转眼就要博0了,导师开始让我看视频理解多模态方向的内容,重新一遍打基础吧,从Python,到NLP,再到视频理解,最后加上凸优化,一步一步来,疯学一个暑假。写这个博客作为我的笔记以及好文章的链接搬运,以便以后复习。
Python从入门到放弃
计算机视觉中video understanding领域有什么研究方向和比较重要的成果?
万字长文漫谈视频理解
视频理解综述:动作识别、时序动作定位、视频Embedding
视频理解/动作分类 模型汇总(2022.06.28 更新)
视频多模态预训练/检索模型
视频多模态预训练/检索模型(二)
多模态视频文本时序定位
多模态预训练文章笔记
一.多模态大模型
1.1 统一架构
多模态大模型都是Transformer based架构,NLP对文本进行embedding,CV对图像patch进行Embedding,从图像、视频、文本、语音数据中提取特征,转换为tokens,进行不同模态特征的对齐,送入Transformer进行运算。
1.2 模型基础
预训练语言模型的前世今生 - 从Word Embedding到RNN/LSTM到Transformer到GPT到BERT
1.2.1 Transformer
Transformer 是一种基于自注意力机制(self-attention)的序列到序列(sequence-to-sequence)模型。它使用了多头注意力机制,能够并行地关注不同位置的信息。Transformer 在自然语言处理领域中广泛应用,如机器翻译和文本生成。
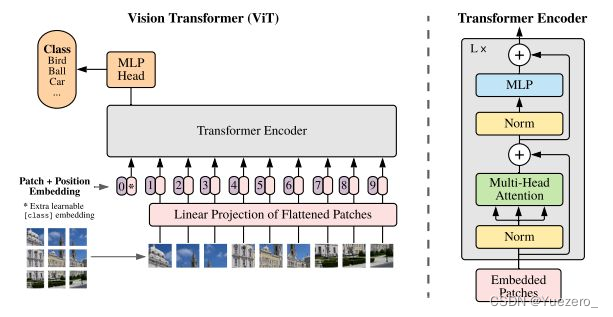
1.2.2 ViT
ViT(Vision Transformer)是一种将 Transformer 模型应用于图像分类任务的方法。它将图像分割为一系列的小块,并将每个小块作为序列输入 Transformer 模型。通过自注意力机制,ViT 能够在图像中捕捉全局和局部的视觉信息,实现图像分类。
