注意:【实现Jacobi(雅可比)迭代可以用MPI实现,也可以用CUDA实现,想使用CUDA实现Jacobi的同学,请参考这里,
1,原理介绍【食用代码前最好先弄清楚原理】
1.1 公式介绍 - 可以不看,这只是相关的公式,推导过程可以不看,但关注最终被标蓝的那个公式

1.2 依据1.2得出的结论公式,可以知道是如何计算的
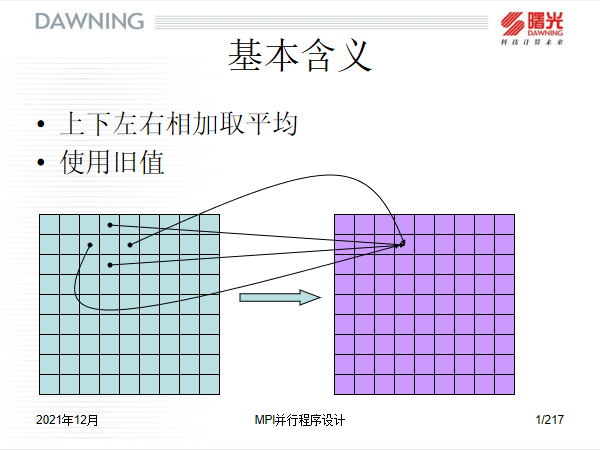
1.3 数据集划分
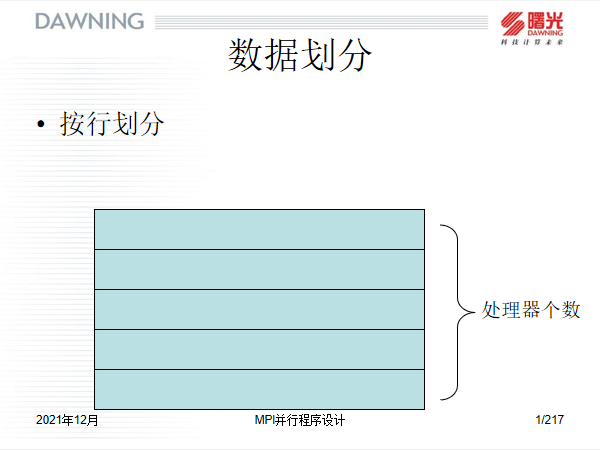
说明:
MPI采用 对等模式实现雅可比并行计算,而不是一对多模式,所以需要将数据集划分为几个长度相等的子数据集,每一个进程单独负责处理一个数据集即可,这样进程与进程之间具有一定的独立性;
可以采用行划分,也可以采用列划分
1.4 进程的私有数据
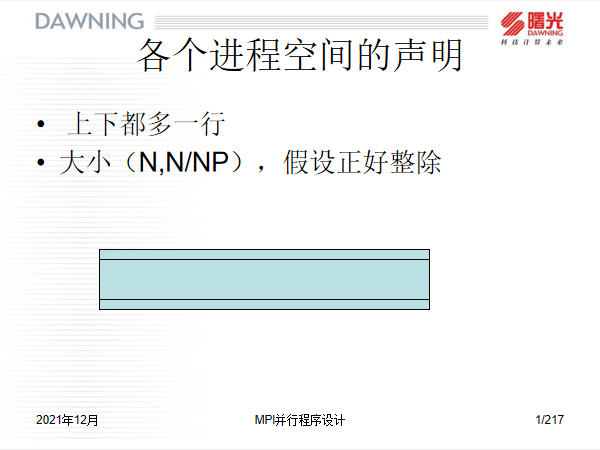
注意,一旦使用MPI,则在程序开始的那一刻,你每声明的一个变量,数组等在每一个进程中都存在,且变量名相同,所以你使用MPI的时候,每一个进程的数据矩阵的大小应该是 总数据集的[维度 / 进程数, 维度] ,但是因为需要接收边界值,所以真实的数组大小是[维度 / 进程数 + 2, 维度 + 2]。
1.5 任取一个进程的执行轨迹

1.6 example
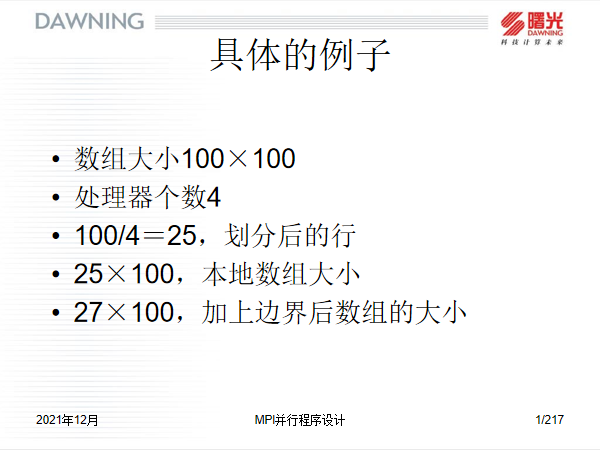
1.7 边界数据的分发
- 从上往下看,0号,1号和2号进程分别需要截取本进程数据集中的倒数第二行的数据,然后分别发往1,2,3号进程的第0行。
- 从下网上看,1,2,3号进程需要截取本进程数据集中的第二行数据,分别发往0,1,2号进程的倒数第一行中。
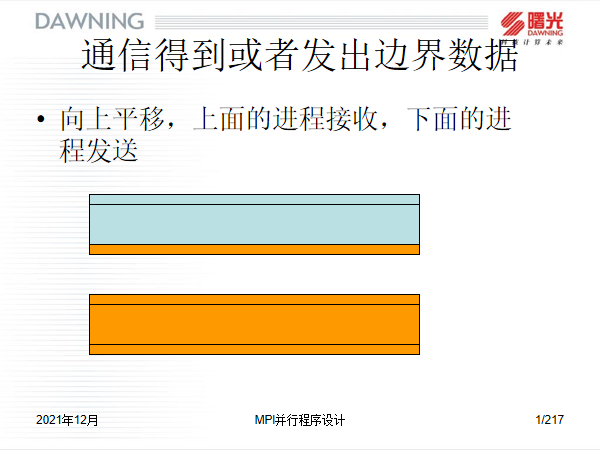
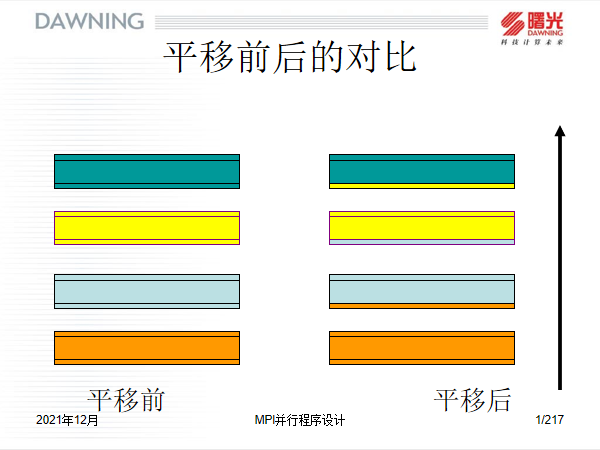
1.8 通信流程
- 一般0号进程是上边界,最后一个进程y(= 进程数 - 1),是下边界
- 通信时0号进程的首行以及y号进程的尾行不需要接收数据,0号进程的第二行和y号进程的倒数第二行也不需要发送数据。所以通信时需要考虑这两种特殊情况。

1.9 计算的行号范围
- 循环是从第一行开始,倒数第二行结束的的,因为第0号和尾行行是边界
2.1 版本1.0 (比较容易理解,推荐先看完,虽然此版本容易产生死锁,下面还有两个改进版本)
这里我说一下为什么会产生死锁
如果有两个进程处理数据总集,但是他们都是先执行接收操作,而不是发送操作,那么两个进程会因都收不到数据而一致等待,如果没有外部干预,会一直等待下去
#include <mpi.h>
#include<fstream>
#include <sstream>
#include <iostream>
// determine the size of the array needing itering
#define N 100
// define the num of processes
#define X 4
// know the size of the array each process has
#define myarysize N / X
using namespace std;
int main(int argc, char* argv[])
{
int n, myid, numprocs;
int up, down;
int opt;
int i, j;
// define the num of iterations
int nsteps = 1000;
double prev[myarysize + 2][N + 2], curr[myarysize + 2][N + 2], gather_arr[N][N + 2], temp[myarysize][N + 2];
MPI_Datatype onerow;
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
// initialize all arrays
for (int i = 0; i < N; i++)
{
for (int j = 0; j < N + 2; j++)
{
if (i < myarysize)
temp[i][j] = 0;
gather_arr[i][j] = 0;
}
}
for (int i = 0; i < myarysize + 2; i++)
{
for (int j = 0; j < N + 2; j++)
{
prev[i][j] = 20.00;
}
}
if (myid == 0)
{
for (int j = 0; j < N + 2; j++)
{
// 将第一行的大约三分之一到三分之二之间的位置设置为100,其他设置为20
