前言
学过大模型的都知道,PEFT 方法仅微调少量(额外)模型参数,同时冻结预训练 LLM 的大部分参数,比如Prefix Tuning、P-Tuning V1/V2、LoRA、QLoRA,其实网上介绍这些微调方法的文章/教程不少了,我也看过不少,但真正写的一目了然、一看就懂的还是少,大部分文章/教程差点意思
总之,把知识写清楚、讲清楚并不容易,比如“把知识写清楚”的这个能力 我从2010年起,算练了10多年了,如今依然热衷于把知识真正写清晰化,加之今年一直在不断深入大模型相关的技术,写了各种模型的微调,但之前还没好好总结过各类微调方法,而微调方法很重要,故成此文
第一部分 高效参数微调的发展史
1.1 Google之Adapter Tuning:嵌入在transformer里 原有参数不变 只微调新增的Adapter
谷歌的研究人员于2019年在论文《Parameter-Efficient Transfer Learning for NLP》提出针对 BERT 的 PEFT 微调方式,拉开了 PEFT 研究的序幕。他们指出
- 在面对特定的下游任务时,如果进行 Full-fintuning(即预训练模型中的所有参数都进行微调),太过低效
- 而如果采用固定预训练模型的某些层,只微调接近下游任务的那几层参数,又难以达到较好的效果
于是他们设计了如下图所示的 Adapter 结构
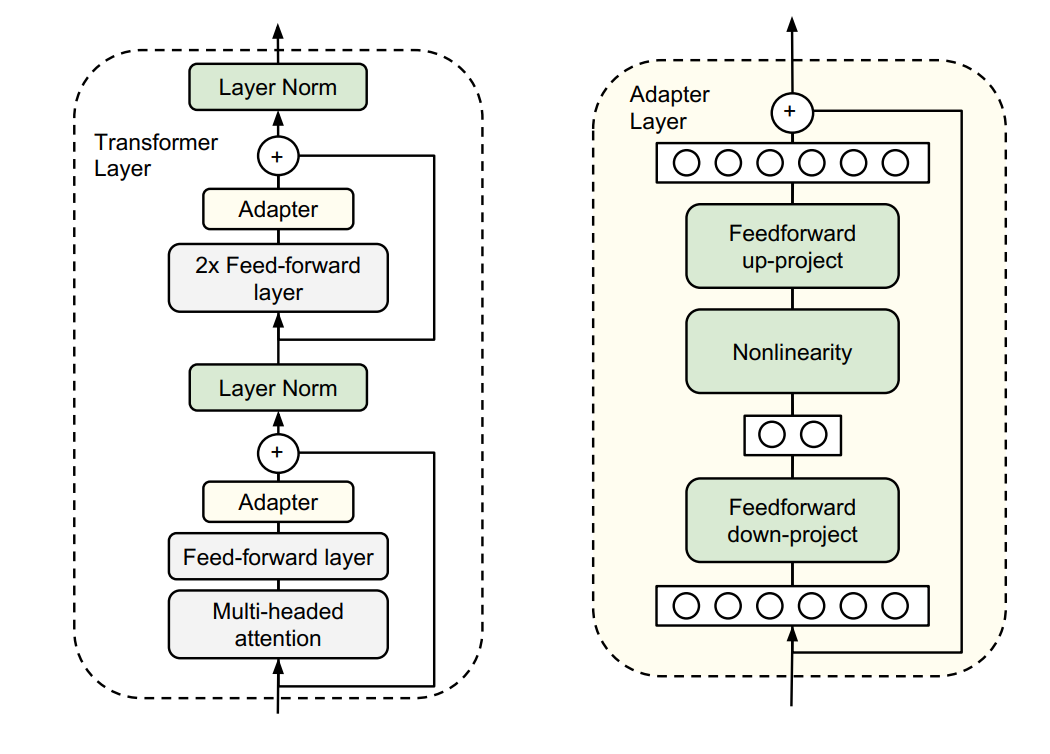
- 如上图左侧所示,将其嵌入 Transformer 的结构里面,在训练时,固定住原来预训练模型的参数不变,只对新增的 Adapter 结构进行微调
- 如上图右侧所示,同时为了保证训练的高效性(也就是尽可能少的引入更多参数),他们将 Adapter 设计为这样的结构:首先是一个 down-project 层将高维度特征映射到低维特征,然后过一个非线形层之后,再用一个 up-project 结构将低维特征映射回原来的高维特征;同时也设计了 skip-connection 结构,确保了在最差的情况下能够退化为 identity
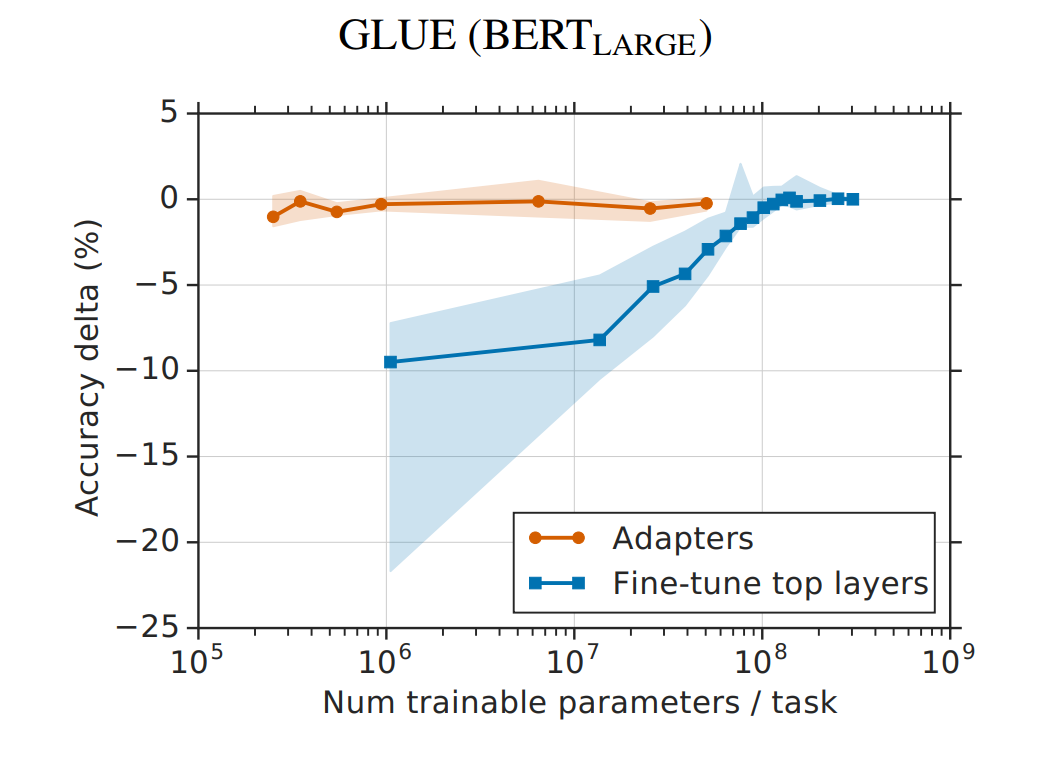
从实验结果来看,该方法能够在只额外对增加的3.6%参数规模(相比原来预训练模型的参数量)的情况下取得和Full-finetuning接近的效果(GLUE指标在0.4%以内)
1.2 斯坦福之Prefix Tuning
在prefix-tuning之前的工作主要是人工设计离散的template或者自动化搜索离散template,问题在于最终的性能对人工设计的template的特别敏感:加一个词或者少一个词,或者变动位置,都会造成很大的变化,所以这种离散化的token的搜索出来的结果可能并不是最优的
因此斯坦福的研究人员通过此论文《Prefix-Tuning:Optimizing Continuous Prompts for Generation》提出Prefix Tuning方法,其使用连续的virtual token embedding来代替离散的token,且与Full-finetuning更新所有参数的方式不同,如下图所示(注意体会图中fine-tuning与prefix tuning的区别)