1.2.3 Bert
Bert (Bidirectional Encoder Representations from Transformers)是一种双向 Transformer 编码器模型,通过预训练和微调的方式,提供了深度的语言理解能力。与传统的单向语言模型不同,Bert 同时考虑了上下文的信息,使得它在词义消歧、命名实体识别等任务上具有优势。
1.2.4 CrossAttention
CrossAttention 是 Transformer 模型中的一种注意力机制。与自注意力机制不同,CrossAttention 允许模型在处理输入序列时,同时关注另一个相关的序列。CrossAttention 在多模态任务中经常使用,例如将图像和文本进行对齐或生成多模态表示。
1.2.5 CLIP
CLIP (Contrastive Language-Image Pretraining)是一种跨模态的预训练模型,它能够同时处理图像和文本。通过将图像和文本进行对比学习,CLIP 提供了一个共享的视觉和语义空间,使得图像和文本可以进行直接的匹配和检索。
1.2.6 GPT
GPT(Generative Pretrained Transformer)是一种基于 Transformer 模型的预训练语言生成模型。GPT 通过大规模的无监督训练来学习语言的语法和语义,能够生成连贯且逼真的文本。GPT 在文本生成、对话系统等任务中取得了显著的成果。
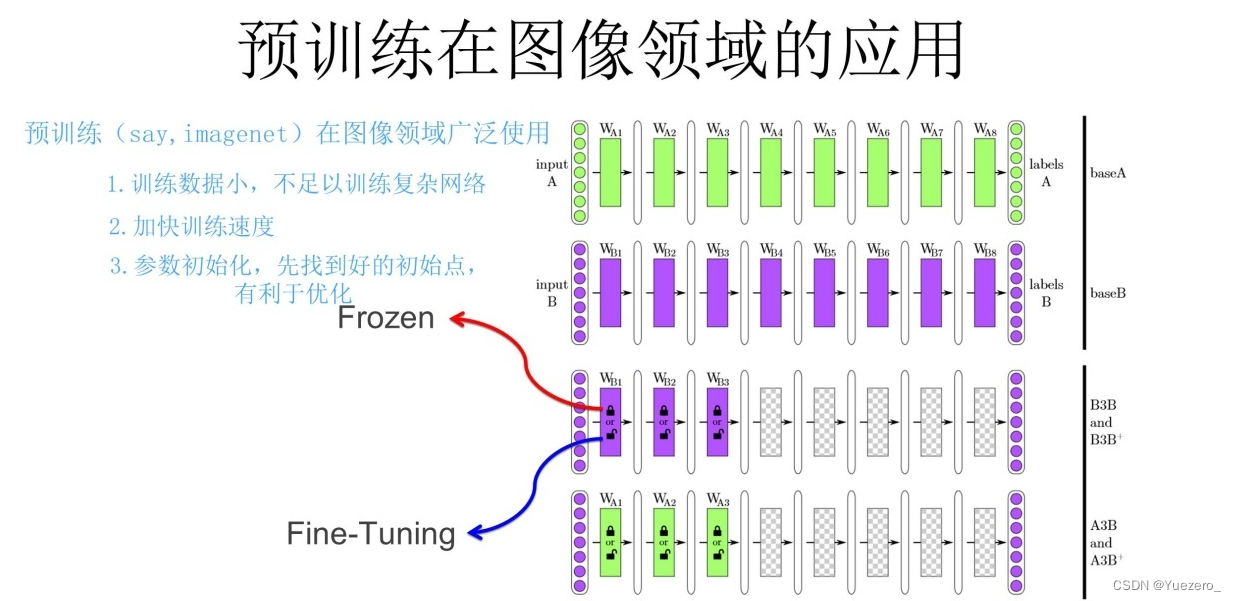
1.2.7 预训练
通过 ImageNet 数据集我们训练出一个模型 A。由于上面提到 CNN 的浅层学到的特征通用性特别强,我们可以对模型 A 做出一部分改进得到模型 B(两种方法):