if (j > 0.3 * (N + 1) && j < 0.7 * (N + 1))
{
prev[0][j] = 100.00;
}
}
}
MPI_Type_contiguous(N + 2, MPI_DOUBLE, &onerow);
MPI_Type_commit(&onerow);
int begin_row = 1;
int end_row = myarysize;
for (n = 0; n < nsteps; n++)
{
if (myid < 3) {
MPI_Send(&prev[myarysize][0], 1, onerow,
myid + 1, 1000, MPI_COMM_WORLD);
MPI_Recv(&prev[myarysize + 1][0], 1, onerow,
myid + 1, 1000, MPI_COMM_WORLD, &status);
}
if (myid > 0) {
MPI_Send(&prev[1][0], 1, onerow,
myid - 1, 1000, MPI_COMM_WORLD);
MPI_Recv(&prev[0][0], 1, onerow,
myid - 1, 1000, MPI_COMM_WORLD, &status);
}
for (i = begin_row; i <= end_row; i++)
{
for (j = 1; j < N + 1; j++)
{
curr[i][j] = (prev[i][j + 1] + prev[i][j - 1] + prev[i - 1][j] + prev[i + 1][j]) * 0.25;
}
}
for (i = begin_row; i <= end_row; i++)
{
for (j = 1; j < N + 1; j++)
{
prev[i][j] = curr[i][j];
}
}
}/* 迭代结束*/
// 用一个临时数组存放这些更新完的数组(去掉首行和末行,因为这两行是边界)
for (int i = begin_row; i <= end_row; i++)
{
for (int j = 0; j < N + 2; j++)
{
temp[i - 1][j] = prev[i][j];
}
}
MPI_Barrier(MPI_COMM_WORLD);
MPI_Gather(&temp, myarysize * (N + 2), MPI_DOUBLE, &gather_arr, myarysize * (N + 2), MPI_DOUBLE, 0, MPI_COMM_WORLD);//需要单独在外面
MPI_Type_free(&onerow);
MPI_Finalize();
if (myid == 0)
{
// output the result to the csv file
std::ofstream myfile;
myfile.open("finalTemperatures.csv");
for (int p = 0; p < N + 2; p++)
{
for (int i = 0; i < N + 2; i++)
{
std::ostringstream out;
out.precision(8);
if (p == 0)
{
if (i > 0.3 * (N + 1) && i < 0.7 * (N + 1))
myfile << "100" << ", ";
else
myfile << "20" << ", ";
}
else if (p == N + 1)
myfile << "20" << ", ";
else
{
out << gather_arr[p - 1][i];
std::string str = out.str(); //从流中取出字符串 数值现在存储在str中,等待格式化。
myfile << str << ", ";
}
}
myfile << "\n";
}
myfile.close();
}
return 1;
}
2.2 无死锁版版本2.0
一般版本使用指南【如若使用高级通用的linux版本,请往下看】
- 常量N表示被分解前的二维数组的维度,即N ✖ N 的矩阵
- myarysize表示 被分解后的每一个进程所操作的数组维度,一般等于 N /X, X表示电脑本机的cpu数量(也称最大并发数),不知道processors的数量的可以使用此代码获取,unsigned int in = std::thread::hardware_concurrency();
- nsteps表示迭代的次数,如果N(>= 100)比较大, 一般nsteps最低等于1000才能看到效果,否则你输出的时候,可能发现数据一直不变(这是我碰到的一个坑,当时这个变量只设置为了10次)
- 此代码已经在我的windows os上测试过,结果和老师给的一致,大家可以放心食用
- sendrecv可以避免方法一产生的死锁问题,