- 该方法是在输入token之前构造一段任务相关的virtual tokens作为Prefix 「相当于对于transformer的每一层(注意不是只有输入层,目的增加可训练参数),都在真实的句子表征前面插入若干个连续的可训练的"virtual token" embedding,这些伪token不必是词表中真实的词,而只是若干个可调的自由参数」
为了形象说明,举个例子,对于table-to-text任务,context是序列化的表格,输出
是表格的文本描述,使用GPT-2进行生成;对于文本摘要,
对于自回归(Autoregressive)模型,在句子前面添加前缀,得到
这是因为合适的上文能够在fixed LM的情况下去引导生成下文(比如GPT3的 in-context learning)
这是因为Encoder端增加前缀是为了引导输入部分的编码 (guiding what to extract from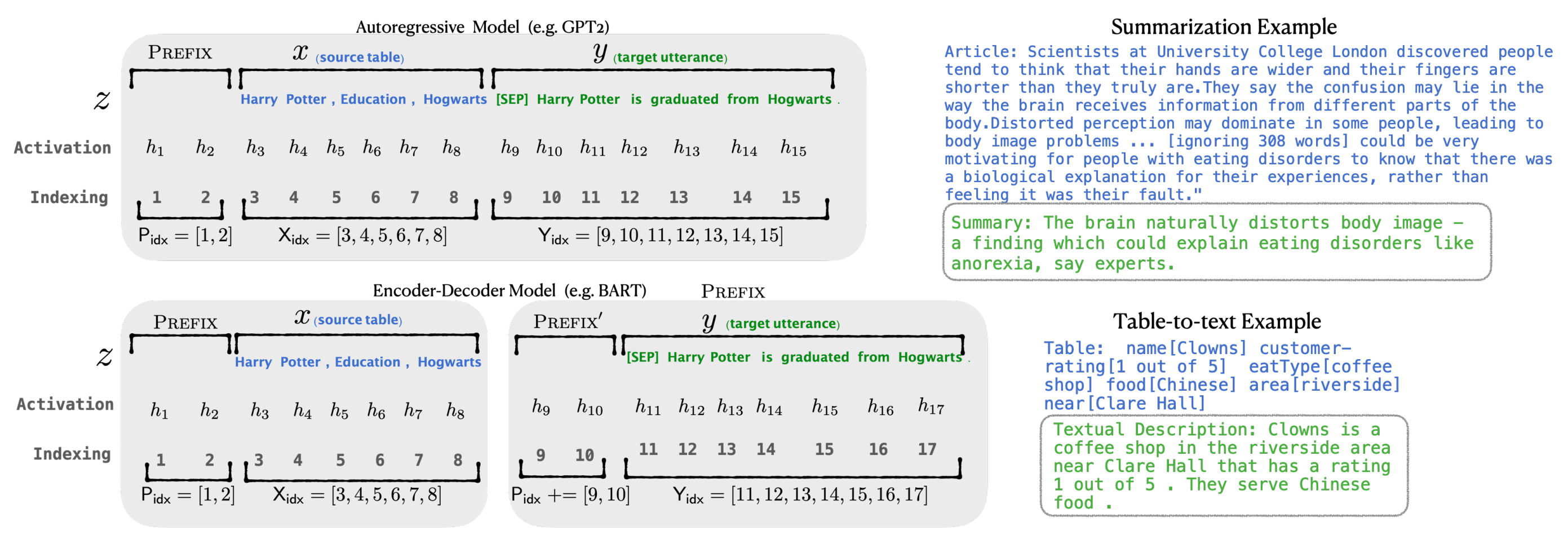
- 然后训练的时候只更新Prefix部分的参数,而Transformer中的其他部分参数固定
该方法其实和构造Prompt类似,只是Prompt是人为构造的“显式”的提示,并且无法更新参数,而Prefix则是可以学习的“隐式”的提示
同时,为了防止直接更新Prefix的参数导致训练不稳定的情况,他们在Prefix层前面加了MLP结构(相当于将Prefix分解为更小维度的Input与MLP的组合后输出的结果),训练完成后,只保留Prefix的参数
第二部分 P-Tuning V1/V2
2.1 P-Tuning V1
// 待更
2.2 P-Tuning V2:其关键所在在于引入Prefix-tuning
// 待更
第三部分 LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
3.1 什么是LoRA
如此文《LLaMA的解读与其微调:Alpaca-LoRA/Vicuna/BELLE/中文LLaMA/姜子牙/LLaMA 2》中的2.2.3节Alpaca-LoRA:通过PEFT库在消费级GPU上微调「基于LLaMA的Alpaca」所述,在神经网络模型中,模型参数通常以矩阵的形式表示。对于一个预训练好的模型,其参数矩阵已经包含了很多有用的信息。为了使模型适应特定任务,我们需要对这些参数进行微调
LoRA的核心思想是用一种低秩的方式来调整这些参数矩阵。在数学上,低秩意味着一个矩阵可以用两个较小的矩阵相乘来近似,通过论文《LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS》可知
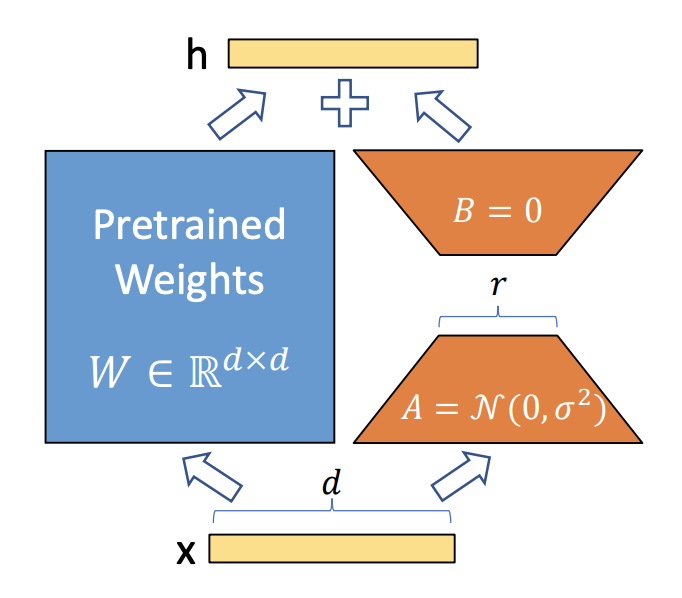
- 选择目标层:首先,在预训练神经网络模型中选择要应用LoRA的目标层。这些层通常是与特定任务相关的,如自注意力机制中的查询Q和键K矩阵
- 初始化映射矩阵和逆映射矩阵:为目标层创建两个较小的矩阵A和B
其中,矩阵的大小由LoRA的秩(rank)和alpha值确定 - 参数变换:将目标层的原始参数矩阵W通过映射矩阵A和逆映射矩阵B进行变换。计算公式为:
,这里W'是变换后的参数矩阵
- 微调模型:使用新的参数矩阵
替换目标层的原始参数矩阵
,然后在特定任务的训练数据上对模型进行微调
- 梯度更新:在微调过程中,计算损失函数关于映射矩阵A和逆映射矩阵B的梯度,并使用优化算法(如Adam、SGD等)对A和B进行更新
