引言
CLIP全称Constrastive Language-Image Pre-training,是OpenAI推出的采用对比学习的文本-图像预训练模型。CLIP惊艳之处在于架构非常简洁且效果好到难以置信,在zero-shot文本-图像检索,zero-shot图像分类,文本→图像生成任务guidance,open-domain 检测分割等任务上均有非常惊艳的表现。
论文地址:clip论文
github地址:code
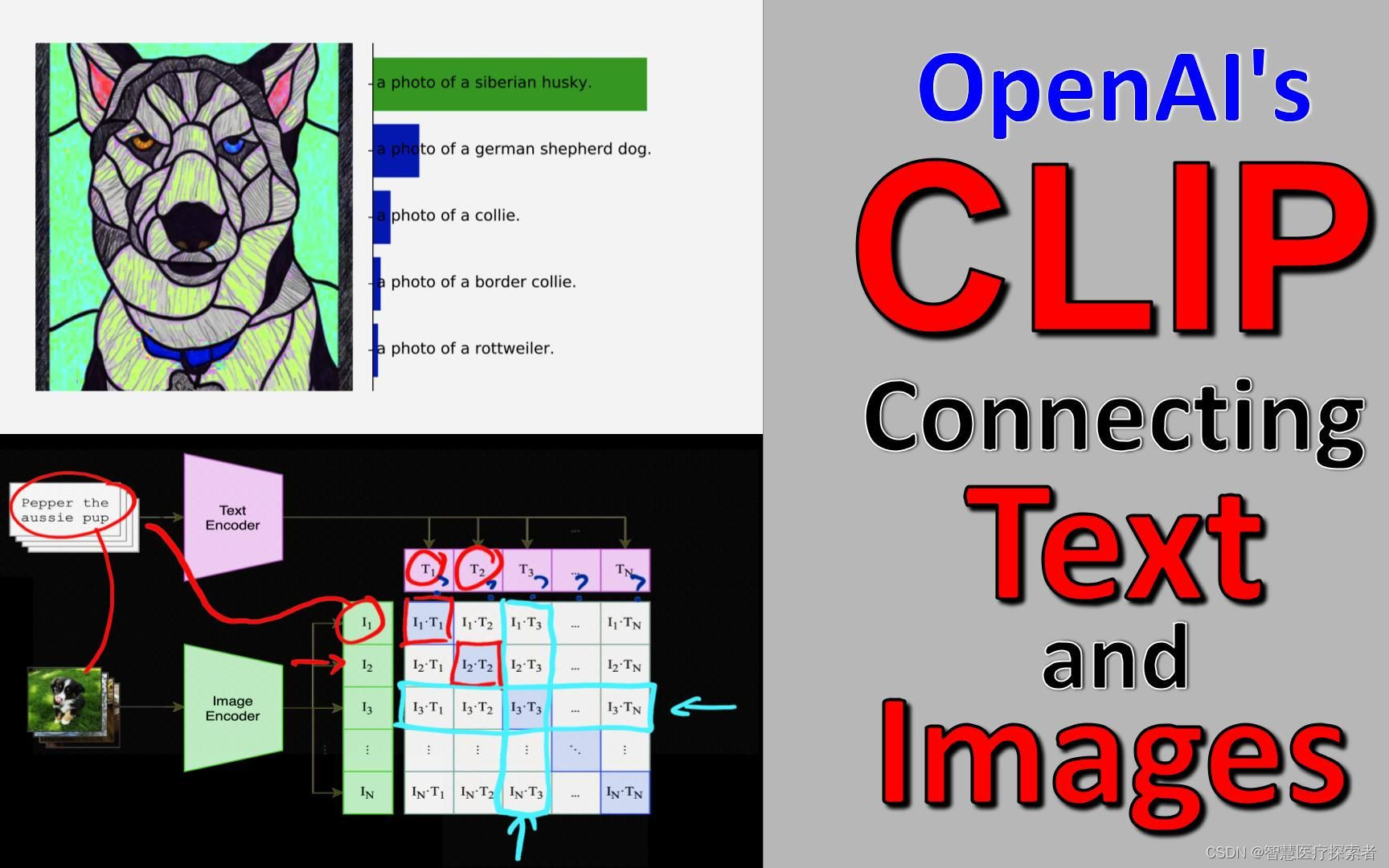
1 Clip模型介绍
1.1 Zero-Shot Learning
1.1.1 Zero-Shot Learning的定义
零次学习(Zero-Shot Learning,简称ZSL)假设斑马是未见过的类别,但根据描述外形和马相似、有类似老虎的条纹、具有熊猫相似的颜色,通过这些描述推理出斑马的具体形态,从而能对斑马进行辨认。零次学习就是希望能够模仿人类的这个推理过程,使得计算机具有识别新事物的能力,如下图所示。
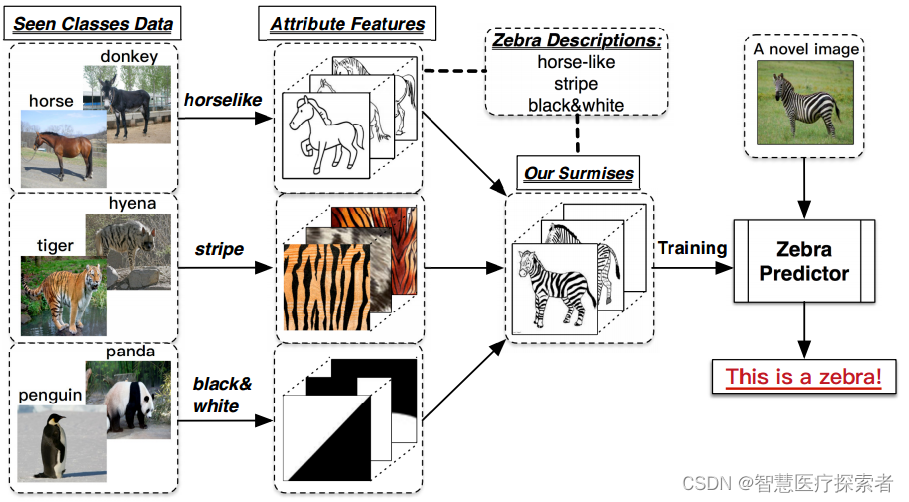
如今深度学习非常火热,使得纯监督学习在很多任务上都达到了让人惊叹的结果,但其限制是:往往需要足够多的样本才能训练出足够好的模型,并且利用猫狗训练出来的分类器,就只能对猫狗进行分类,其他的物种它都无法识别。这样的模型显然并不符合我们对人工智能的终极想象,我们希望机器能够像上文中的小暗一样,具有通过推理,识别新类别的能力。
ZSL就是希望我们的模型能够对其从没见过的类别进行分类,让机器具有推理能力,实现真正的智能。其中零次(Zero-shot)是指对于要分类的类别对象,一次也不学习。
1.1.2 Zero-Shot Learning的方法
1.1.3 Zero-Shot Learning面临的问题
领域漂移问题(domain shift problem)
该问题的正式定义首先由[2]提出。简单来说,就是同一种属性,在不同的类别中,视觉特征的表现可能很大。如图3所示,斑马和猪都有尾巴,因此在它的类别语义表示中,“有尾巴”这一项都是非0值,但是两者尾巴的视觉特征却相差很远。如果斑马是训练集,而猪是测试集,那么利用斑马训练出来的模型,则很难正确地对猪进行分类。

枢纽点问题(Hubness problem)
这其实是高维空间中固有的问题:在高维空间中,某些点会成为大多数点的最近邻点。这听上去有些反直观,细节方面可以参考[3]。由于ZSL在计算最终的正确率时,使用的是K-NN,所以会受到hubness problem的影响,并且[4]中,证明了基于岭回归的方法会加重hubness problem问题。