- MPI_Sendrecv表示的作用是将本进程的信息先发送出去,并接收其他进程的信息(因为是先发送,后接收,所以一定能避免死锁,不存在任意两个进程之间相互等待对方发送的消息的情况)
- windows版本中跑此程序,需要参考这一文档
https://blog.csdn.net/liuyongjin1984/article/details/1957286 - linux下只需要输入以下三行命令
module load gcc mvapich2(这表示加载相应模块,如果没有请下载)
mpic++ Lab6_MPI.cpp -o a.out
mpirun -np 16 ./a.out -N 256 -I 10000( -np 16表示分配的处理器的数量是16个)
#include <mpi.h>
#include<fstream>
#include <sstream>
#include <iostream>
// determine the size of the array needing itering
#define N 100
// define the num of processes
#define X 4
// know the size of the array each process has
#define myarysize N / X
using namespace std;
int main(int argc, char* argv[])
{
int n, myid, numprocs ;
int up, down;
int opt;
int i, j;
// define the num of iterations
int nsteps = 1000;
char optstring[] = "N:I:"; // 分别代表-N, -I命令行参数,其中带:的表示参数可以指定值
double prev[myarysize + 2][N + 2], curr[myarysize + 2][N + 2], gather_arr[N][N + 2], temp[myarysize][N + 2];
MPI_Datatype onerow;
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
// initialize all arrays
for (int i = 0; i < N; i++)
{
for (int j = 0; j < N + 2; j++)
{
if (i < myarysize)
temp[i][j] = 0;
gather_arr[i][j] = 0;
}
}
for (int i = 0; i < myarysize + 2; i++)
{
for (int j = 0; j < N + 2; j++)
{
prev[i][j] = 20.00;
}
}
if (myid == 0)
{
for (int j = 0; j < N + 2; j++)
{
// 将第一行的大约三分之一到三分之二之间的位置设置为100,其他设置为20
if (j > 0.3 * (N + 1) && j < 0.7 * (N + 1))
{
prev[0][j] = 100.00;
}
}
}
MPI_Type_contiguous(N + 2, MPI_DOUBLE, &onerow);
MPI_Type_commit(&onerow);
up = myid - 1;
if (up < 0) up = MPI_PROC_NULL;
down = myid + 1;
if (down > 3) down = MPI_PROC_NULL;
int begin_row = 1;
int end_row = myarysize;
for (n = 0; n < nsteps; n++)
{
MPI_Sendrecv(&prev[1][0], 1, onerow, up, 1000, &prev[myarysize + 1][0], 1, onerow, down, 1000, MPI_COMM_WORLD, &status);
MPI_Sendrecv(&prev[myarysize][0], 1, onerow, down, 1000, &prev[0][0], 1, onerow, up, 1000, MPI_COMM_WORLD, &status);
for (i = begin_row; i <= end_row; i++)
{
for (j = 1; j < N + 1; j++)
{
curr[i][j] = (prev[i][j + 1] + prev[i][j - 1] + prev[i - 1][j] + prev[i + 1][j]) * 0.25;
}
}
for (i = begin_row; i <= end_row; i++)
{
