今天我要讲的文章是一篇关于RDMA与Graph Computing结合的一篇论文GraM,发表在2015年CCF B类文章 SoCC。可能时间会有点篇长,为什么我要选用这篇论文,主要是因为我的课题是基于RDMA的亿级图处理系统。这篇文章是首次将远程内存直接访问通信技术RDMA与图计算相结合。这篇文章要解决的问题就是:随着现有的图数据规模增大,单机内存图处理系统已经不能够足以处理这么大规模的图数据。现如今对于图计算真正的需求是处理越来越大的图数据,数千亿乃至数万亿的边。但是随着集群规模的不断扩增,通信成本和集群规模扩展之间存在紧张的关系。因为集群规模的扩增,增加了系统整体的并行性,并且降低了每个线程上的计算成本,因此在同步批量执行模型下(BSP)可能不再有足够的计算去掩盖通信带来的开销。 并行性的增加也可能导致数据碎片化,数据和缓冲区以更细的粒度进行分区,从而降低内存使用效率和通信通道效率,因为更多的机器需要更多的通信通道和内存缓冲来进行跨服务器的通信。在这样的情况下,GraM就是用来解决随着集群规模的增加,系统整体并行性能的增加,导致内存使用效率和通信通道使用效率降低以及一系列开销,造成系统整体处理性能下降的问题。
1.Graph Computation on Large Dataset
同时,图形数据的大小也在不断增加。确实存在真正的图形数据集,其尺度可能具有数百亿甚至数万亿的边。 Google2014年曾报道SoCC关于他们如何计算具有大约400B边的文档相似度图上的连接通量算法。他们在优化的map-reduce框架上执行了计算。最近,Facebook还在博客中报道称,他们使用Giraph在万亿优势的社交图上执行PageRank。没有关于他们使用的图形和服务器配置的详细描述。无论如何,这些数字表明图形引擎支持如此大规模的图形是有意义的和越来越重要的。到目前为止,作者还没有意识到任何已有的已有图形系统已发表的研究能够处理具有万亿条边的图。
- Graphs are prevalent with valuable information
- Graphs keep increasing in size
2.Hardware Trends Shaping Datacenters
3. Issues in Existing Graph Systems
为了去回答这个问题,首先我们来分析一下现有的图处理系统中存在的问题。
1. 现有的图处理系统都很少去考虑图处理效率和可扩展性,具体来说就是高可扩展性可能伴随着较低的效率。2015年McSherry et al在HotOS’15年曾说过,“many published systems have unbounded COST—i.e., no configuration outperforms the best single-threaded implementation”。许多现有已发布的系统具有无限制的COST,即没有配置超过最好的单线程实现。由于扩展集群规模增加了并行性水平并(因此)降低了每个线程上的计算成本,但是扩展集群规模不可避免的增加了通信带来的开销,因此不再有足够的计算来掩盖通信成本。 并行性的增加也可能导致数据碎片化,数据和缓冲区以更细的粒度进行分区,从而降低内存使用效率和通信通道效率。因为更多的机器需要更多的通信通道和内存缓冲来进行跨服务器的通信。
