ➡ i = ⌊ k + 4 3 ⌋ i = ⌊\frac{k+4}{3}⌋ i=⌊3k+4⌋,为什么是向下取整?考场可以举个例子:比如我们算出来 i ≤ 2.7 i≤2.7 i≤2.7,那么 i i i 的实际取值其实只能是 2 2 2,故为向下取整。
稀疏矩阵
稀疏矩阵:非零元素远远少于矩阵元素的个数
压缩存储策略:
- 顺序存储一一三元组<行,列,值>
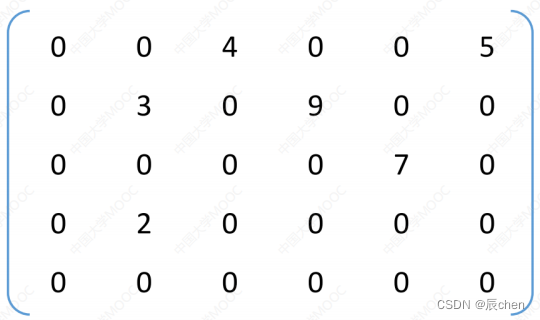
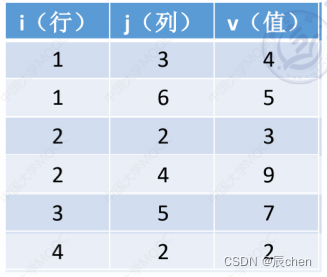
(注:此处行、列标从1开始)
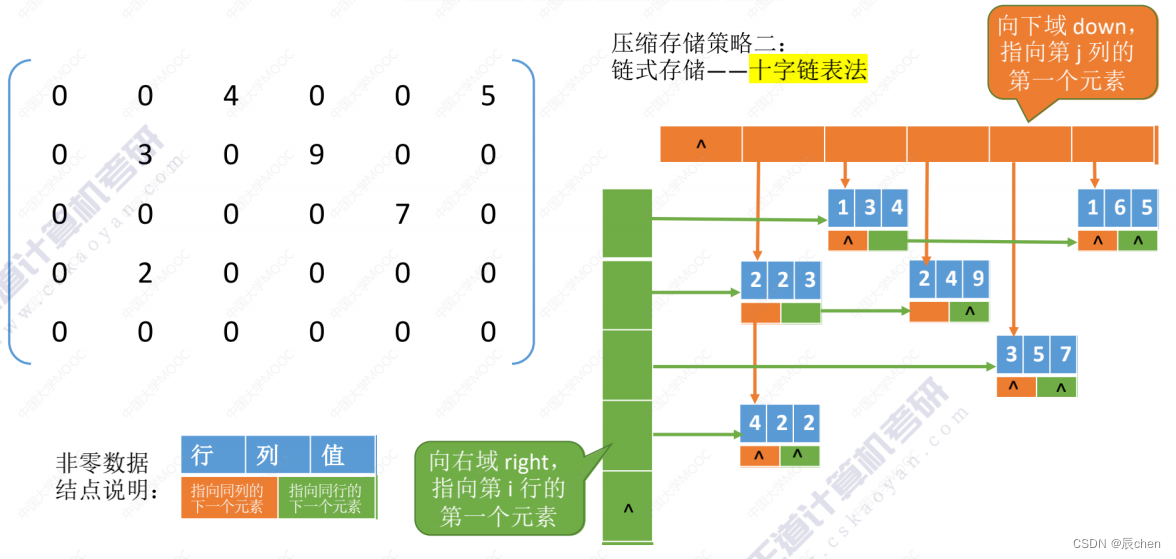
- 链式存储一一十字链表法
串
串是一种特殊的 线性表 ,数据元素之间呈线性关系
串的数据对象限定为字符集(如中文字符、英文字符、数字字符、标点字符等)
串的基本操作,如增删改查等通常以 子串 为操作对象
基本操作
StrAssign(&T, chars) // 赋值操作。把串T赋值为chars。
StrCopy(&T, S) // 复制操作。由串S复制得到串T。
StrEmpty(S) // 判空操作。若S为空串,则返回TRUE,否则返回FALSE。
StrLength(S) // 求串长。返回串S的元素个数。
ClearString(&S) // 清空操作。将S清为空串。
DestroyString(&S) // 销毁串。将串S销毁(回收存储空间)
Concat(&T, S1, S2) // 串联接。用T返回由S1和S2联接而成的新串
SubString(&Sub, S, pos, len) // 求子串。用Sub返回串S的第pos个字符起长度为len的子串。
Index(S, T) // 定位操作。若主串S中存在与串T值相同的子串,则返回它在主串S中第一次出现的位置;否则函数值为0。
StrCompare(S, T) // 比较操作。若S>T,则返回值>0;若S=T,则返回值=0;若S<T,则返回值<0.