for (j = 1; j < N + 1; j++)
{
prev[i][j] = curr[i][j];
}
}
}/* 迭代结束*/
// 用一个临时数组存放这些更新完的数组(去掉首行和末行,因为这两行是边界)
for (int i = begin_row; i <= end_row; i++)
{
for (int j = 0; j < N + 2; j++)
{
temp[i - 1][j] = prev[i][j];
}
}
MPI_Barrier(MPI_COMM_WORLD);
//std::cout << "进程号为"<<myid<<"时,其temp[end_row - 1][N ]的值为:" << temp[end_row - 1][N] << std::endl;
MPI_Gather(&temp, myarysize * (N + 2), MPI_DOUBLE, &gather_arr, myarysize * (N + 2), MPI_DOUBLE, 0, MPI_COMM_WORLD);//需要单独在外面
MPI_Type_free(&onerow);
MPI_Finalize();
if (myid == 0)
{
// output the result to the csv file
std::ofstream myfile;
myfile.open("finalTemperatures.csv");
for (int p = 0; p < N + 2; p++)
{
for (int i = 0; i < N + 2; i++)
{
std::ostringstream out;
out.precision(8);
if (p == 0)
{
if (i > 0.3 * (N + 1) && i < 0.7 * (N + 1))
myfile << "100" << ", ";
else
myfile << "20" << ", ";
}
else if (p == N + 1)
myfile << "20" << ", ";
else
{
out << gather_arr[p - 1][i];
std::string str = out.str(); //从流中取出字符串 数值现在存储在str中,等待格式化。
myfile << str << ", ";
}
}
myfile << "\n";
}
myfile.close();
}
return 1;
}
2.3 高级版本3.0【带输出时间】,同时采用命令行参数的形式,决定进程数,矩阵的维度,以及迭代的次数
- 可以看到,在改进版本中,我把相应的数组由静态数组变为了动态数组,这是因为静态数组不允许初始值为变量,只能为常量,但是当从命令行获取迭代次数,矩阵维数的时候,只能传入动态变量。
- 改进版中,可以看到在使用MPI_gather函数的时候,使用的是两个一维数组,这里必须是一维度,因为一维数组中的地址空间都是连续的,所以才能方便收集,二维的就不一定了。
- linux下的使用方式
-
module load gcc mvapich2 -
mpic++ Lab6_MPI.cpp -o a.out -
mpirun -n 16 ./a.out -N 256 -I 10000
mpirun -np 16 ./a.out -N 256 -I 10000( -np 16表示处理器的数量,也表示进程数, -N 256表示矩阵维度为256,-I 10000表示迭代次数为10000)
#include <mpi.h>
#include<fstream>
#include <sstream>
#include <iostream>
#include<vector>
#include <time.h>
//#include <sys/time.h>
//#define N 100
//#define myarysize N / 4
using namespace std;
int main(int argc, char* argv[])
{
// myid defines the NO of each process, while numprocs marks the total number of processors
int n, myid, numprocs ;
// the border process ranked 0 and (numproc - 1)
int up, down;
int i, j;
// determine the size of the array needing itering
int N;
// know the size of the array each process has
int myarysize ;
// define the num of iterations
int nsteps;
MPI_Datatype onerow;
