P60-P64的学习目录如下,
x.1 TF网络模型实现

以一个简单的TF的分类网络为例,将模型翻译成框架下的语义,即如右侧所表达的。
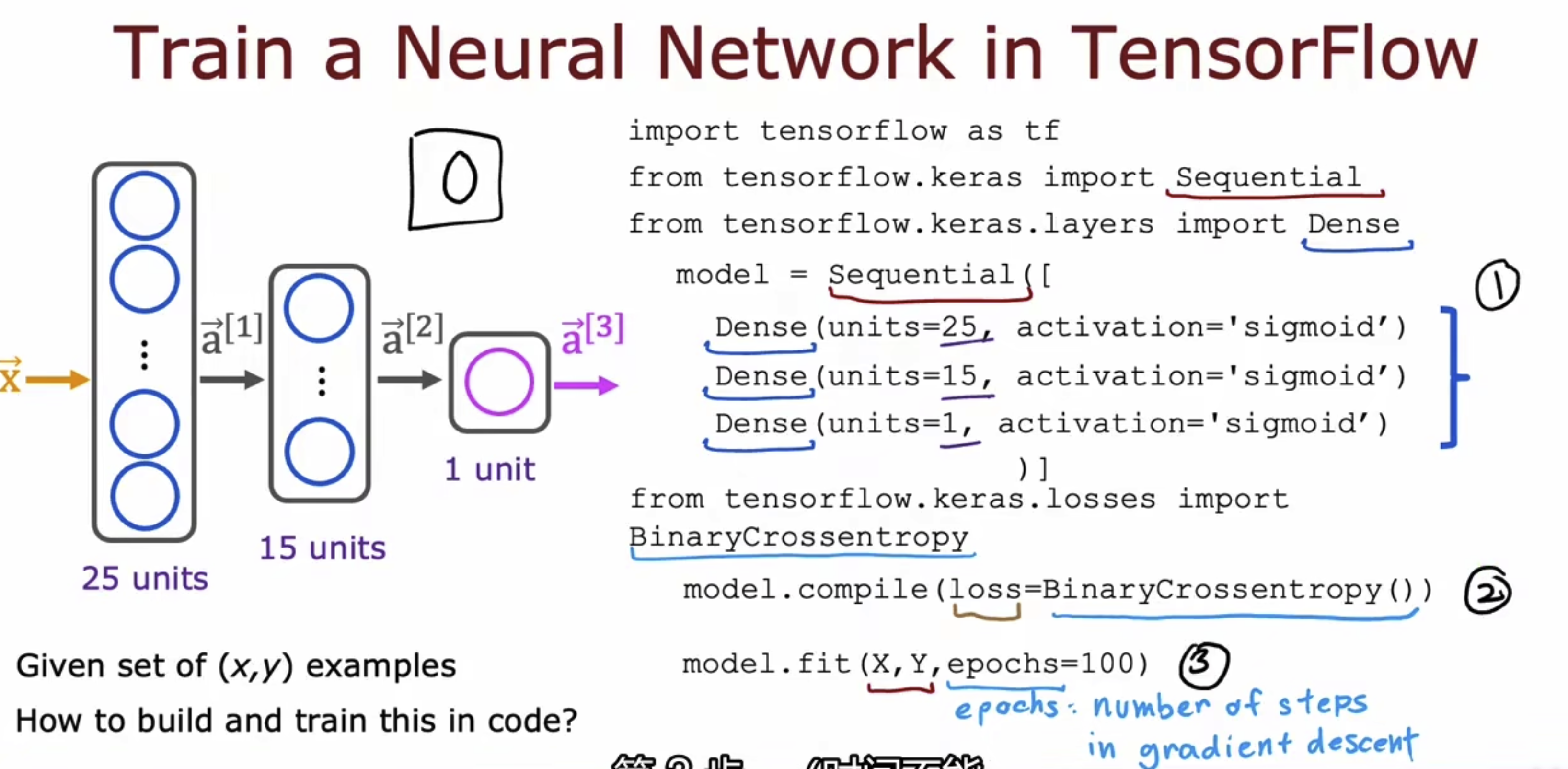
当然上面对于分类网络的解释是一个简洁的解释,我们来进行更加具象的了解一下。左边是机器学习的三步骤:1. 给定输入x和参数x,b,如何定义模型;2. 如何定义损失;3. 如何最小化损失。中间是对应的逻辑回归的数学表达公式。右边是对应的TF框架下的代码表达。
代码表达部分其实就三行代码,model = ... # TF下的组件拼接而成的model; model.compile(loss = ... ) # TF下的一个loss; model.fit(x, y, epochos=...) # 封装好的梯度下降方法。

