一、容器
1.介绍
PowerJob 的容器技术允许开发者开发独立于 Worker 项目之外 Java 处理器,简单来说,就是以 Maven 工程项目的维度去组织一堆 Java 文件(开发者开发的众多脚本处理器),进而兼具开发效率和可维护性。
该容器为 JVM 级容器,而不是操作系统级容器(Docker)。
2.用途举例
●比如,突然出现了某个数据库数据清理任务,与主业务无关,写进原本的项目工程中不太优雅,这时候就可以单独创建一个用于数据操作的容器,在里面完成处理器的开发,通过 PowerJob 的容器部署技术在 Worker 集群上被加载执行。
●比如,常见的日志清理啊,机器状态上报啊,对于广大 Java 程序员来说,也许并不是很会写 shell 脚本,此时也可以借用 agent+容器 技术,利用 Java 完成各项原本需要通过脚本进行的操作。
(感觉例子举的都不是很好…这个东西嘛,只可意会不可言传,大家努力理解一下吧~超好用哦~)
二、OpenAPI
OpenAPI 允许开发者通过接口来完成手工的操作,让系统整体变得更加灵活。开发者可以基于 API 便捷地扩展PowerJob 原有的功能,比如,全面定制自己的任务调度策略。
换句话说,通过 OpenAPI,可以让接入方自己实现 PowerJob 的整个任务管理与调度模块。
1.依赖
最新依赖版本请参考 Maven 中央仓库:推荐地址 & 备用地址。
<dependency>
<groupId>tech.powerjob</groupId>
<artifactId>powerjob-client</artifactId>
<version>${latest.powerjob.version}</version>
</dependency>
2.简单示例
通过 OpenAPI 停止某个任务实例。
// 初始化 client,需要server地址和应用名称作为参数
PowerJobClient client = new PowerJobClient("127.0.0.1:7700", "oms-test", "password");
// 调用相关的API
client.stopInstance(1586855173043L)
三、工作流(workflow)
1.什么是工作流?
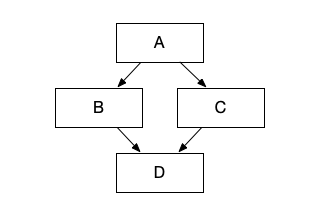
工作流描述了任务与任务之间的依赖关系,比如我现在有 A、B、C、D 四个任务,我希望 A 任务运行完毕后才开始运行 B、C 任务,最后再运行 D 任务。这就形成了一个依赖关系,可以通过有向无环图(DAG)来描述这个关系,如下图所示。
四、处理器
对于一些通用的任务,PowerJob 官方编写了可开箱即用的 Processor 来方便各位使用!您只需要引入以下依赖即可享受所有现成的强大的官方处理器!
最新版本请自行从中央仓库获取:点击直达
<dependency>
<groupId>tech.powerjob</groupId>
<artifactId>powerjob-official-processors</artifactId>
<version>${latest.version}</version>
</dependency>
每个官方处理器的详细使用方法请仔细阅读文档,有任何疑惑建议直接阅读源码!
由于 JSON 内传递许多参数涉及到转义,强烈建议先用 Java 代码生成配置(JSONObject#put),再调用 toJSONString 方法生成参数。
1. Shell 处理器
全限定类名 tech.powerjob.official.processors.impl.script.ShellProcessor
任务参数:填写需要处理的 Shell 脚本(直接复制文件内容)或脚本下载链接(http://xxx)
2.Python 处理器
全限定类名 tech.powerjob.official.processors.impl.script.PythonProcessor
注意:Python 处理器会使用机器的 python 命令执行,因此 python 版本需要与本机 python 环境保持一致!