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
// judge the args
if (argc < 5)
{
cout << "Invalid parameters, please check your values." << endl;
return -1;
}
else
{
if (atoi(argv[2]) <= 0 || atoi(argv[4]) <= 0)
{
cout << "Invalid parameters, please check your values." << endl;
return 0;
}
if (atoi(argv[2]) > 256 || atoi(argv[4]) > 10000)
{
cout << " the first param is up to 256 and the second up to 10000." << endl;
return 0;
}
}
// initialize all arrays claimed above
N = atoi(argv[2]);
//N = 256;
//nsteps = 10000;
nsteps = atoi(argv[4]);
myarysize = N / numprocs;
vector<vector<double>> prev(myarysize + 2, vector<double>(N + 2));
vector<vector<double>> curr(myarysize + 2, vector<double>(N + 2));
// define the temp_1d designed for saving the outcome of iterations
double* temp_1d = (double*)malloc(sizeof(double) * myarysize * (N + 2));
// this 1d array is used for collecting data coming from all processes
double* gather_arr = (double*)malloc(sizeof(double) * N * (N + 2));
for (size_t i = 0; i < N * (N + 2); i++) gather_arr[i] = 20.00;
for (int i = 0; i < myarysize + 2; i++)for (int j = 0; j < N + 2; j++) prev[i][j] = 20.00;
if (myid == 0)
for (int j = 0; j < N + 2; j++)
if (j > 0.3 * (N + 1) && j < 0.7 * (N + 1))
prev[0][j] = 100.00;
// this is a kind of new datatype assembling the concrete length of data we want to transfer from process to process
MPI_Type_contiguous(N + 2, MPI_DOUBLE, &onerow);
MPI_Type_commit(&onerow);
up = myid - 1;
if (up < 0) up = MPI_PROC_NULL;// when the current process is the number 0 process, it needn't transfer data to the number -1 process,and hence set NULL_process
down = myid + 1;
if (down > (numprocs - 1)) down = MPI_PROC_NULL;// when the current process is the NO (numproc - 1) process, it needn't transfer data to the number (numproc) process,and therefore set NULL_process
int begin_row = 1;
int end_row = myarysize;
// timestamp 1 - marking the start time of iterations
//struct timeval t1, t2;
//gettimeofday(&t1, 0);
clock_t start, end;
start = clock();
for (n = 0; n < nsteps; n++)
{