2. 当网络速度快时,效率更重要
4. GraM:An Efficient and Scalable Graph Engine
针对现有的图处理系统,作者提出了一个高效的并且可以弹性伸缩扩展的图处理引擎:GraM。GraM比现有的系统,如Naiad和GraphX提高了一个数量级的性能。GraM能够在内存中处理万亿条边的图数据。比如在万亿条边的图数据中,跑一个PageRan算法一轮迭代140s在64台服务器的集群资源中。近的一项研究表明,一些分布式系统确实以高Cost进行扩展[25],并提出了一种新的度量COST(或者性能优于单线程的配置)来评估系统的效率。 更准确地说,如果图形引擎需要C核才能超过同一图算法的单线程实现,那么图形引擎的代价为C. 相比较于优化后的简单单线程PageRank实现,GraM的Cost只有很少4.也就是说GraM相比较于单线程的实现来说,仅仅只需要4个核就能超过图算法的单线程实现。因为一些分布式系统和多线程程序,程序并行性性能的确会提升,但是由于数据被分区以及线程或者服务器之间的通信也会为系统整体性能带来额外的开销。
GraM优化了在单机多核服务器上高效的计算。并且GraM利用RDMA通信重叠计算和网络通信,通过基于RDMA-based 的通信原语。
- Optimize for single multi-core server efficiency
- Overlapping computation and communication
- Balanced system layer e.g.,comunication stack
5. Overview of GraM Architecture
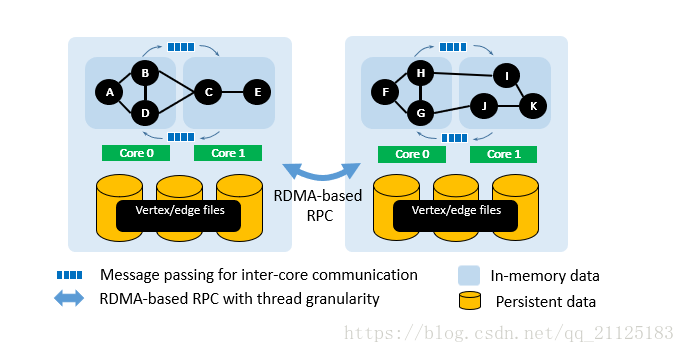
这幅图介绍了RDMA技术整体技术。GRAM的设计是由图计算的特性驱动的:(i)在顶点层次上进行图并行计算,(ii)在每次迭代中内存的随机访问占主导,以及(iii)需要跨越迭代的barrier。 GRAM因此采用简单的扩展体系结构来利用图计算的固有并行性,如图所示。在此体系结构中,每个工作线程都分配给专用的CPU核心并拥有一个图分区。 在计算开始时,所有图分区都被加载到主内存中。 GRAM使用与Grace中使用的数据结构类似的数据结构来布局内存中的图形分区,其中顶点数组包含顶点数据(例如,rank值)和包含由对应源顶点分组的边的边数组。GraM采用的是一种Message-Passing的方式进行数据传递,在两个工作工作线程之间采用CPU core之间的消息通信。在两个服务器之间采用基于RDMA-RPC通信原语进行消息通信。

6.Design Highlights
Message passing rather than shared-memory (even for single server)
2. Overlap computation and communication
Async fast RDMA-based RPC with batching
3. Trade off parallelism and communication efficiency
Adaptive multiplexing
4. NUMA-aware and balanced RDMA communication stack