我们将代码部分重新摘出来,复习一遍,

使用封装好的loss函数,上面那个是二值交叉熵损失用作分类,下面哪个是MSE损失用作回归,

使用封装好的梯度下降函数算法,这里会自动计算多个batch的均值,

x.2 多种激活函数和激活函数选择以及为何要用激活函数
关于多种激活函数,基本上只有三种类型,线性,sigmoid及其变体(Softmax),ReLU及其变体(leaky ReLU)。其中后两种是非线性激活函数,关于为何要从sigmoid变为ReLU,这是从需求出发的,如果你需要的输出你想让他较大方差的分布在一个范围,而不是小方差的分布在一个范围,则你需要将sigmoid改为ReLU,可以联想灰度直方图均衡化道理。
常见的激活函数的表达式和函数图像如下,

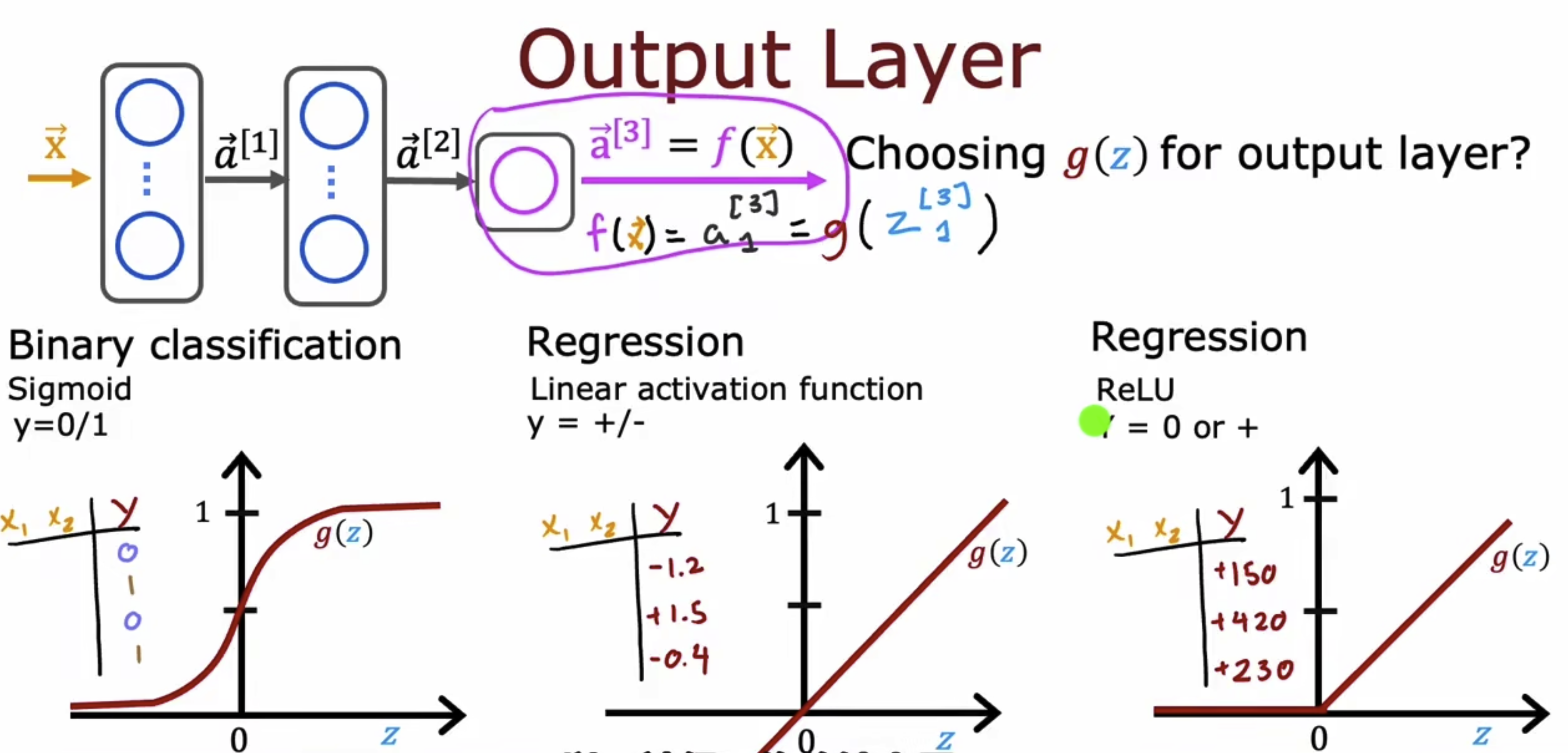
关于激活函数如何选择,我们则要分层看问题。我们会将模型分为输入层,隐藏层,输出层。其中激活函数在输出层和隐藏层是有区别的。在输出层的激活函数,主要取决于你想解决的问题和期望得到的输出是什么样子的,例如你在解决分类问题,分类结果只有0,1则sigmoid是好的选择;例如你在解决回归问题,你期望得到有正数有负数的输出,则使用线性激活函数为妙;例如如果你在解决回归问题,但你期望得到的输出只有正数,则使用ReLU为妙。