- 冻结:浅层参数使用模型 A 的参数,高层参数随机初始化,浅层参数一直不变,然后利用领导给出的 30 张图片训练参数。
- 微调:浅层参数使用模型 A 的参数,高层参数随机初始化,然后利用领导给出的 30 张图片训练参数,但是在这里浅层参数会随着任务的训练不断发生变化。
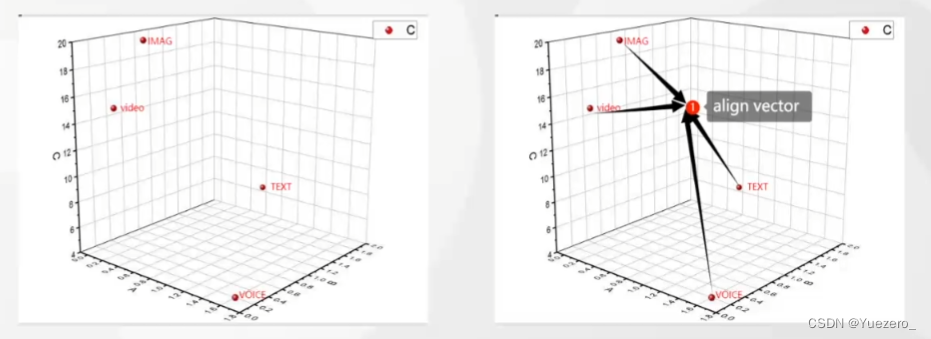
1.2.6 模态对齐
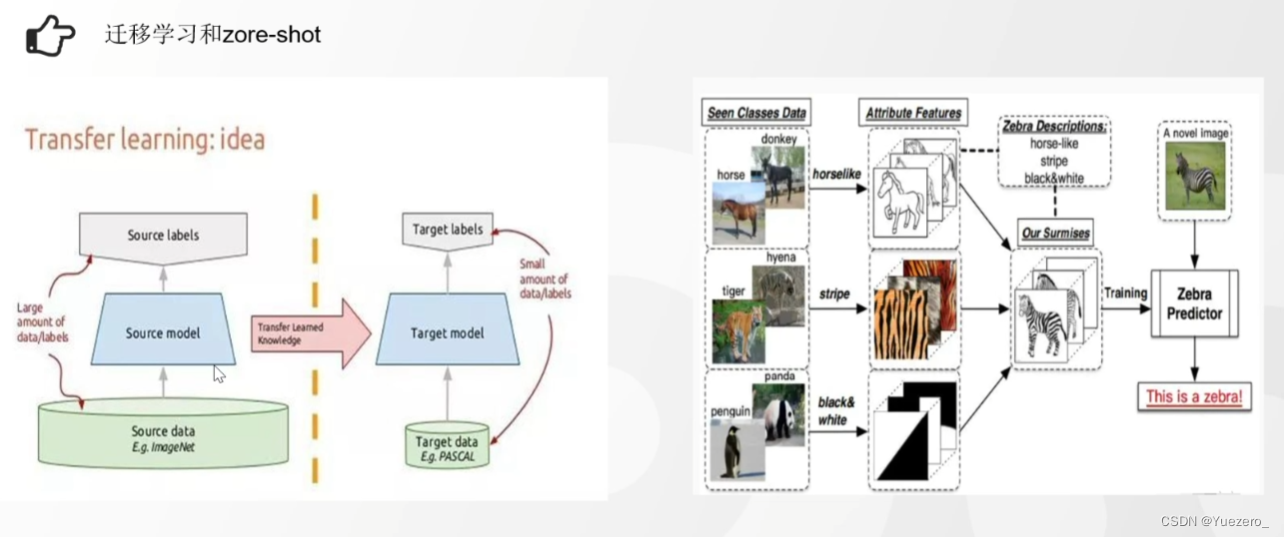
1.2.7 迁移与零样本学习
迁移学习(小模型) 通常使用较小的模型,在源领域训练好的知识和参数可以被迁移到目标领域,从而加速目标任务的学习过程。这种方式可以提高模型的泛化能力和效果,在数据稀缺的情况下也能取得较好的结果。
Zero-shot(大模型) 解决从未见过类别的样本进行分类的问题。在零样本学习中,我们通常使用大模型,如GPT-3等。这些模型在训练阶段通过学习大规模数据获取了广泛的知识,并且能够通过关联不同领域的知识来进行分类。通过利用这些大模型的泛化能力,我们可以在没有见过的类别上进行分类,实现零样本学习。
1.2.8 拓展阅读
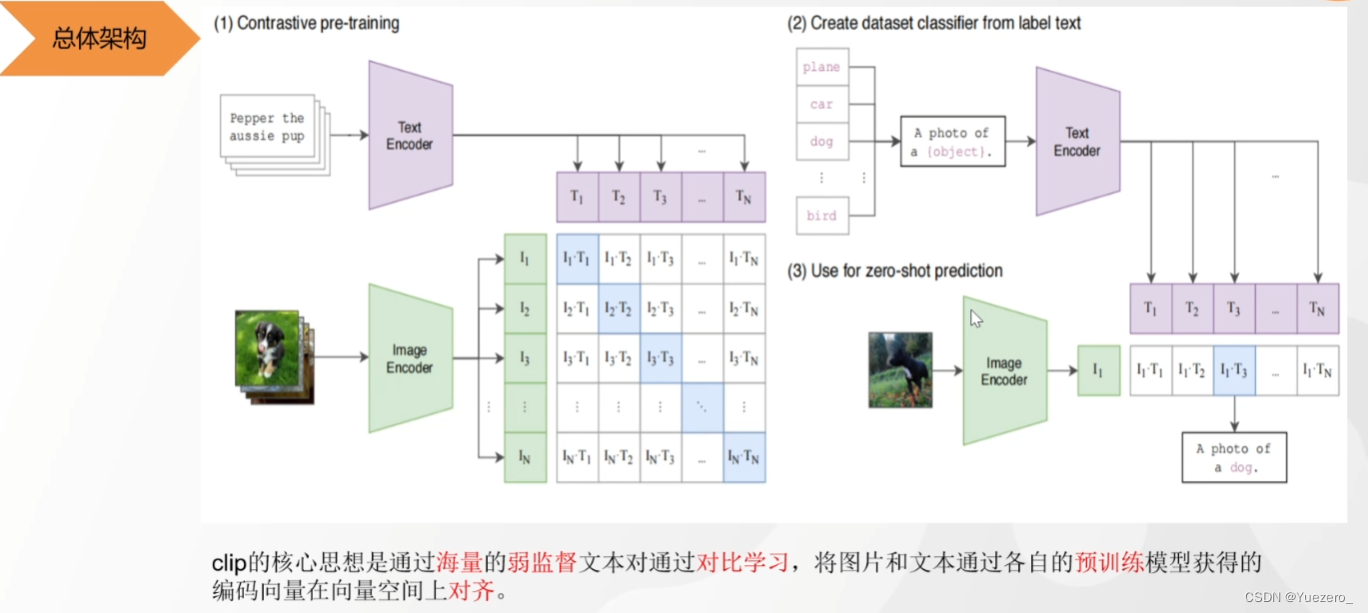
CLIP——图文匹配
(1) 预训练图像和文本编码器:训练<图片,文本>对,进行对比学习。N个图像和N个文本,用Bert和ViT提取文本和图片的特征(768维),向量两两相乘,得到<图片,文本>对儿之间的余弦相似度(向量乘法)。标签对比学习:对角线上相匹配的图文是正样本(正确的pair=1),其他不匹配的全是负样本(错误的pair=0),这两个标签计算loss反向传播,最大化正样本对的余弦相似度,最小化负样本对的优余弦相似度,约束前面的Bert和ViT梯度下降修改参数。最终预训练得到文本和图像编码器Bert和ViT。