6.1 Simple model for both scale-up and scale-out
首先,为了横向和纵向扩展集群规模提供了一个简单的模型。 具体来说,无论通信是服务器之间还是服务器内部,我们都采用消息传递而不是共享内存抽象。
6.2 Overlap computation and communication
GraM使用的基于异步RDMA的通信层与批量发送消息相结合,使在执行图计算负载期间能够完美地重叠计算和通信。
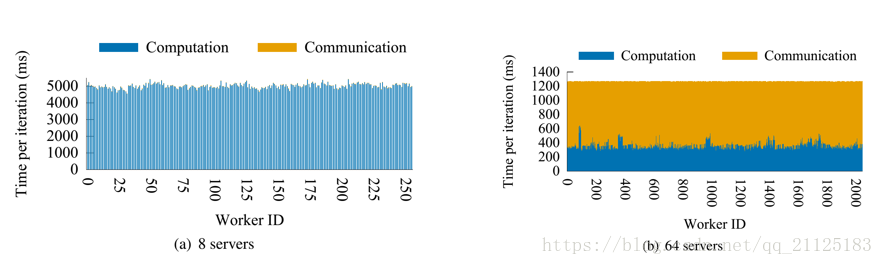
本图中显示了在具有不同数量的服务器的uk-union图上运行PageRank时。 x轴是全局分配给所有服务器上所有线程的工作者ID,服务器0上的工作人员0〜31,服务器1上的工作人员32〜63等等。 y轴是一个PageRank迭代的执行时间,以毫秒为单位。我们将执行时间分为两个阶段:计算阶段和非重叠通信阶段。在计算阶段,如深蓝色条所示,工作人员枚举顶点和边,准备要传播给邻居的数据,并处理从其他工作人员收到的消息。这个阶段的通信部分与计算重叠。浅黄色条表示工人在工作阶段之后的非重叠通信阶段。这一阶段的操作包括将剩余的消息放入缓冲区并接收其他工作人员发送的消息(如果有剩余的话)。
图(a)显示了8台服务器上的图形计算几乎完全掩盖了通信。淡黄色的条纹几乎不可见,这意味着通信在计算后立即完成。但是,这种理想的重叠并不总是能够实现的,特别是当工作人员所拥有的图形分区的大小太小时:由于碎片化导致的数据通信变得效率低下,并且没有足够的计算来隐藏通信成本。图(b)显示了这种情况。使用64台服务器时,通信阶段占用的总时间要比8服务器案例中的占很大的一部分。如图(b)所示。当计算时间落入亚秒时,随着并行性的增加可能导致数据碎片化,数据和缓冲区以更细的粒度进行分区,从而降低内存使用效率和通信通道效率。因为更多的机器需要更多的通信通道和内存缓冲来进行跨服务器的通信。由于并行性的增加,每个线程的计算量减少,线程之间交换的消息相对变少(线程的数量增加),从而导致网络效率降低。,因此很难利用批量发送消息,这导致重叠和整体性能更差。所以当每个Worker的工作人员所拥有的分区太小时,这个时候就需要一些其他的优化机制。
6.3 Trade off parallelism and communication efficiency
为了解决这个问题,作者采用了一些机制来交换并行性以提高通信效率。

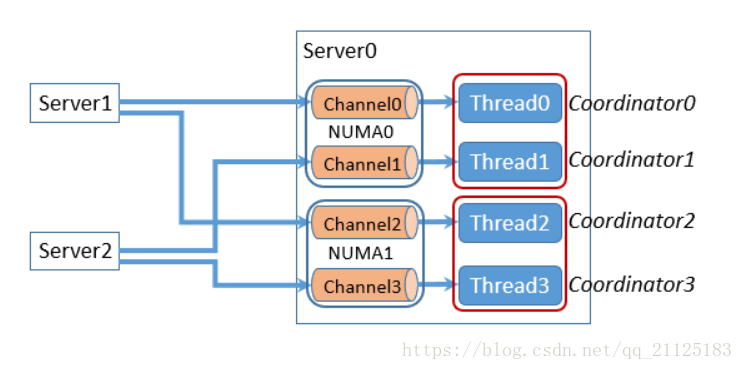
数据发送方通过RDMA请求将数据发送到接收方服务器管道环形缓冲区的尾部, 接收端的协调器轮询接收缓冲区。 当有新消息时,它会查看消息的Header,以确定该消息适用于哪个线程。然后通知相应的线程,相应的工作现场根据缓冲区中消息的偏移量和大小直接从接收缓冲区读取消息。 消息完成后,线程通知协调器接收器缓冲区中的缓冲区可以重新使用。

这种方式充分利用了RDMA线程粒度的通信。