存储结构
串的顺序存储
#define MAXLEN 255 // 预定义最大串长为255
// 静态数组实现(定长顺序存储)
typedef struct{
char ch[MAXLEN]; // 每个分量存储一个字符
int length; // 串的实际长度
}SString;
// 动态数组实现(堆分配存储)
typedef struct{
char *ch; // 按串长分配存储区,ch指向串的基地址
int length; // 串的长度
}HString;
HString S;
S.ch = (char *)malloc(MAXLEN * sizeof (char));
S.length = 0;
/*
方案一:如上
方案二:ch[0] 充当 length, 优点:字符的位序和数组下标相同
方案三:没有length变量,以字符 '\0' 表示结尾
方案四(教材):ch[0] 不用,长度仍用 length 表示
*/
串的链式存储
typedef struct StringNode{
char ch; // 每个节点存1个字符
struct StringNode *next;
}StringNode, *String;
typedef struct StringNode{
char ch[4]; // 每个节点存多个字符
struct StringNode *next;
}StringNode, *String;
基本操作的实现
下列基本操作,采取的都是串的顺序存储中的静态数组实现方法,并且采取的 方案四:ch[0] 不用,长度仍用 length 表示
#define MAXLEN 255
typedef struct{
char ch[MAXLEN];
int length;
}SString;
求字串
SubString(&Sub, S, pos, len) :求子串。用 S u b Sub Sub 返回串 S S S 的第 p o s pos pos 个字符起长度为 l e n len len 的子串。
bool SubString(SString &Sub,SString S, int pos, int len){
// 字串范围越界
if (pos + len - 1 > S.length) return false;
for (int i = pos; i < pos + len; i ++ )
Sub.ch[i - pos + 1] = S.ch[i];
Sub.length = len;
return true;
}
比较操作
StrCompare(S, T) :比较操作。若 S > T S>T S>T,则返回值 > 0 >0 >0; 若 S = T S=T S=T,则返回值 = 0 =0 =0; 若 S < T S<T S<T,则返回值 < 0 <0 <0
int StrCompare(SString S, SString T){
for (int i = 1; i <= S.length && i <= T.length; i ++ )
if (S.ch[i] != T.ch[i])
return S.ch[i] - T.ch[i];
// 扫描过的所有字符都相同, 则长度长的串大
return S.length - T.length;
}
定位操作
Index(S, T) : 定位操作。若主串 S S S 中存在与串 T T T 值相同的子串,则返回它在主串 S S S 中第一次出现的位置;否则函数值为 0 0 0。
/*
定位操作分为两步:
1. 求字串
2. 比较
也就是我们上述说的两个操作.
*/
int Index(SString S, SString T){
int i = 1, n = StrLength(S), m = StrLength(T);
SString sub; // 用于暂存子串
while (i <= n - m + 1){
// 比较次数
SubString(sub, S, i, m); // 求字串
if (StrCompare(sub, T) != 0) ++ i; // 比较操作,=0为比较成功
else return i; // 返回字串在主串中的位置
}
return 0; // S中不存在与T相等的字串
}
字符串模式匹配
朴素模式匹配算法
主串长度为 n n n,模式串长度为 m m m
朴素模式匹配算法:将主串中 所有长度为 m 的子串依次与模式串对比,直到找到一个完全匹配的子串或所有的子串都不匹配为止。
最多对比 n − m + 1 n-m+1 n−m+1 个子串
使用串的基本操作实现的匹配算法其实就是上述的定位操作
int Index(SString S, SString T){
int i = 1, n = StrLength(S), m = StrLength(T);
SString sub; // 用于暂存子串
while (i <= n - m + 1){
// 比较次数
SubString(sub, S, i, m); // 求字串
if (StrCompare(sub, T) != 0) ++ i; // 比较操作,=0为比较成功
else return i; // 返回字串在主串中的位置
}
return 0; // S中不存在与T相等的字串
}
不用串的基本操作实现匹配算法:
int Index(SString S, SString T){
int i = 1, j = 1;
while (i <= S.length && j <= T.length){
if (S.ch[i] == T.ch[j]){
i ++;
j ++;
}
else{
i = i - j + 2; // i走到下一个位置
j = 1; // j回到1
}
}
if (j > T.length) return i - T.length;
else return 0;
}
KMP算法
K M P KMP KMP 算法中,长串指针不发生回溯;
需要注意,下述代码中的串的存储,如同上述存串的规则的方案四:不使用 ch[0],即数组下标从 1 1 1 开始。