(2)和(3) Zero-shot实现图文匹配:根据刚刚的预训练,任意给出文本(dog、car、cat…)与图片计算余弦相似度(相乘),相似度分数最大的就是正确的<图片,文本>对
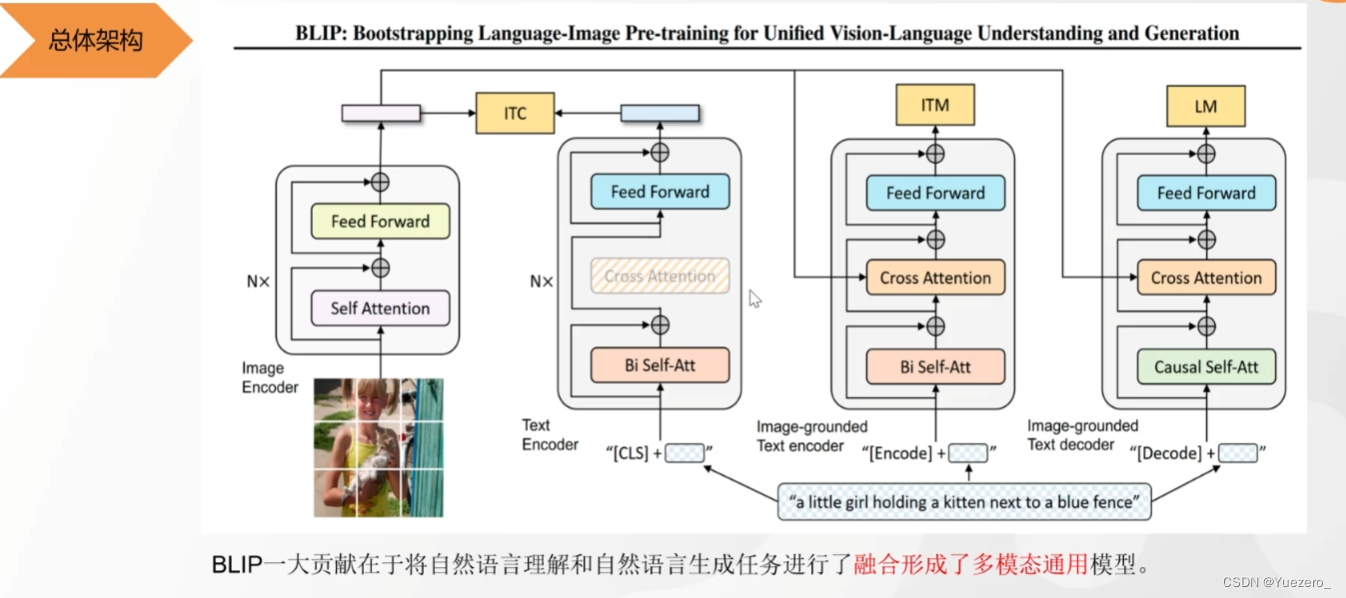
BLIP——图文匹配&图生文
(1)对比学习ITC:图片编码器提取的向量 与 第一个文本编码器提取的向量,进行对比学习。(bert的双向注意力)
(2)二分类任务ITM:图片编码器提取的向量 与 第二个文本编码器提取的向量进行cross attention,融合的向量进行二分类任务(文本和图片是不是描述的同一件事),以更细粒度的让文本和图像的难样本对齐。(bert的双向注意力)
(3)生成任务LM:图片编码器提取的向量 与 第三个文本编码器提取的向量进行cross attention,融合的向量进行文本生成任务(根据图像生成描述文本)。(gpt的单向注意力)
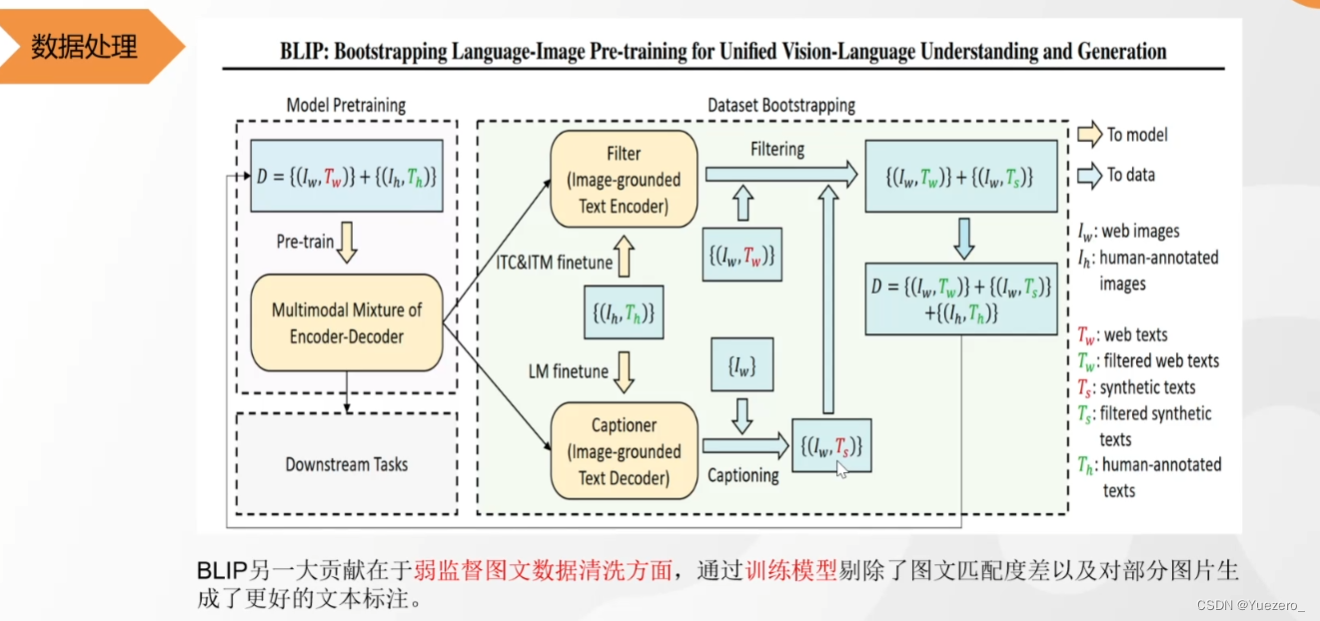
BLIP2——图文匹配&图生文
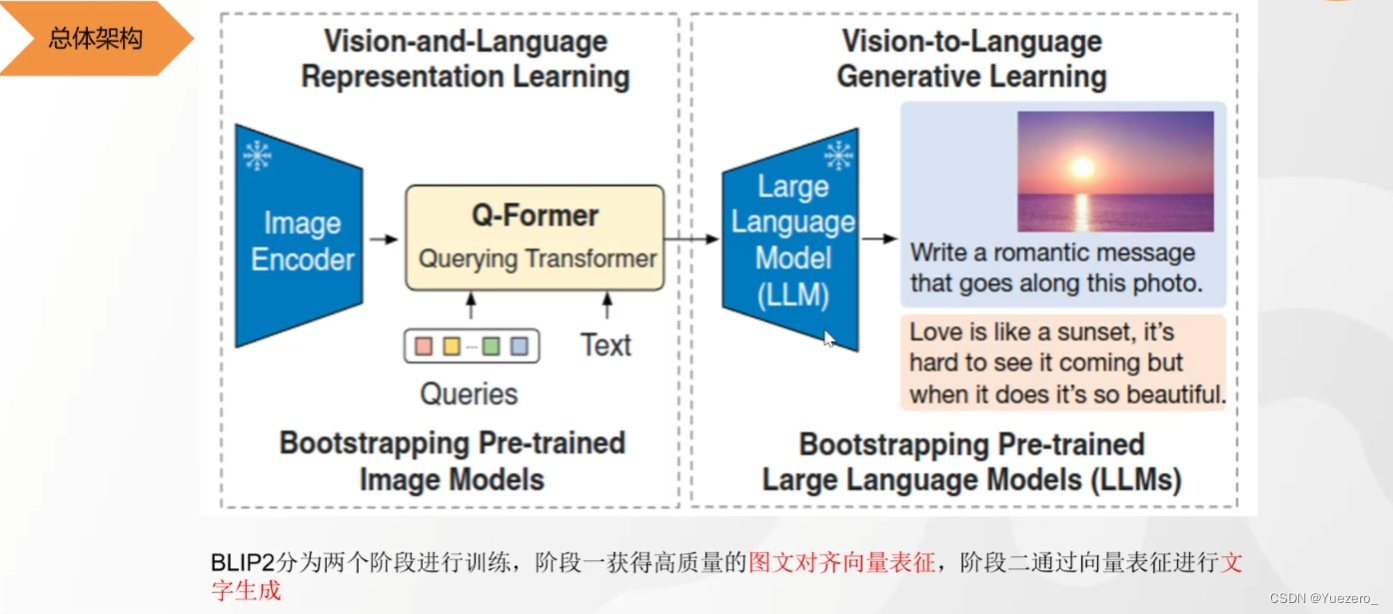
(1)阶段一:使用QFormer将 图像特征向量 投影到 文本特征空间,使得LLM可以理解图像向量的特征。
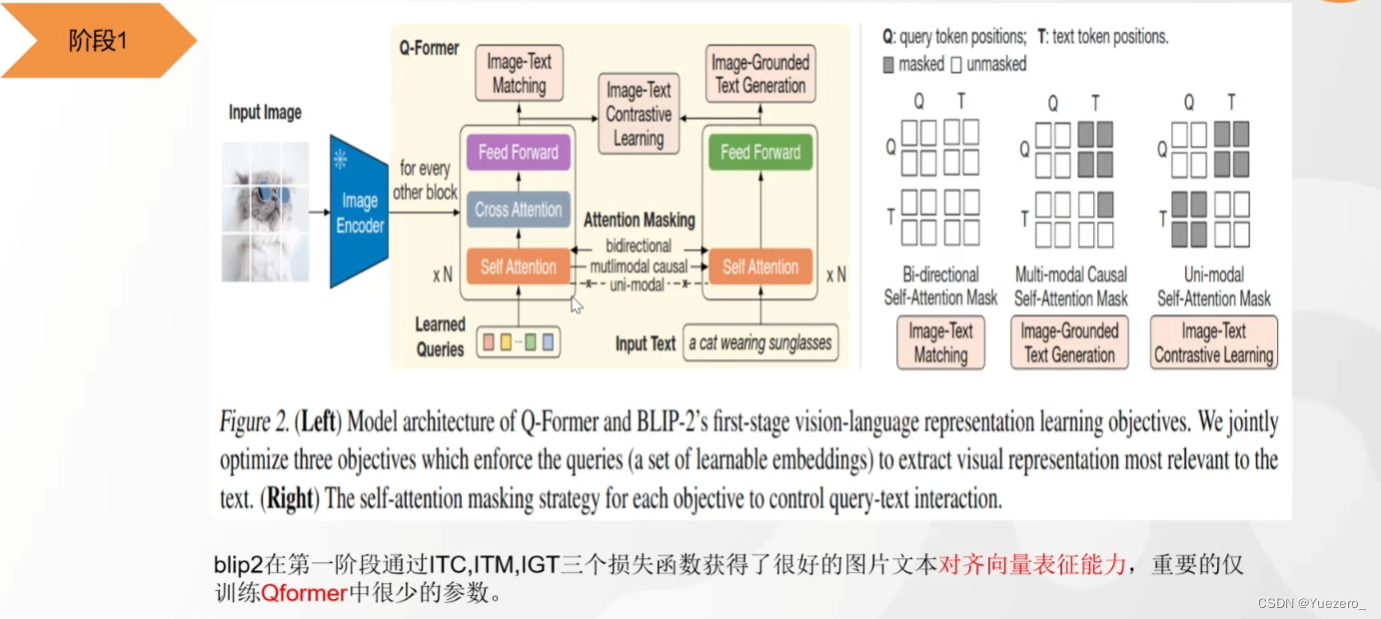
(2)阶段二:把图片特征输入LLM(作为prompt),生成对应的图像的文本描述。
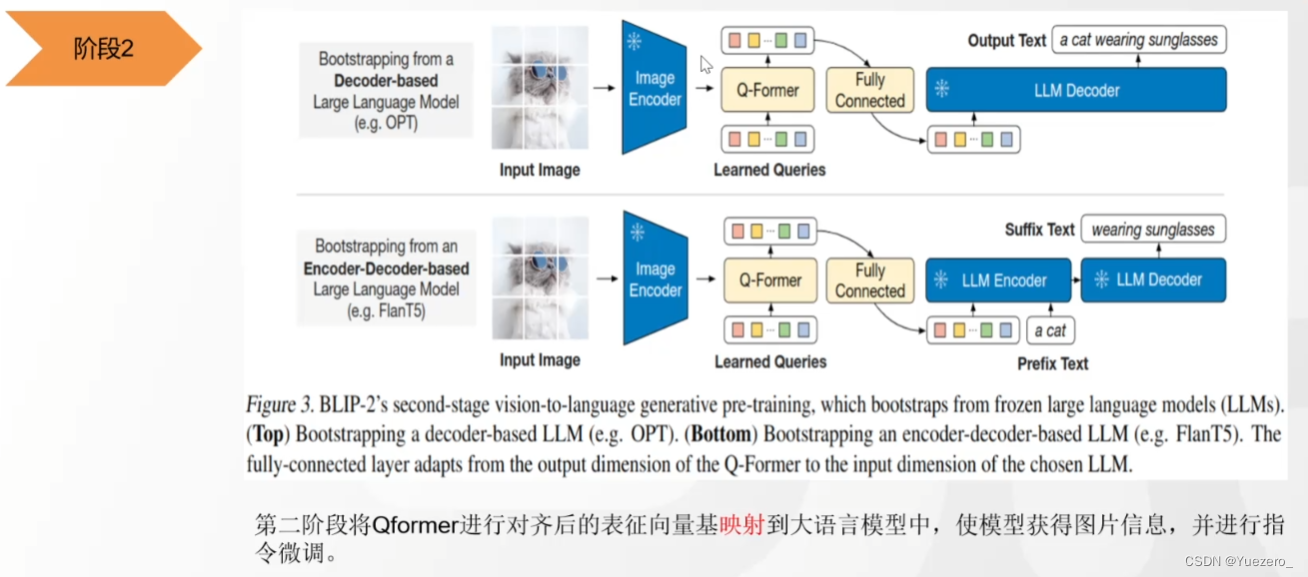
BLIP2对细节理解不到位的原因:ViT的patch级tokenlization对细节处理不到位。