RPC接收方不需要额外的协调或解复用,每个接收线程独立地处理在接收缓冲区中发送给它的消息,从而最大限度地提高并行性。当有足够的并行计算可以保持所有CPU 核繁忙时,这样的每一个对等线程发送器缓冲器设计效果最佳,同时隐藏了通信成本。但是随着并行性的增加可能导致数据碎片化,数据和缓冲区以更细的粒度进行分区,从而降低内存使用效率和通信通道效率。因为更多的机器需要更多的通信通道和内存缓冲来进行跨服务器的通信。由于并行性的增加每个通道中发送消息的数量较少,因此很难利用批量发送消息,这导致重叠和整体性能更差。
因此,GraM引入了一种不同的设置,通过将一个线程的所有发送方缓冲区合并发送到同一远程服务器上例如:,一个对等服务器的缓冲区安排)。在这个方案中,RPC是在粗粒度的情况下进行的,以更好的批量发送消息。合并的缓冲区被发送到远程服务器中的一个委托线程,该线程通过线程消息传递将消息分解多路分发给适当的线程。

图中显示了具有不同数量的服务器和不同图应用程序的两种方案的性能比较。首先,当所使用的服务器数量很少时,每个对等线程缓冲区布置(表示为每对线程之间通信)的性能会更好,因为在计算成本占主导地位的有效配置中有利于并行性是正确的选择,并且可以在并行性的水平。当服务器数量增加到8个或更多时,每个线程的计算量减少,线程之间交换的消息相对变少(线程的数量增加),从而导致网络效率降低。在这些情况下,支持通信效率的每对等服务器缓冲区方案(表示为分派)开始表现出色,因为它将消息分批发送到同一远程服务器的所有线程。批量发送消息的好处超过了将消息重新分配给目标线程的额外开销。
6.4 NUMA-aware and balanced RDMA communication stack
6.4.1 NUMA-aware
最后,GraM在图形数据和网络通信缓冲区上应用NUMA感知的内存分配。 这使得计算的工作量更加平衡。 通过应用这个,我们观察到了40%的性能提升。
具体来说:
1. 对于图数据,GRAM保证线程拥有的图分区从与线程专用的core相同的NUMA节点上分配。
2. GraM始终确保接收器缓冲区与接收线程位于同一个NUMA节点上,因为那些接收线程将访问缓冲区。
6.4.2 Balanced RDMA communication stack
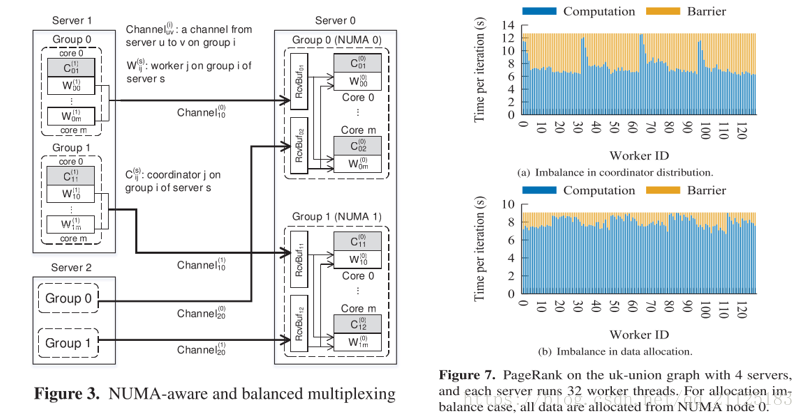
我们在所有4台服务器上显示每个线程(共32×4)的行为,并将执行时间分为两个阶段:计算和Barrier,其中Barrier阶段是指工人花费在屏障上等待。在这种配置中,有3个发送者/接收者通道,每个服务器上的前三个线程充当协调者:协调者的工作者ID是0〜2,32〜34,64〜66和96〜98,分别。如图所示,担任协调员的工作人员在计算阶段花费的时间比其他人长,而其他进入障碍阶段的工作人员则要等待这些工作人员。为了缓解这个问题,我们在每个服务器中引入8个组,每组3个发送者/接收者通道。然后每个服务器有24个发送者/接收者协调器分布在32个核心中。这大致平衡了负载。
7.总结
- A new scalable distributed computation substrate that offers orders of magnitude improvement on efficiency.
- Capable of processing trillion-edge graph efficiently in memory, which are significantly larger than previously published result.