显然,在长串和短串匹配的时候,我们要执行 i++, j++;
next 数组只和短串有关,和长串无关;next 数组同样是从 1 1 1 开始
j = next[j] 表示当和短串的第 j j j 个元素不匹配时,短串的指针应该回到 next[j] 处;当第一个元素就匹配失败时候,我们为了代码的统一性(美观),规定 j j j 指针指向 0 0 0 的位置,然后执行 i++, j++;
故,对于任何一个匹配算法,其实都有 next[1] = 0;,同理,对于第二个元素发生不匹配的情况,我们就只能拿短串的第一个元素和长串相比,故,对于任何一个匹配算法,其实也都有 next[2] = 1;
手求 next 数组:next[j] = 串的[1 ~ j - 1]中前后缀相等的最大长度 + 1; 恒有next[1] = 0, next[2] = 1
比如我们的Q串为:abaabc
next[1] = 0(特殊规定)
next[2]:按照上述定义为串的[1 ~ 1]中的前后缀相等的最大长度 + 1,显然,按照前后缀的定义,[1 ~ 1]的前后缀都为空,故前后缀相等的最大长度为0,即next[2] = 1
next[3]:串[1 ~ 2]为ab,前缀为a,后缀为b,显然a != b,故next[3] = 1
next[4]:串[1 ~ 3]为aba,前缀有三个:ab,a,空;后缀有三个ba,a,空,显然ab != ba,但是有a == a,即前后缀相等的最大长度为1,故next[4] = 2
next[5]:串[1 ~ 4]为abaa,前缀分别为:aba,ab,a,空;后缀分别为:baa,aa,a,空;显然,前后缀相等的最大长度还是1,故next[5] = 2
next[6]:串[1 ~ 5]为abaab,前缀分别为:abaa,aba,ab,a,空;后缀分别为:baab,aab,ab,b,空;显然有前缀ab和后缀ab是相等的,故前后缀相等的最大长度为2,即next[6] = 3
K M P KMP KMP 算法代码:
int Index_KMP (SString S, SString T, int next[]){
// S为长串,T为短串
int i = 1, j = 1;
while (i <= S.length && j <= T.length){
if (j == 0 || S.ch[i] == T.ch[j]){
i ++, j ++;
}
else
j = next[j];
}
if (j > T.length)
return i - T.length;
else
return 0;
}
求 n e x t next next 数组:(不要求)
// 我也忘了具体思想是个什么了,大概可能是 i 指向的是串尾,j 指向的是串中前缀中匹配最大的坐标
void get_next (SString T, int next[]){
// T为短串
int i = 1, j = 0;
next[1] = 0;
while (i < T.length){
if (j == 0 || T.ch[i] == T.ch[j]){
++ i; ++ j;
next[i] = j;
}
else
j = next[j];
}
}
K M P KMP KMP 的进一步优化即 nextval 数组:
比如短串: Q Q Q:aaab和长串 P P P :aaabaaaaab进行匹配,我们可以求得 next 为: 01234 01234 01234,
进行匹配的过程中,当 i = 4, j = 4 的时候发生失配,如果我们还是利用 n e x t next next 数组让 j j j 发生回溯的话,我们还需要进行 P [ 4 ] P[4] P[4] 和 Q [ 3 ] Q[3] Q[3], P [ 4 ] P[4] P[4] 和 Q [ 2 ] Q[2] Q[2], P [ 4 ] P[4] P[4] 和 Q [ 1 ] Q[1] Q[1] 这三次比较,但是,事实上,因为 Q [ 1 ] = Q [ 2 ] = Q [ 3 ] = Q [ 4 ] Q[1] = Q[2] = Q[3] = Q[4] Q[1]=Q[2]=Q[3]=Q[4] 的原因,当我们发生 P [ 4 ] ! = Q [ 4 ] P[4] != Q[4] P[4]!=Q[4] 的时候,完全没必要再把 Q [ 1 ] , Q [ 2 ] , Q [ 3 ] Q[1],Q[2],Q[3] Q[1],Q[2],Q[3] 和 P [ 4 ] P[4] P[4] 进行比较,拿同样相同的字符进行比较是毫无意义的。
手算 nextval 数组:首先算出 next 数组,恒有 nextval[1] = 0,从前到后扫描 next 数组,如果发现Q[next[j]] == Q[j]; 即发现按照 next 跳转后的字母和当前字母是一样的话,就有 nextval[j] = nextval[next[j]];,即把这个字母的 nextval 数组的值设置为跳转后的字母的 nextval 数组的值,相当于 “连跳”,如果跳转后的元素和当前元素不一样的话,那么 nextval 数组就不需要被更新,直接赋值为原 next 数组的值即可,即 nextval[j] = next[j]
故上述例子中,我们的 nextval 数组为: 00004 00004 00004
再来一个例子: a b a b a a ababaa ababaa :next[] = {0, 1, 1, 2, 3, 4}, nextval[] = {0, 1, 0, 1, 0, 4}
求 nextval 数组代码:
void get_nextval(SString T, int nextval[]){
nextval[1] = 0;
for (int j = 2; j <= T.length; j ++ )
{
if (T.ch[next[j]] == T.ch[j])
nextval[j] = nextval[next[j]];
else nextval[j] = next[j];
}
}