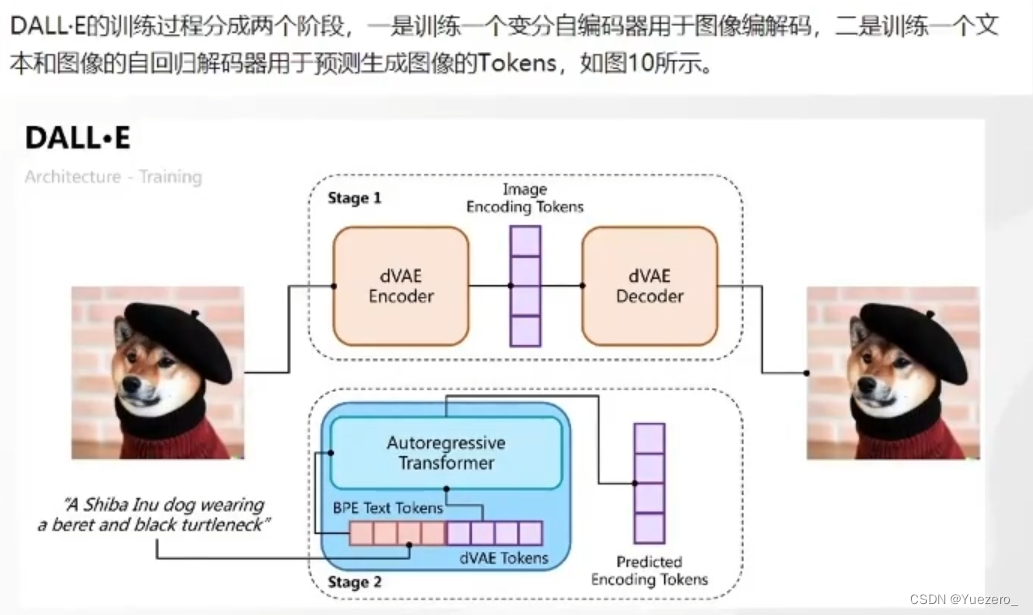
DALL·E——文生图
(1)训练过程:将图片编码为one-hot向量,再解码为一只狗,实现无损压缩图像。(loss是原图和解码图片的差别)
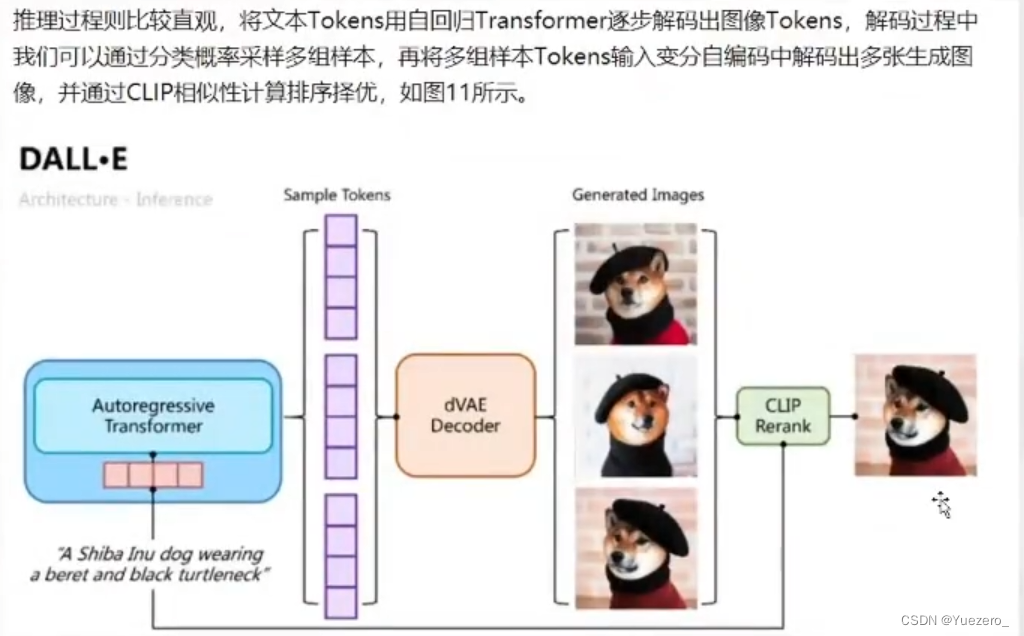
(2)推理过程:自回归编码器(GPT)通过文本tokens预测出多种图片tokens,再解码为对应的图片,最后使用CLIP进行图文匹配,得到解码图片中与文本最相似的图片。
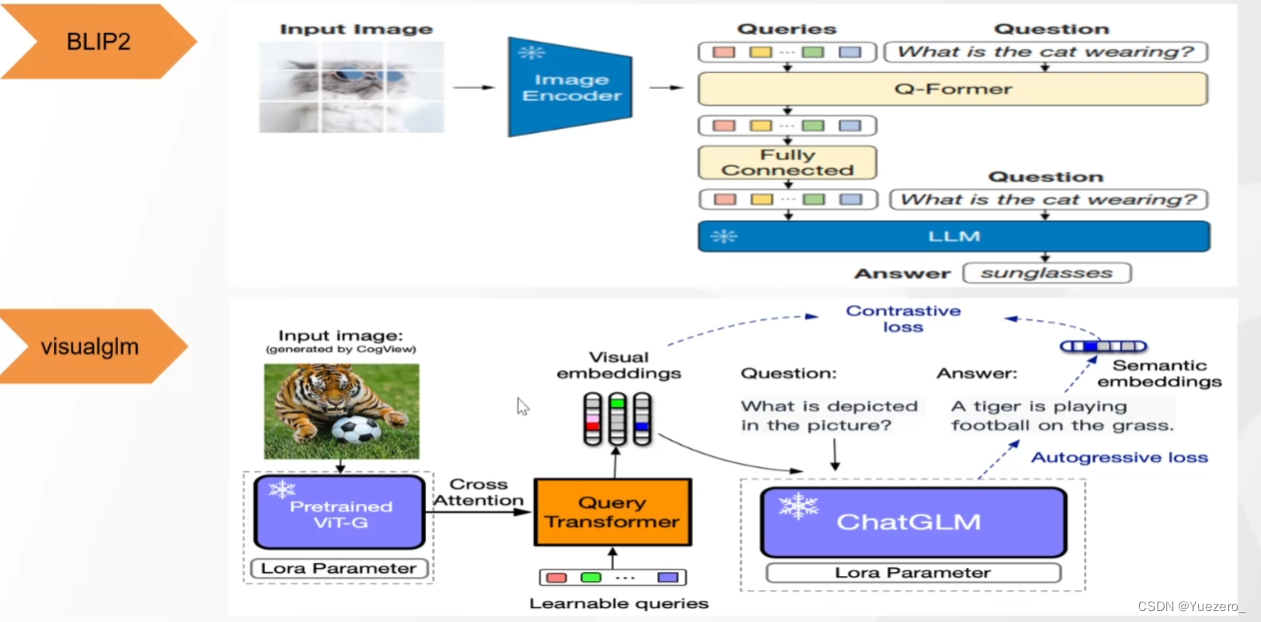
VisualGLM——中文版BLIP2
使用Lora训练。
但文本生成经常胡说八道,原因在于ChatGLM的模型规模太小7B。
二.大模型基础
学习哪些大模型?(训练不同规模的模型适应不同场景)
- 在线大模型:OpneAI系列的大模型组