MPI_Sendrecv(&prev[1][0], 1, onerow, up, 1000, &prev[myarysize + 1][0], 1, onerow, down, 1000, MPI_COMM_WORLD, &status);
MPI_Sendrecv(&prev[myarysize][0], 1, onerow, down, 1000, &prev[0][0], 1, onerow, up, 1000, MPI_COMM_WORLD, &status);
for (i = begin_row; i <= end_row; i++)
{
for (j = 1; j < N + 1; j++)
{
curr[i][j] = (prev[i][j + 1] + prev[i][j - 1] + prev[i - 1][j] + prev[i + 1][j]) * 0.25;
}
}
for (i = begin_row; i <= end_row; i++)
for (j = 1; j < N + 1; j++)
prev[i][j] = curr[i][j];
}/* iteration over*/
// use a 1d temporary array to save these data that need removing the first and the last line(because these two lines are borders used in exchange with other processes)
int k = 0;
for (int i = begin_row; i <= end_row; i++)
{
for (int j = 0; j < N + 2; j++)
{
temp_1d[k] = prev[i][j];
k++;
}
}
MPI_Barrier(MPI_COMM_WORLD);
if (myid == 0)
{
// print the time
end = clock();
double interval = (double)(end - start) / CLOCKS_PER_SEC;
// timestamp2 - marking the end of iterations
//gettimeofday(&t2, 0);
//double time = (1000000.0 * (t2.tv_sec - t1.tv_sec) + t2.tv_usec - t1.tv_usec) / 1000.0;
printf("Time to generate: %4.2f ms \n", interval * 1000);
}
// notice : please use 2 1D arrays to gather all data from all processes, otherwise there must be an unknown error caused by pointer
MPI_Gather(temp_1d, myarysize* (N + 2), MPI_DOUBLE, gather_arr, myarysize* (N + 2), MPI_DOUBLE, 0, MPI_COMM_WORLD);
MPI_Type_free(&onerow);
MPI_Finalize();
// back to the root process
if (myid == 0)
{
// output the result to the csv file
std::ofstream myfile;
myfile.open("finalTemperatures.csv");
for (int p = 0; p < (N + 2) * (N + 2); p++)
{
std::ostringstream out;
out.precision(8);
if (p % (N + 2) == 0 && p != 0)
{
myfile << "\n" ;
}
if (p < (N + 2))
{
if (p > 0.3 * (N + 1) && p < 0.7 * (N + 1))
myfile << "100" << ", ";
else
myfile << "20" << ", ";
}
else if (p >= (N + 2) * (N + 1))
myfile << "20" << ", ";
else
{
out << gather_arr[p - (N + 2)];
std::string str = out.str(); //format
myfile << str << ", ";
}
}
myfile.close();
}
free(gather_arr);
free(temp_1d);
std::vector<vector<double>>().swap(prev);
std::vector<vector<double>>().swap(curr);
return 1;
}