语义间隔(semantic gap)
样本的特征往往是视觉特征,比如用深度网络提取到的特征,而语义表示却是非视觉的,这直接反应到数据上其实就是:样本在特征空间中所构成的流型与语义空间中类别构成的流型是不一致的。

这使得直接学习两者之间的映射变得困难。
1.2 Clip模型
1.2.1 CLIP模型创新点
CLIP的创新之处在于,它能够将图像和文本映射到一个共享的向量空间中,从而使得模型能够理解图像和文本之间的语义关系。这种共享的向量空间使得CLIP在图像和文本之间实现了无监督的联合学习,从而可以用于各种视觉和语言任务。
CLIP的设计灵感源于一个简单的思想:让模型理解图像和文本之间的关系,不仅仅是通过监督训练,而是通过自监督的方式。CLIP通过大量的图像和文本对来训练,使得模型在向量空间中将相应的图像和文本嵌入彼此相近。
CLIP将图像和文本先分别输入一个图像编码器image_encoder和一个文本编码器text_encoder,得到图像和文本的向量表示 I_f 和 T_f 。然后将图像和文本的向量表示映射到一个joint multimodal sapce,得到新的可直接进行比较的图像和文本的向量表示 I_e 和T_e (这是多模态学习中常用的一种方法,不同模态的数据表示之间可能存在gap,无法进行直接的比较,因此先将不同模态的数据映射到同一个多模态空间,有利于后续的相似度计算等操作)。然后计算图像向量和文本向量之间的cosine相似度。最后,对比学习的目标函数就是让正样本对的相似度较高,负样本对的相似度较低。
1.2.2 CLIP模型的特点
统一的向量空间: CLIP的一个关键创新是将图像和文本都映射到同一个向量空间中。这使得模型能够直接在向量空间中计算图像和文本之间的相似性,而无需额外的中间表示。
对比学习: CLIP使用对比学习的方式进行预训练。模型被要求将来自同一个样本的图像和文本嵌入映射到相近的位置,而将来自不同样本的嵌入映射到较远的位置。这使得模型能够学习到图像和文本之间的共同特征。
多语言支持: CLIP的预训练模型是多语言的,这意味着它可以处理多种语言的文本,并将它们嵌入到共享的向量空间中。
无监督学习: CLIP的预训练是无监督的,这意味着它不需要大量标注数据来指导训练。它从互联网上的文本和图像数据中学习,使得它在各种领域的任务上都能够表现出色。
1.2.3 CLIP模型训练
CLIP模型训练分为三个阶段:
- Contrastive pre-training:预训练阶段,使用图片 - 文本对进行对比学习训练;
- Create dataset classifier from label text:提取预测类别文本特征;
- Use for zero-shot predictiion:进行 Zero-Shoot 推理预测;
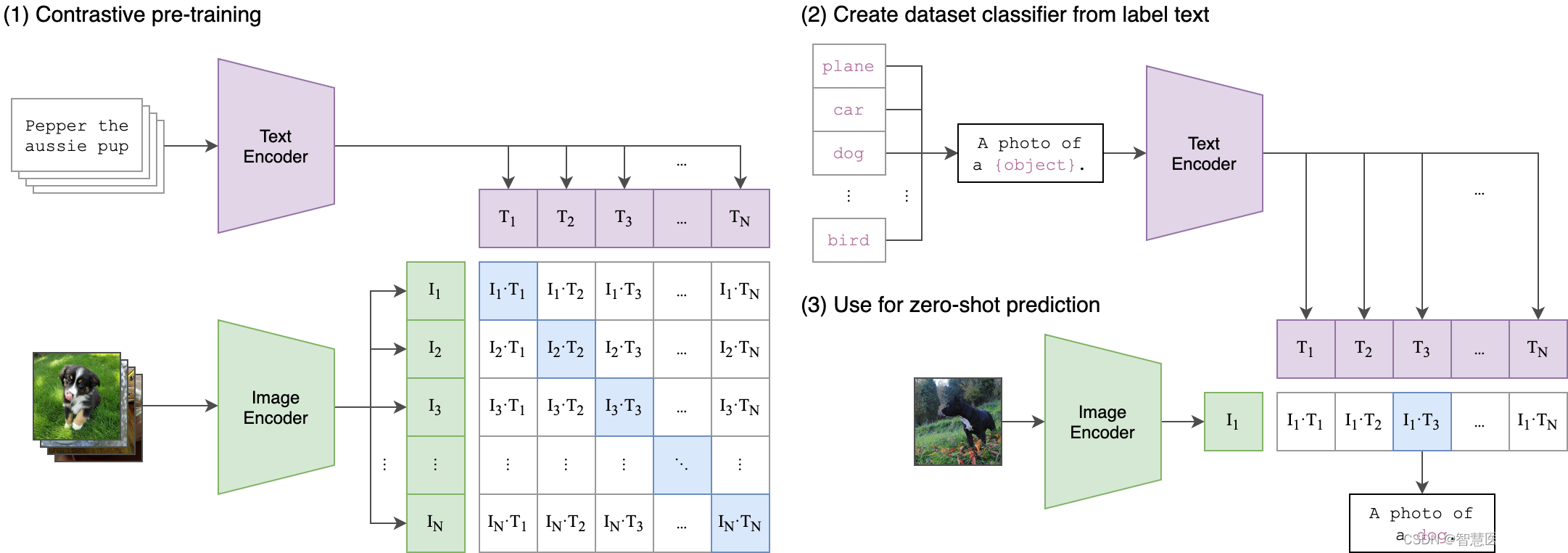
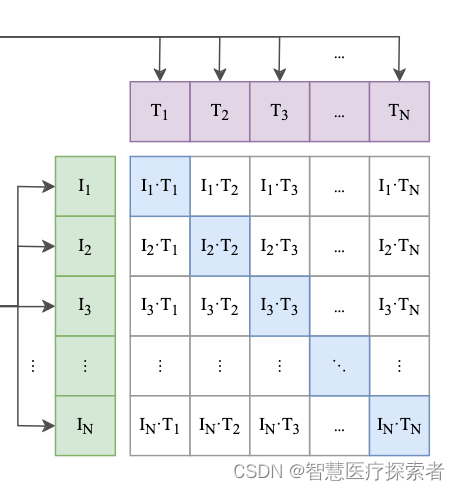
在预训练阶段,对比学习十分灵活,只需要定义好正样本对和负样本对就行了,其中能够配对的图片-文本对即为正样本。具体来说,先分别对图像和文本提特征,这时图像对应生成 I1、I2 ... In 的特征向量,文本对应生成T1、T2 ... Tn 的特征向量,然后中间对角线为正样本,其余均为负样本。这样的话就形成了n个正样本,n^2 - n个负样本。一旦有了正负样本,模型就可以通过对比学习的方式训练起来了,完全不需要手工的标注。自监督的训练需要大量的数据,OPEN AI的这个训练数据量大约在 4亿个的数量级。
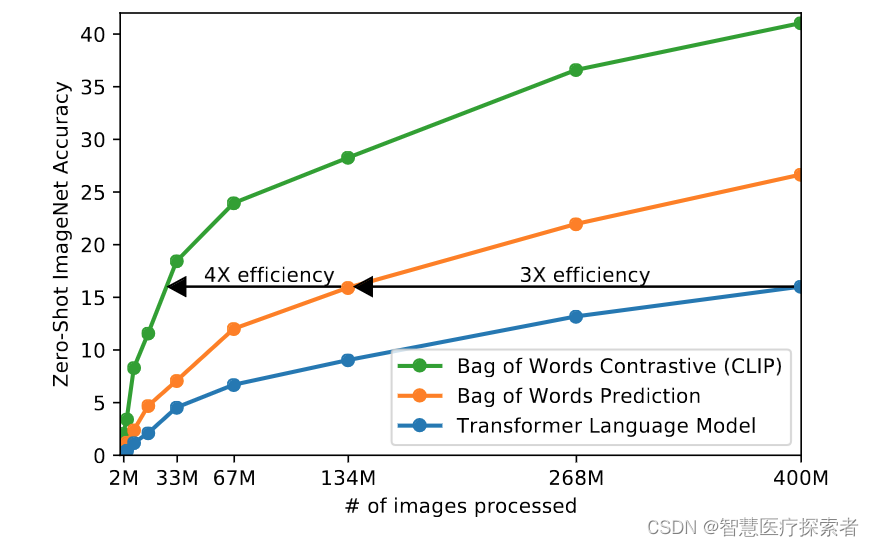
由于训练数据巨大,训练十分耗费时间,所以必须对训练策略进行一些改进以提升训练效率。采用对比学习进行训练的一个重要原因也是考虑到训练效率。如下图最下面的蓝线表示像GPT2这种预测型的任务(预测型的任务是指,我有一张图片,去预测图片对应的描述,这个时候因为人类的语言是个奇妙又伟大的东西,一张图往往能对应出多种文本描述,比如姚明篮球打得好和姚明真高,对于描述同一张图并不冲突),可以看到是最慢的。中间黄线是指一种bag of words 的方式,不需要逐字逐句地去预测文本,文本已经抽象成特征,相应的约束也放宽了,这样做训练速度立马提高了 3 倍。接下来进一步放宽约束,不再去预测单词,而是去判断图片-文本对,也就是绿色的线 对比学习的方法,这样效率又可以一下提升至4倍。
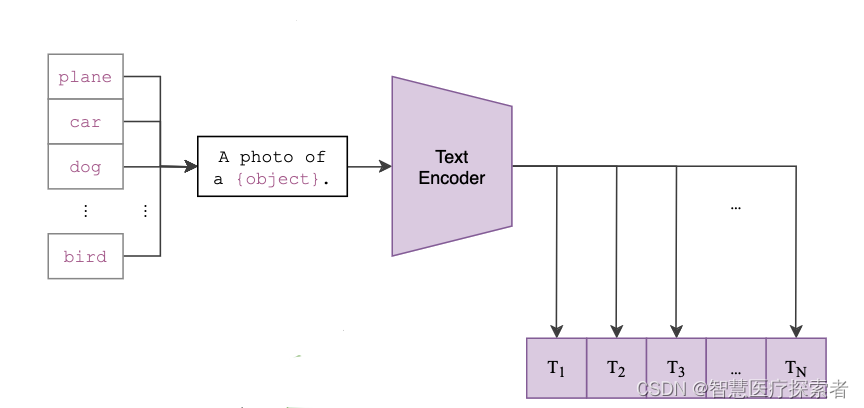
等训练好了,然后进入前向预测阶段。首先需要对文本类别进行一些处理,拿 ImageNet 数据集的 1000 个类别来说,原始的类别都是单词,而 CLIP 预训练时候的文本端出入的是个句子,这样一来为了统一就需要把单词构造成句子,怎么做呢?可以使用 A photo of a {object}. 的提示模板 (prompt template) 进行构造,比如对于 dog,就构造成 A photo of a dog.,然后再送入 Text Encoder 进行特征提取,就 ImageNet 而言就会得到一个 1000 维的特征向量,整个过程如下:
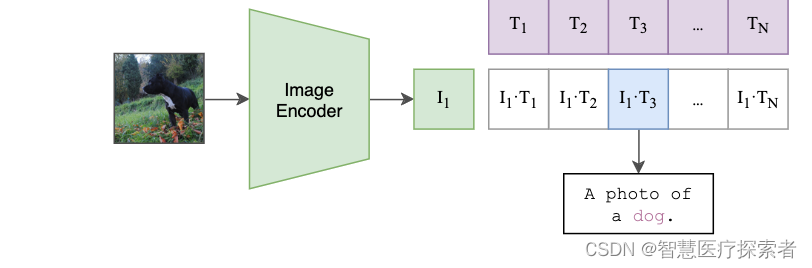
最后就是推理见证效果的时候,怎么做的呢。这个时候无论你来了张什么样的图片,只要扔给 Image Encoder 进行特征提取,会生成一个一维的图片特征向量,然后拿这个图片特征和 1000 个文本特征做余弦相似度对比,最相似的即为我们想要的那个结果,比如这里应该会得到 A photo of a dog.,整个过程如下:
扩展性/泛化能力:上面是拿 ImageNet 那 1000 个类进行展示的,在实际使用中,这个类别文本不限于ImageNet那1000个类,而预测的图片也不限于ImageNet那1.28 万张图片。然而,我依旧可以使用检索相似度的方式去得到输出,这样网络的灵活性就特别高了。不难发现,类别文本提取的特征类似于人脸识别里的检索库,图片提取特征就是待检测的那个。
以上就是 CLIP 工作的总览,可以看到 CLIP 在一次预训练后,可以方便的迁移到其他视觉分类任务上进行 Zero-Shoot 的前向预测。
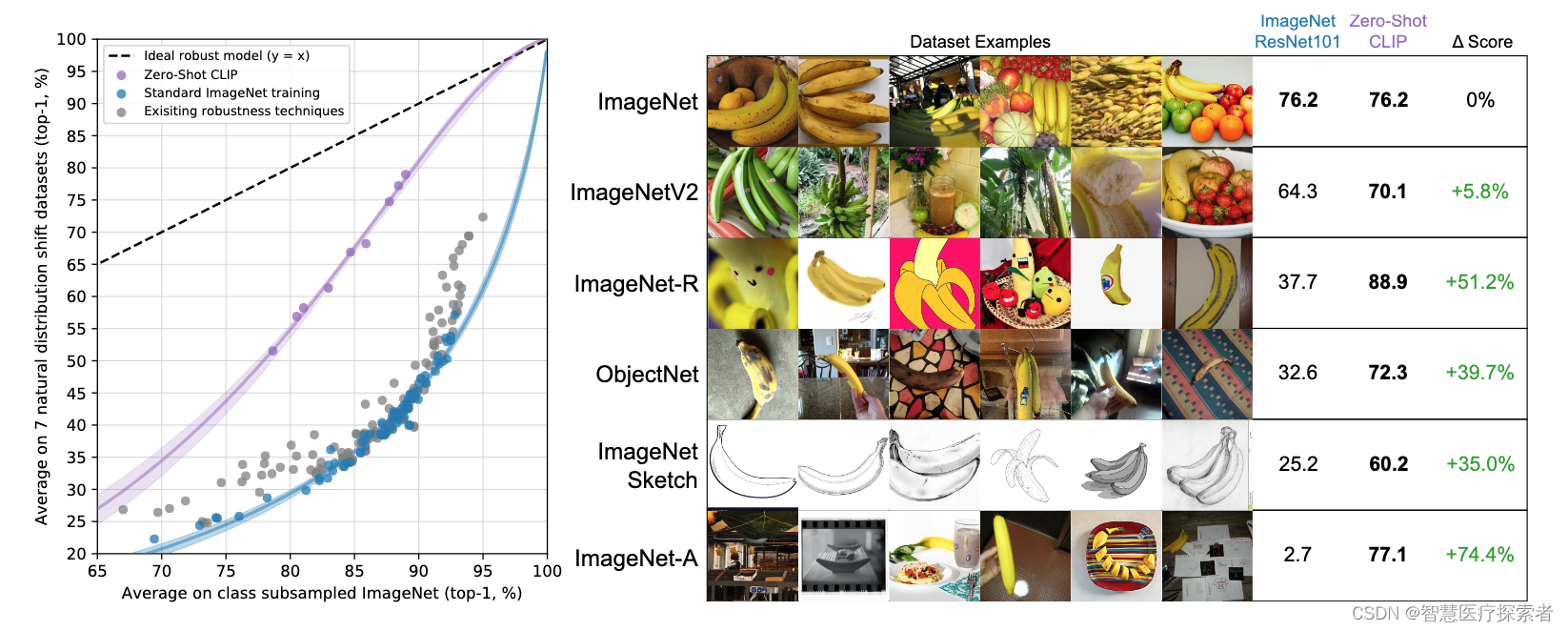
由于CLIP 学习的是文本语义信息,而不是单类别信息,这样做的好处可以体现在迁移能力上。CLIP不仅在ImageNet 常规数据集上表现优秀,对于ImageNet Sketch 素描图、ImageNet-R 动漫图等非常规图像上的迁移学习能力依旧表现的非常好,如下:
看最重要的 Zero-Shoot / Few-Shoot 的能力,主要对比有监督的 Base 网络,涉及的迁移数据集有 27 个之多,可以看到CLIP 的Zero-Shoot 能力十分突出,其中 Linear Probe 的意思是指训练的时候把预训练好的模型权重冻住,直接用其提取特征,然后只是去训练最后的 fc 分类头。
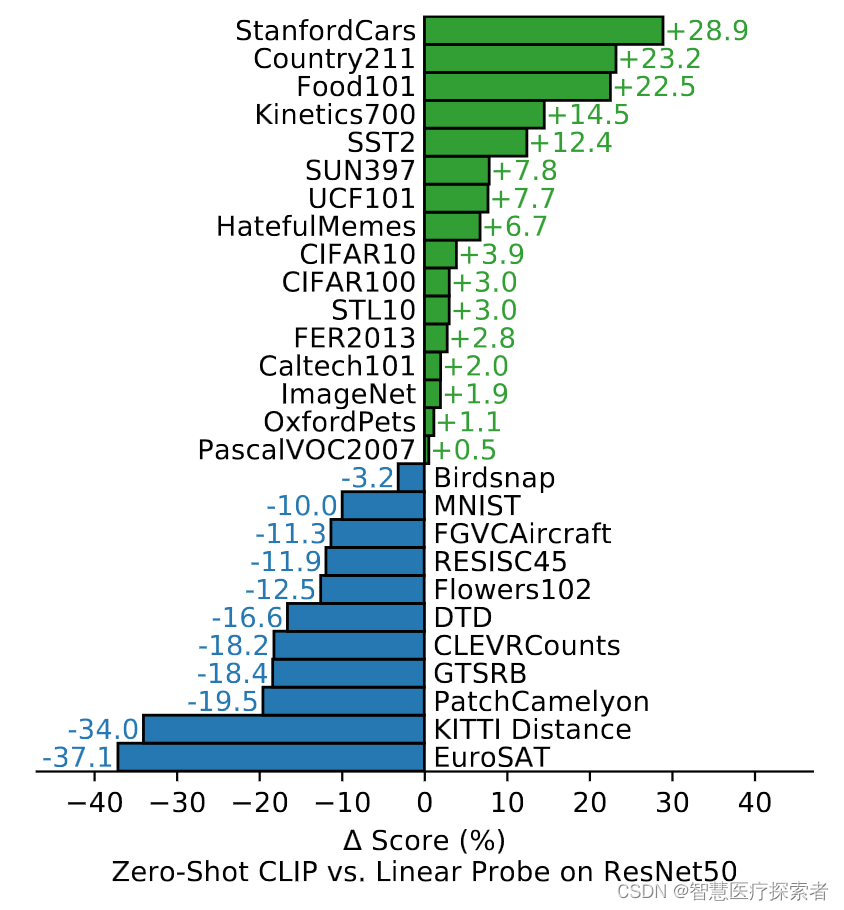
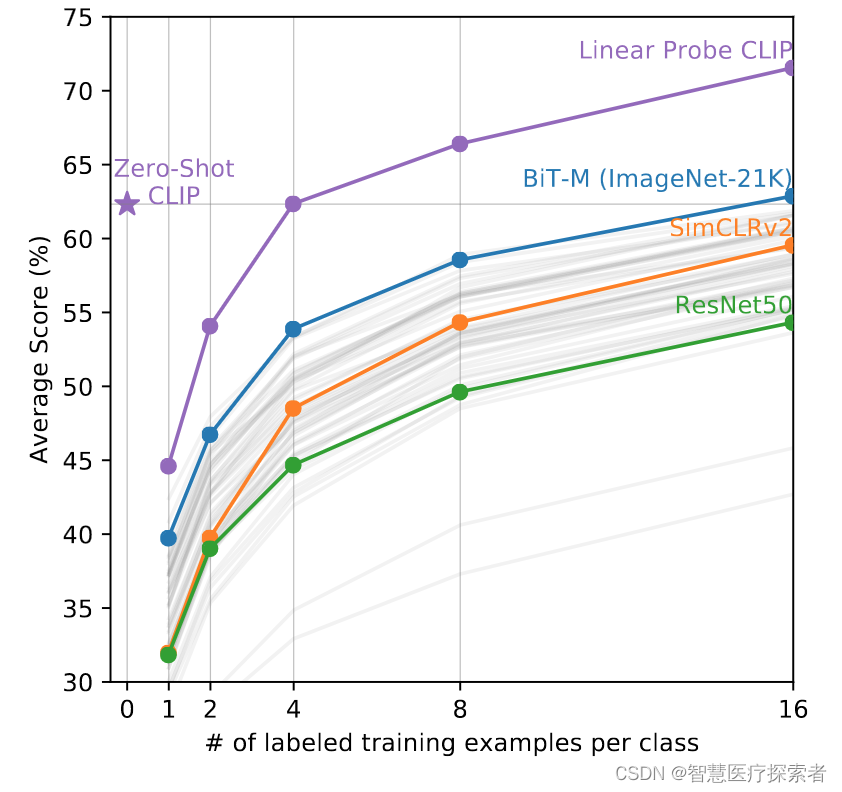
训练过程可视化:
CLIP训练可视化
1.2.4 CLIP训练效果
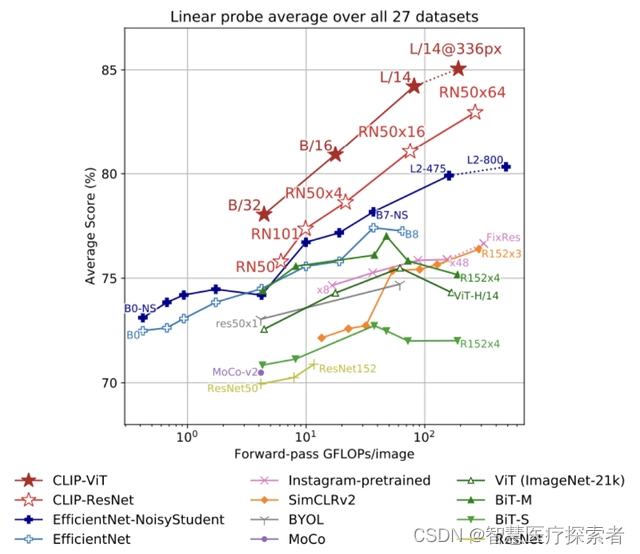
当使用 CLIP 特征训练一个完全监督的线性分类器时,发现它在准确性和计算成本方面都优于许多基线,可以看出 CLIP 通过自然语言监督学习的表示的质量是很高的;