注意,在更新过程中,原始参数矩阵W保持不变,说白了,训练的时候固定原始PLM的参数,只训练降维矩阵A与升维矩阵B - 重复更新:在训练的每个批次中,重复步骤3-5,直到达到预定的训练轮次(epoch)或满足收敛条件
总之,LoRA的详细步骤包括选择目标层、初始化映射矩阵和逆映射矩阵、进行参数变换和模型微调。在微调过程中,模型会通过更新映射矩阵U和逆映射矩阵V来学习特定任务的知识,从而提高模型在该任务上的性能
3.2 微软DeepSpeed-Chat中对LoRA微调的实现
继续说一下,这个LoRA的应用还是挺广的,比如后续微软推出的DeepSpeed-Chat便用了这个方法
DeepSpeed-Chat的实现中,当设置LoRA的低秩维度lora_dim(如lora_dim=128)时,即认为启用了LoRA训练,则将原始模型中名称含有“deoder.layers.”且为线性层修改为LoRA层,具体操作为:
- 将原始结构的weight参数冻结;
- 新引入了2个线性层lora_right_weight和lora_left_weight (分别对应上图中的降维矩阵A、升维矩阵B ),可实现先降维至lora_dim再升维回原维度;
- LoRA层主要实现了两分支通路,一条分支为已被冻结weight参数的原始结构、另一条分支为新引入的降维再升维线性层组
# applications/DeepSpeed-Chat/training/step1_supervised_finetuning/main.py # 判断是否启用LoRA模式 if args.lora_dim > 0: """ 如果启用,则对名称中含有“decoder.layers.”且为线性层的结构部分引入LoRA旁路(实现先降维后升维的2个线性层), 这类结构基本都是attention、信息交互用的inner线性层, 这类结构的Weight参数将被冻结,转而优化LoRA旁路的参数。 """ args.lora_module_name = "decoder.layers." model = convert_linear_layer_to_lora(model, args.lora_module_name, args.lora_dim) # applications/DeepSpeed-Chat/training/utils/module/lora.py def convert_linear_layer_to_lora(model, part_module_name, lora_dim=0, lora_scaling=1, lora_droppout=0): """ 将名称中带有"decoder.layers."的线性层转换为lora层 """ """取出模型中参数名含有decoder.layers.的线性层""" repalce_name = [] for name, module in model.named_modules(): if isinstance(module, nn.Linear) and part_module_name in name: repalce_name.append(name) for name in repalce_name: """recursive_getattr实现了从model中根据属性名取出对应原始结构""" module = recursive_getattr(model, name) """纳入原始结构的参数,实例化lora层""" tmp = LinearLayer_LoRA( module.weight, lora_dim, lora_scaling, lora_droppout, module.bias).to(module.weight.device).to(module.weight.dtype) """recursive_getattr实现了将model对应属性的结构换成lora层实例""" recursive_setattr(model, name, tmp) return model # applications/DeepSpeed-Chat/training/utils/module/lora.py class LinearLayer_LoRA(nn.Module): """具体的lora层""" def __init__(...): ... """此处的weight和bias即为原始结构中的参数""" self.weight = weight self.bias = bias ··· """冻结weight部分的参数""" self.weight.requires_grad = False ··· self.lora_right_weight = nn.Parameter(torch.zeros(columns, lora_dim)) self.lora_left_weight = nn.Parameter(torch.zeros(lora_dim, rows)) ... """初始化LoRA线性层的参数""" self.reset_parameters() # 调用reset_parameters(self)做初始化 def reset_parameters(self): # 降维矩阵与LoRA原始定义所用的(0,\sigma^2)正态分布初始化不同,而是使用的kaiming均匀分布初始化 # kaiming服从均匀分布U(-\sqrt{1/in_feature}, +\sqrt{1/in_feature}) # f_i是矩阵的输入维度,就是nn.Linear(in_features, out_features)中的in_features # 对应上面代码中的columns,而这个columns相当于基座模型的hidden_size nn.init.kaiming_uniform_(self.lora_right_weight, a=math.sqrt(5)) # 升维矩阵使用全0初始化 nn.init.zeros_(self.lora_left_weight) def forward(self, input): """LoRA的正向传播""" ··· else: # F.linear(input, self.weight, self.bias)是使用给定的权重self.weight和偏差self.bias对输入数据input进行线性变换 # 这个操作等价于input @ self.weight.t() + self.bias,其中@表示矩阵乘法,.t()表示矩阵转置 return F.linear(input, self.weight, self.bias) # 1,self.lora_dropout(input)对输入进行了随机的dropout操作,这是一种正则化手段 # 2,对结果进行两次线性变换,一次是@ self.lora_right_weight,然后是@ self.lora_left_weight # 3,乘法部分* self.lora_scaling是对加号后面部分的结果进行缩放 + (self.lora_dropout(input) @ self.lora_right_weight @ self.lora_left_weight) * self.lora_scaling
再额外分析下 这段代码的最后部分
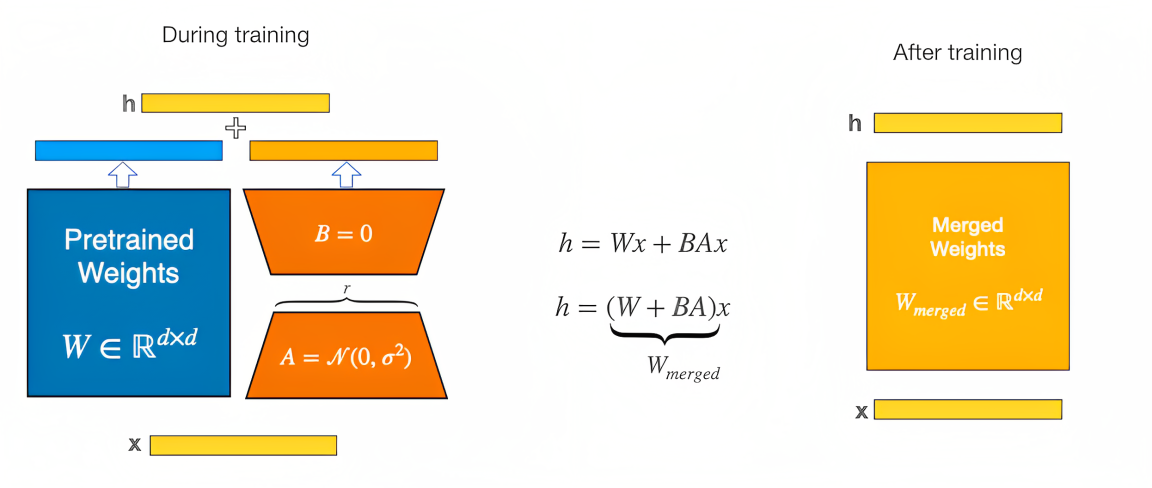
# applications/DeepSpeed-Chat/training/utils/module/lora.py class LinearLayer_LoRA(nn.Module): """具体的lora层""" ··· def forward(self, input): """LoRA的正向传播""" ··· else: return F.linear( input, self.weight, self.bias) + (self.lora_dropout(input) @ self.lora_right_weight @ self.lora_left_weight) * self.lora_scaling常规部分的正向传播由transformers所定义,而LoRA部分的正向传播则由LinearLayer_LoRA(nn.Module)的forward()所定义,即“LoRA层的两条分支结果进行加和”,如下图所示『图源:LoRA,相当于在训练期间,较小的权重矩阵(下图中的A和B)是分开的,但一旦训练完成,权重可以合并到一个新权重矩阵中 』
在代码中体现为
F.linear(input, self.weight, self.bias) + (self.lora_dropout(input) @ self.lora_right_weight @ self.lora_left_weight) * self.lora_scaling加号左侧为原结构支路,加号右侧为新增支路,self.lora_right_weight 和self.lora_left_weight 分别为两个新引入线性层的参数
3.3 Huggingface上PEFT库对LoRA、Prefix Tuning、P-Tuning的封装
而Huggingface公司推出的PEFT(Parameter-Efficient Fine-Tuning,即高效参数微调之意) 库也封装了LoRA这个方法,PEFT库可以使预训练语言模型高效适应各种下游任务,而无需微调模型的所有参数,即仅微调少量(额外)模型参数,从而大大降低了计算和存储成本
| Model | Full Finetuning | PEFT-LoRA PyTorch | PEFT-LoRA DeepSpeed with CPU Offloading |
|---|---|---|---|
| bigscience/T0_3B (3B params) | 47.14GB GPU / 2.96GB CPU | 14.4GB GPU / 2.96GB CPU | 9.8GB GPU / 17.8GB CPU |
| bigscience/mt0-xxl (12B params) | OOM GPU | 56GB GPU / 3GB CPU | 22GB GPU / 52GB CPU |