- 开源大模型:ChatGLM 6B 和 VisualGM 6B

2.1 在线大模型
需要OpenAI的key,私人数据被openai共享,不能部署在本地,只能调用API接口在线微调Openai公司的大模型。
语言大模型:

图文多模态大模型:

语音大模型:

文本嵌入大模型:根据文本语义编码,语义越接近,向量越接近。

审查大模型:

编程大模型:

2.2 开源大模型
根据下游任务使用开源微调框架进行微调训练,也可以本地部署。
实时更新的OPEN LLM排行榜
ChatGLM——中文语言开源大模型



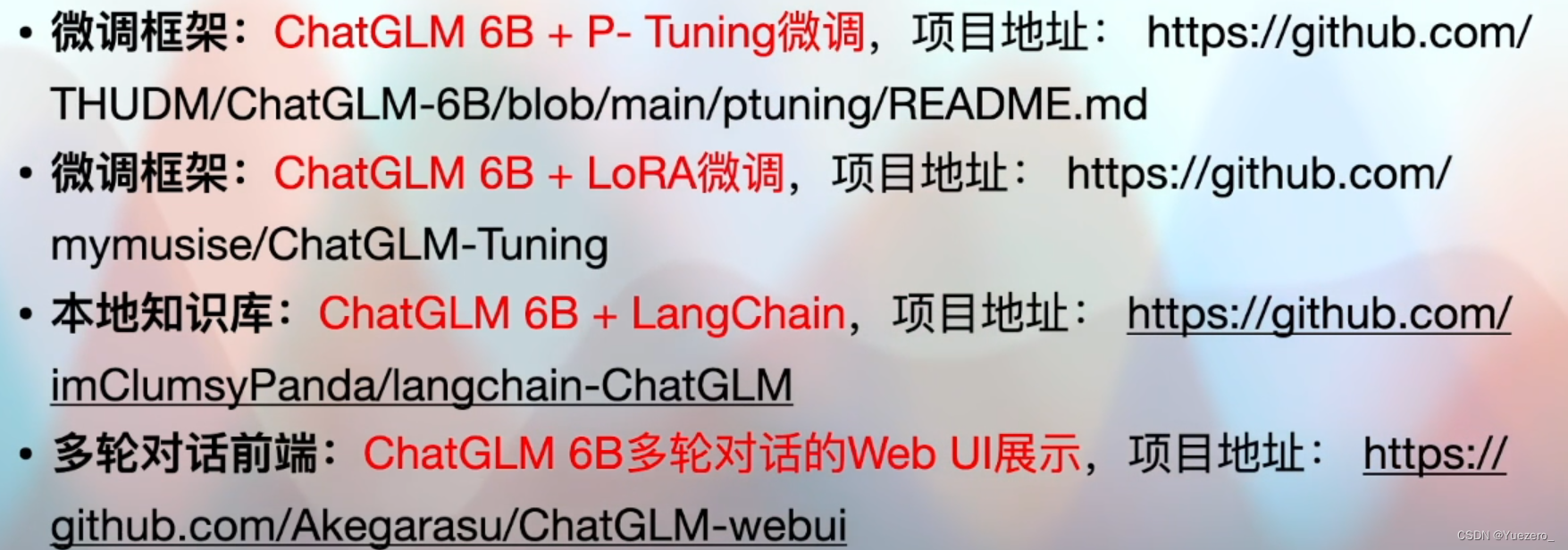

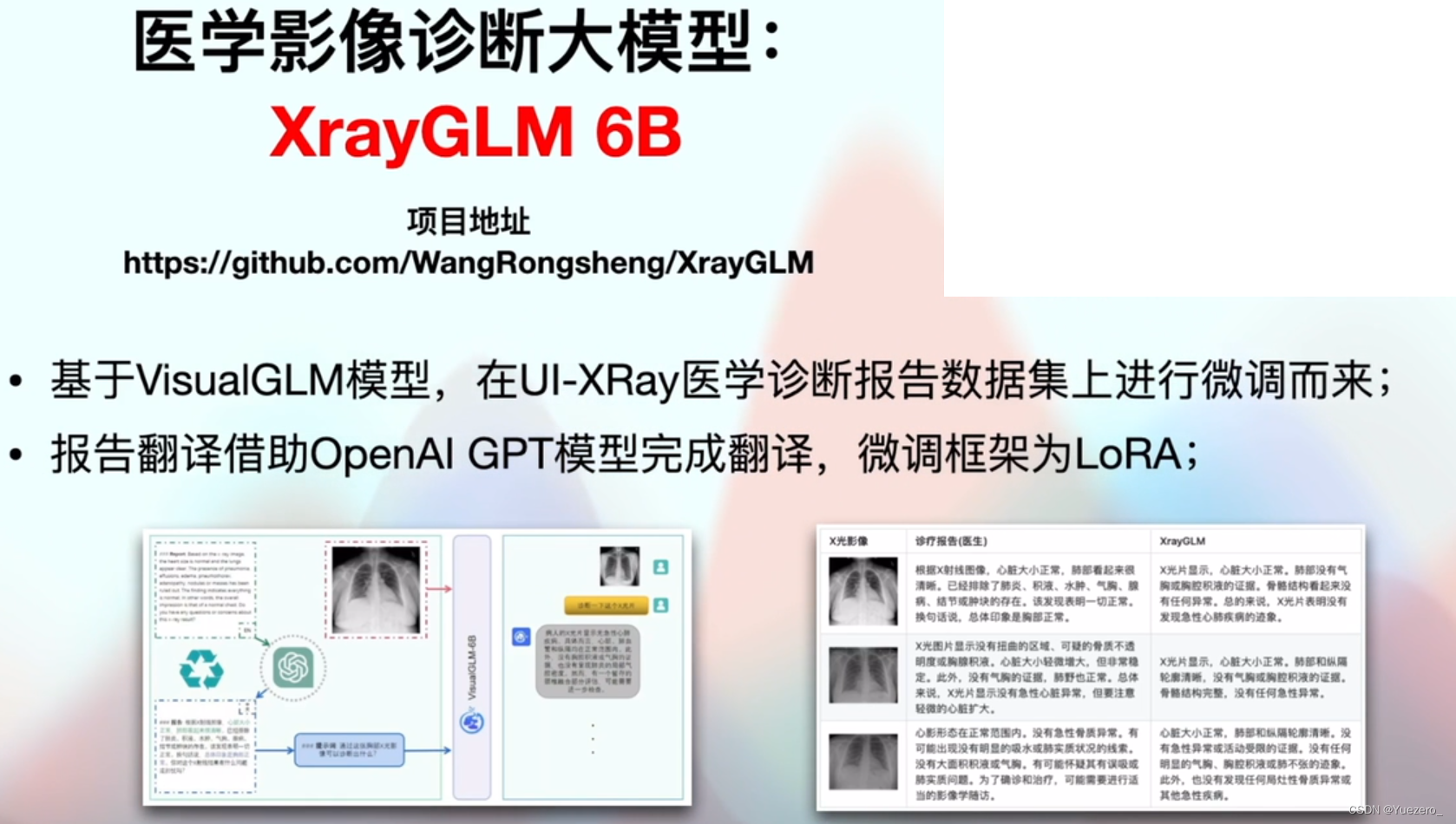
VisualGLM——中文多模态开源大模型


三. 大模型微调
-