2 Clip模型部署及使用
2.1 conda环境准备
conda环境准备详见:annoconda
2.2 运行环境安装
conda create -n clip python=3.9
activate clip
pip install torch==1.9.0
pip install torchaudio==0.9.0
pip install torchvision==0.10.0
pip install ftfy regex tqdm
pip install git+https://github.com/openai/CLIP.git注意:如果pip install git+https://github.com/openai/CLIP.git失败,使用下面的命令启用代理安装
pip install git+https://ghproxy.com/https://github.com/openai/CLIP.git
2.2 模型下载
文字编码器是transformer,图片编码器测试了各种版本的ResNet(经过Efficientnet最优宽度深度分辨率)和VIT。共训了5个resnet和4个VIT,其中ViT-L/14@336px效果最好。
_MODELS = {
"RN50": "https://openaipublic.azureedge.net/clip/models/afeb0e10f9e5a86da6080e35cf09123aca3b358a0c3e3b6c78a7b63bc04b6762/RN50.pt",
"RN101": "https://openaipublic.azureedge.net/clip/models/8fa8567bab74a42d41c5915025a8e4538c3bdbe8804a470a72f30b0d94fab599/RN101.pt",
"RN50x4": "https://openaipublic.azureedge.net/clip/models/7e526bd135e493cef0776de27d5f42653e6b4c8bf9e0f653bb11773263205fdd/RN50x4.pt",
"RN50x16": "https://openaipublic.azureedge.net/clip/models/52378b407f34354e150460fe41077663dd5b39c54cd0bfd2b27167a4a06ec9aa/RN50x16.pt",