| bigscience/bloomz-7b1 (7B params) | OOM GPU | 32GB GPU / 3.8GB CPU | 18.1GB GPU / 35GB CPU |
且PEFT库 (peft/src/peft/peft_model.py at main · huggingface/peft · GitHub)支持以下流行的方法
- LoRA,PEFT对LoRA的实现封装见:peft/src/peft/tuners/lora.py at main · huggingface/peft · GitHub,比如对权重的合并代码 (和上面DSC对LoRA权重合并的实现,在本质上是一致的)
def merge(self): # 检查当前激活的适配器是否在lora_A的键中,如果不在则终止函数 if self.active_adapter not in self.lora_A.keys(): return if self.merged: warnings.warn("Already merged. Nothing to do.") return # 如果激活适配器的r值大于0,表示有可以合并的权重 if self.r[self.active_adapter] > 0: # 在当前的权重上加上计算得到的新权重 self.weight.data += ( # 转置运算 transpose( # 通过矩阵乘法计算新的权重 self.lora_B[self.active_adapter].weight @ self.lora_A[self.active_adapter].weight, # 这是转置运算的维度参数 self.fan_in_fan_out, ) # 然后将计算得到的权重乘以对应的缩放因子 * self.scaling[self.active_adapter] ) self.merged = True - Prefix Tuning: Prefix-Tuning: Optimizing Continuous Prompts for Generation, P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
- P-Tuning: GPT Understands, Too
- Prompt Tuning: The Power of Scale for Parameter-Efficient Prompt Tuning
第四部分 QLoRA
// 待更
参考文献与推荐阅读
- Google关于Adapter Tuning的论文《Parameter-Efficient Transfer Learning for NLP》
- 让天下没有难Tuning的大模型-PEFT技术简介
- PEFT:在低资源硬件上对十亿规模模型进行参数高效微调
- 连续型prompt: Prefix-Tuning
- LLaMA的解读与其微调:Alpaca-LoRA/Vicuna/BELLE/中文LLaMA/姜子牙/LLaMA 2
- P-Tuning v2大幅提升小模型性能,NER也可promp tuning了
- P-tuning:自动构建模版,释放语言模型潜能
- Prompt-Tuning——深度解读一种新的微调范式
- ..