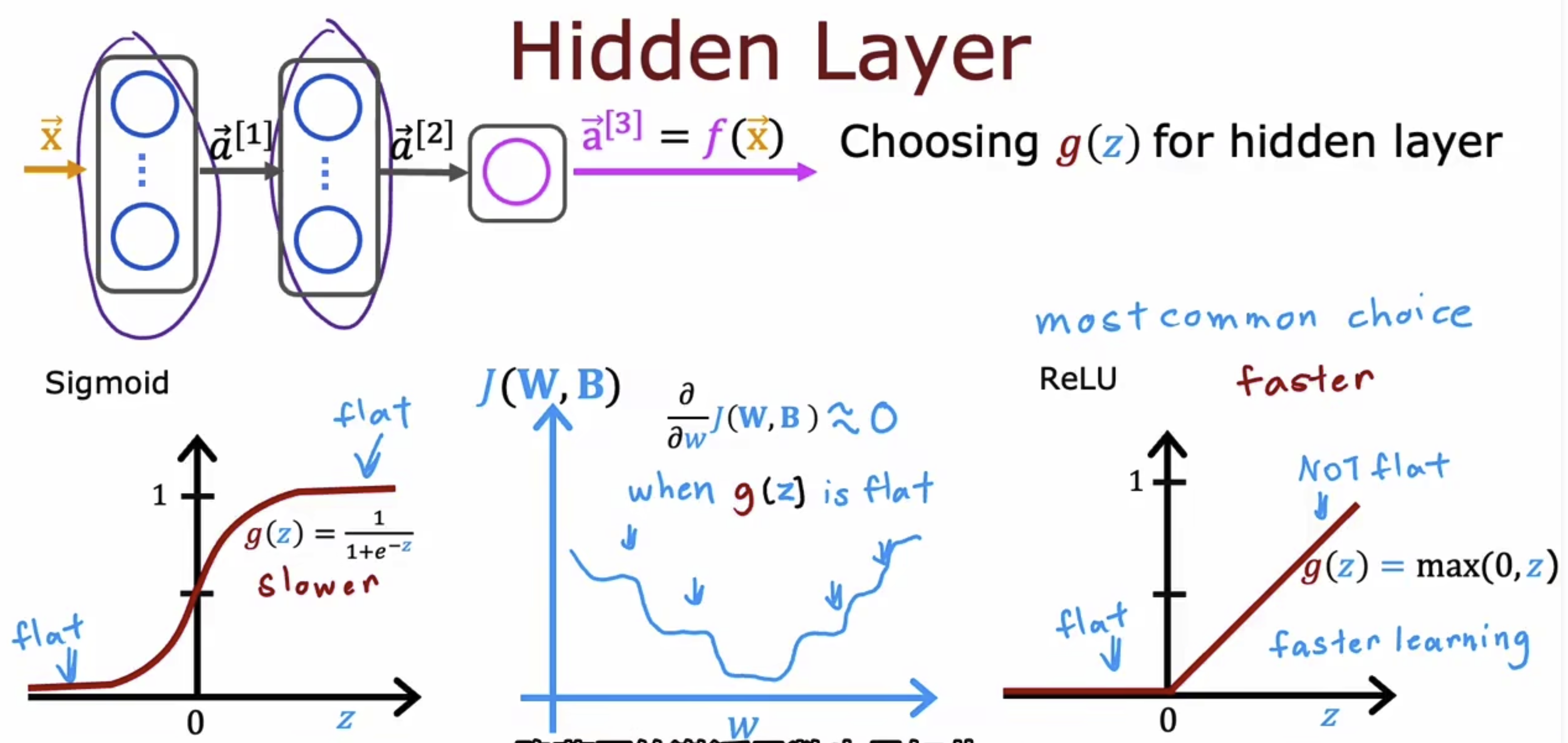
在隐藏层中,我们一般只会使用非线性激活函数。而在sigmoid和ReLU的选择中,我们现在通常使用ReLU函数。原因在于:1. 计算简单。2. sigmoid在两边较平,这就导致了在其形成的损失函数里面平滑的地方较多,下降较慢。
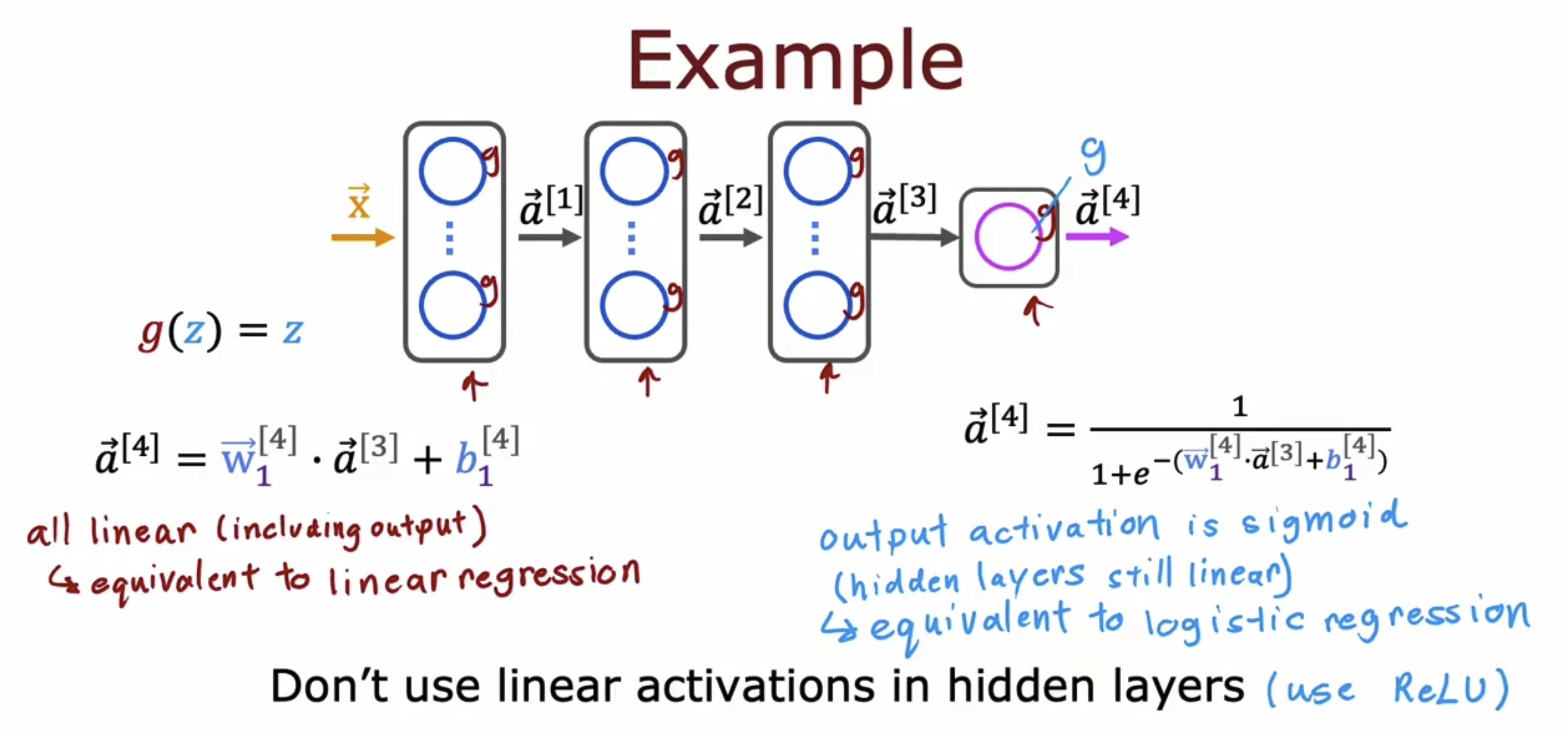
接下来我们举一个例子,

关于为何要引入激活函数,因为我们要引入非线性因素。这么说可能还不太理解,我们以线性激活函数为例来说明如下,我们能够发现如果使用线性层作为激活函数,线性回归多层后仍然可以只用一层线性回归来表示,