"RN50x64": "https://openaipublic.azureedge.net/clip/models/be1cfb55d75a9666199fb2206c106743da0f6468c9d327f3e0d0a543a9919d9c/RN50x64.pt",
"ViT-B/32": "https://openaipublic.azureedge.net/clip/models/40d365715913c9da98579312b702a82c18be219cc2a73407c4526f58eba950af/ViT-B-32.pt",
"ViT-B/16": "https://openaipublic.azureedge.net/clip/models/5806e77cd80f8b59890b7e101eabd078d9fb84e6937f9e85e4ecb61988df416f/ViT-B-16.pt",
"ViT-L/14": "https://openaipublic.azureedge.net/clip/models/b8cca3fd41ae0c99ba7e8951adf17d267cdb84cd88be6f7c2e0eca1737a03836/ViT-L-14.pt",
"ViT-L/14@336px": "https://openaipublic.azureedge.net/clip/models/3035c92b350959924f9f00213499208652fc7ea050643e8b385c2dac08641f02/ViT-L-14-336px.pt",
}本示例使用ViT-L/14@336px模型,下载完成后,将模型放到/opt/models目录下,显示如下:
-rw-r--r-- 1 root root 934088680 8月 15 19:10 ViT-L-14-336px.pt2.3 使用clip进行编码测试

将以上图片保存到/opt/data目录下
import torch
import clip
from PIL import Image
from torchvision import transforms
class ClipEmbeding:
device = "cuda" if torch.cuda.is_available() else "cpu"
def __init__(self):