全量微调(Full Fine-tuning,FT)将预训练好的模型的所有参数都进行微调,包括底层的特征提取器和顶层的分类器。这种方法通常需要较大的计算资源和长时间的训练,但可以获得相对较好的性能。
-
高效微调(Partial Fine-tuning,PEFT)则是一种更加高效的微调方法,它仅对部分参数进行微调。具体来说,我们冻结预训练模型的底层参数(如特征提取器)不进行微调,只微调顶层的分类器或一部分顶层参数。这样可以更快地完成微调过程,减少计算资源和训练时间的消耗,同时在一定程度上保留了底层参数的知识。
-
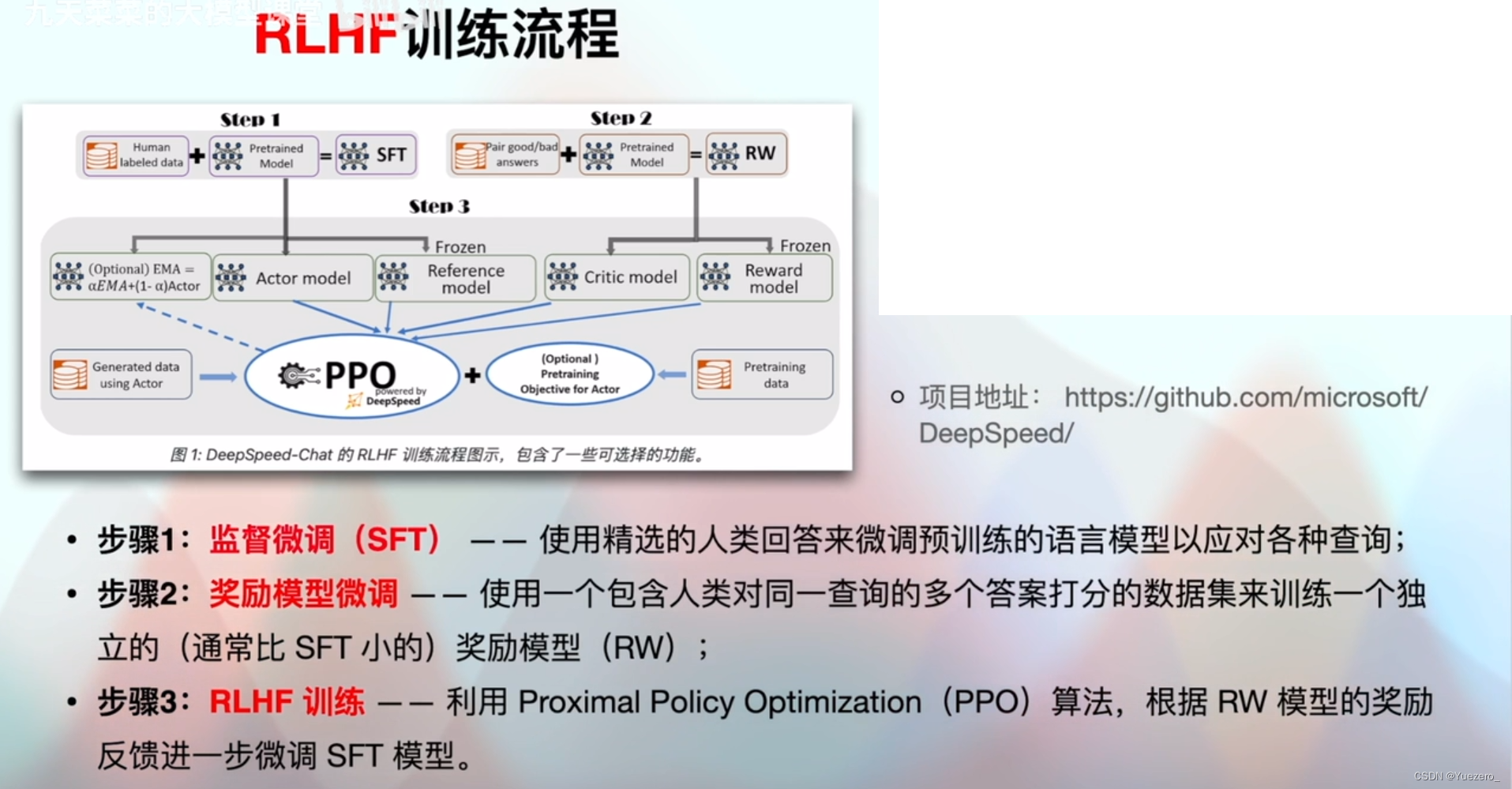
基于强化学习的进阶微调(Reinforcement Learning-based Hierarchical Fine-tuning,RLHF)使用强化学习的思想来指导微调的过程。通常,在微调过程中,我们定义一个奖励函数并通过强化学习的方式来最大化奖励。这样可以使得模型在微调过程中更加智能地进行参数更新,从而获得更好的性能和泛化能力。