任务参数:填写需要处理的 Python 脚本(直接复制文件内容)或脚本下载链接(http://xxx)
3.HTTP 处理器
全限定类名 tech.powerjob.official.processors.impl.HttpProcessor
任务参数(JSON):
- method【必填字段】:GET / POST / DELETE / PUT
- url【必填字段】:请求地址
- timeout【可选字段】:超时时间,单位为秒
- mediaType【可选字段】:使用非 GET 请求时,需要传递的数据类型,如
*application/json* - body【可选字段】:使用非 GET 请求时的 body 内容,后端使用 String 接收,如果为 JSON 请注意转义
- headers【可选字段】:请求头,后端使用 Map<String, String> 接收
4.文件清理处理器
**注意:文件删除是高危操作,请慎用该处理器。**默认情况下该处理器不可用,需要传入 JVM 参数
-Dpowerjob.official-processor.file-cleanup.enable=true 开启
全限定类名 tech.powerjob.official.processors.impl.FileCleanupProcessor
任务参数(JSONArray):整体参数为 array,array 中的每个元素为 JSON,描述需要清理的资源,每个节点的参数如下:
- dirPath:待删除文件的文件夹目录(会递归查找该目录下所有符合要求的文件)
- filePattern:待删除文件名称的 Java 版正则表达式
- retentionTime:待删除文件的保留时间,单位为小时(当前时间 - 待删除文件上次编辑时间 > retentionTime 的文件才会被删除),用于保留某些滚动日志,0 代表忽略该规则
由于 JSON 内传递正则表达式需要转义,强烈建议先用 Java 代码生成配置(JSONObject#put, JSONArray#add),再调用 toJSONString 方法生成参数。
5.SQL 处理器
目前内置了两款 SQL 处理器,均支持自定义 SQL 的校验、解析逻辑,主要区别在于数据源连接的获取方式不同。
任务参数(JSON)
- dataSourceName:数据源名称,仅对
SpringDatasourceSqlProcesssor生效,非必填,默认使用default数据源 - sql:需要执行的 SQL 语句,必填
- timeout:SQL 超时时间(秒),非必填,默认值 60
- jdbcUrl:jdbc 数据库连接,仅对
DynamicDatasourceSqlProcessor生效,必填 - showResult:布尔值,是否在实例日志中展示 SQL 执行结果,非必填,默认值 false
建议生产环境使用 AbstractSqlProcessor#registerSqlValidator 方法至少注册一个 SQL 校验器拦截掉非法 SQL,比如 truncate、drop 此类危险操作,或者在数据库账号的权限上做管控。如果需要自定义 SQL 解析逻辑,比如 宏变量替换,参数替换 等,则可以通过指定 AbstractSqlProcessor.SqlParser 来实现。
5.1 SpringDatasourceSqlProcessor
全限定类名 tech.powerjob.official.processors.impl.sql.SpringDatasourceSqlProcessor
默认情况下在初始化的时候需要至少注入一个数据源,所以必须提前手动初始化并注册到 Spring IOC 容器中,以 SpringBean 的方式进行加载。
允许使用 SpringDatasourceSqlProcessor#registerDataSource 方法注册多个数据源
建议:最好将该 SQL Processor 用的数据库连接池和其他业务模块用的数据库连接池隔离开**,不要共用一个连接池!**
5.2DynamicDatasourceSqlProcessor
默认情况下该处理器不可用,需要传入 JVM 参数 -Dpowerjob.official-processor.dynamic-datasource.enable=true 开启
全限定类名 tech.powerjob.official.processors.impl.sql.DynamicDatasourceSqlProcessor
支持通过参数动态指定数据源连接,在指定的数据库执行 SQL。
6.工作流上下文注入处理器
全限定类名 tech.powerjob.official.processors.impl.context.InjectWorkflowContextProcessor ( since v1.2.0 )
该处理器会从任务参数中加载数据,尝试将其解析成 Map ,如果解析成功,则会将其注入到工作流上下文中。
注意,参数必须是一个HashMap<String, Object>的 JSON 串形式,否则会解析失败。
注意:该 Processor 主要用于一些需要注入固定上下文的工作流场景,作为单个任务执行是没有任何意义的