self.model, self.processor = clip.load("/opt/models/ViT-L-14-336px.pt", device=self.device)
self.tokenizer = clip.tokenize
def probs(self, image: Image):
process_image = self.processor(image).unsqueeze(0).to(self.device)
text = self.tokenizer(["a diagram", "a dog", "a cat"]).to(self.device)
with torch.no_grad():
logits_per_image, logits_per_text = self.model(process_image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
print("Label probs:", probs)
def embeding(self, image: Image, text: str):
process_image = self.processor(image).unsqueeze(0).to(self.device)
text = self.tokenizer([text]).to(self.device)
image_features = self.model.encode_image(process_image)
text_features = self.model.encode_text(text)
return image_features, text_features
if __name__ == "__main__":
image_path = '/opt/data/cat.jpg'
pil_image = Image.open(image_path)
clip_embeding = ClipEmbeding()
clip_embeding.probs(pil_image)运行结果显示如下:
Label probs: [[1.4230663e-05 1.1715608e-03 9.9881423e-01]]通过结果可知,经过clip模型预测,图片与“a cat”的相似程度最高。
2.4 clip模型Zero-Shot Prediction
import os
import clip
import torch
from torchvision.datasets import CIFAR100
import matplotlib.pyplot as plt
# Load the model
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load('/opt/models/ViT-L-14-336px.pt', device)
# Download the dataset
cifar100 = CIFAR100(root=os.path.expanduser("data"), download=True, train=False)
# Prepare the inputs
image, class_id = cifar100[1000]
image_input = preprocess(image).unsqueeze(0).to(device)
text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device)
plt.imshow(image)
plt.show()
# Calculate features
with torch.no_grad():
image_features = model.encode_image(image_input)
text_features = model.encode_text(text_inputs)
# Pick the top 5 most similar labels for the image
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
values, indices = similarity[0].topk(5)
# Print the result
print("\nTop predictions:\n")
for value, index in zip(values, indices):
print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")输出结果:
Top predictions:
rabbit: 60.15%
shrew: 10.15%
sweet_pepper: 4.02%
porcupine: 2.11%
mouse: 1.50%3 总结
CLIP模型已经在许多视觉和语言任务中展现出惊人的性能,如图像分类、零样本分类、图像生成的指导、图像问答等。它的成功不仅在于其创新的架构,还在于它的预训练策略,使得模型能够从大规模无监督数据中学习到有用的图像和文本表示。