3.1 高效微调 PEFT

3.1.1 LoRA


3.1.2 Prefix Tuning

3.1.3 Prompt Tuning

3.1.4 P-Tuning V2

3.2 RLHF

四.硬件和操作系统要求

4.1 显卡
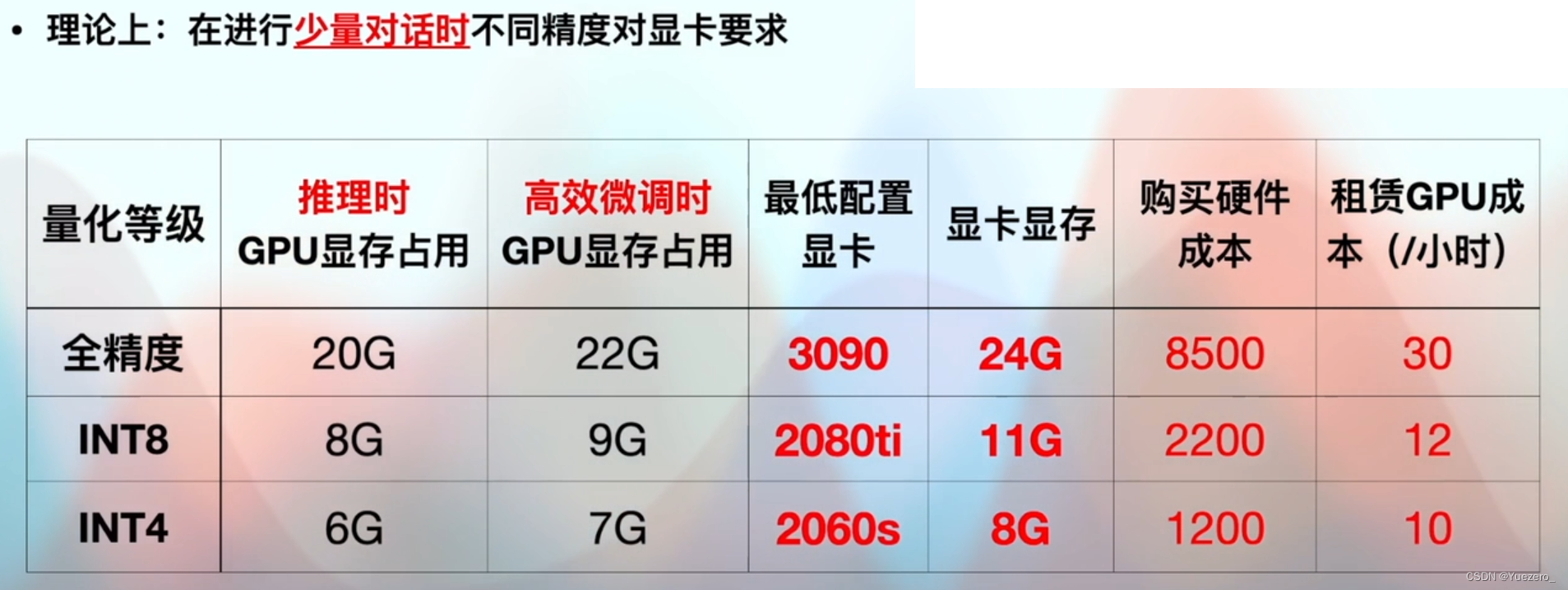
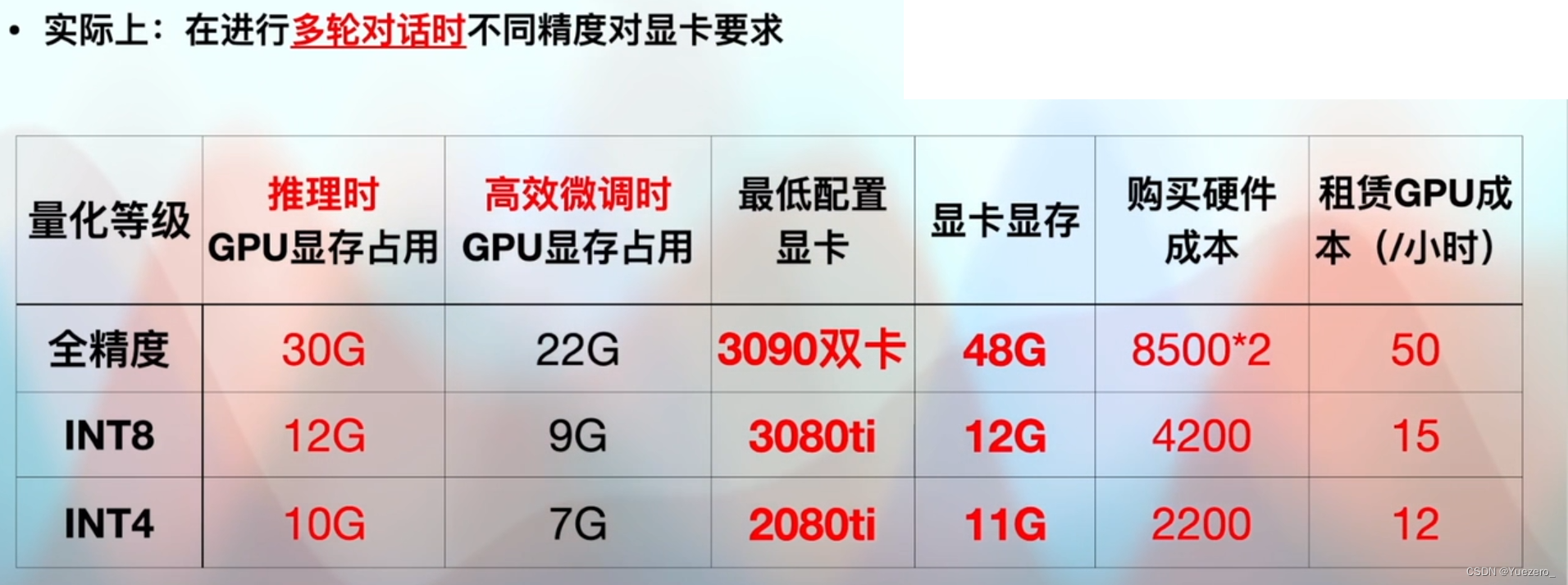



4.2 操作系统

五. LangChian









