DeepMind的研究人员发现了大脑对多巴胺的反应与分布强化学习的趋势AI理论之间的相似之处。这些发现验证了分布强化学习的潜力,并促使DeepMind研究人员自豪地宣称“现在人工智能研究走在正确的道路上”。
在这项新研究中,来自DeepMind和哈佛大学的研究人员分析了小鼠体内多巴胺细胞的活动,发现多巴胺神经元根据不同程度的“悲观”和“乐观”状态预测奖励。使用分布性TD算法,最简单的分布性RL形式之一,研究人员希望研究和解释多巴胺对行为,情绪等的影响。
在实验中,小鼠获得了未知数量的奖励,目标是评估多巴胺神经元活性是否与标准TD(时间差异)或分布性TD更一致。结果显示,单个多巴胺细胞之间存在显着差异 - 一些预测非常大的奖励,而另一些预测非常小的奖励。
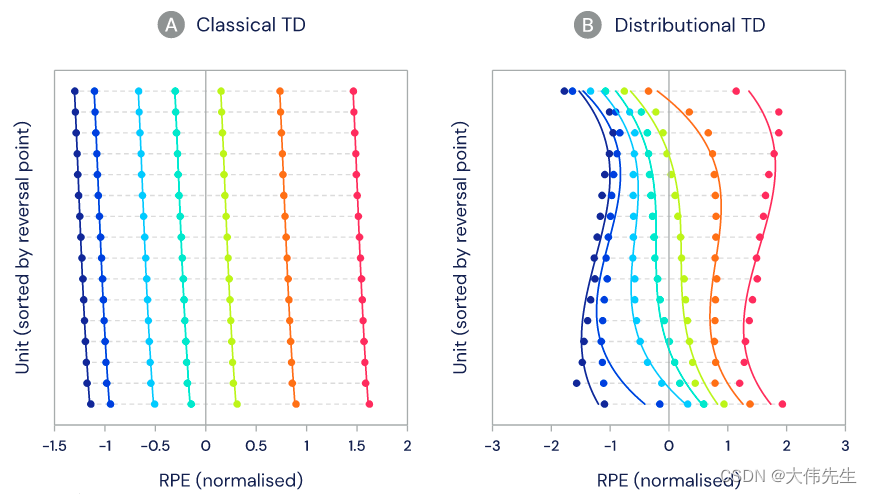
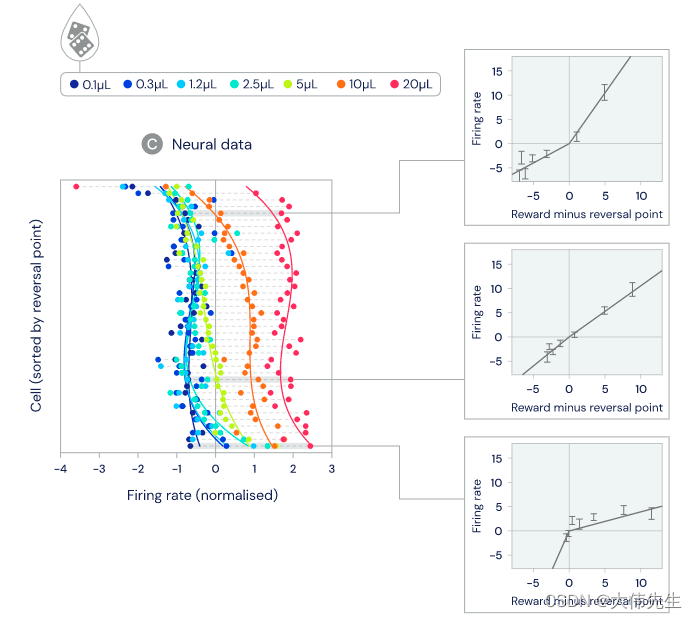
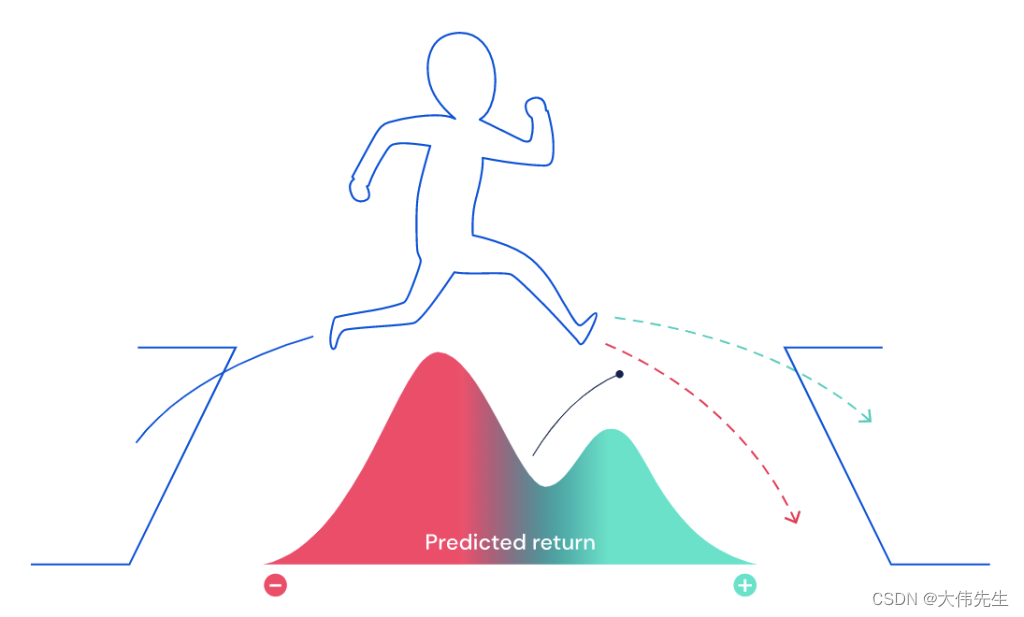
在许多情况下,特别是在现实世界中,未来的奖励结果不是一个完全已知的数量,而是基于特定行为的预测,具有一定的随机性。例如,如果模拟中的人形AI代理试图跳过虚拟间隙,则预测的奖励将是两个:成功(到达另一边)或失败(落入间隙)。与学习预测平均未来奖励的标准TD算法相比,分布型TD算法可以学习预测所有未来奖励,并具有潜在回报的双峰值分布。分布强化学习技术已成功用于在围棋和星际争霸等游戏中构建代理。
这项研究为神经科学家提出了许多新的问题。如果大脑选择性地“倾听”乐观或悲观的多巴胺神经元——这可能是冲动行为或抑郁的原因吗?一旦动物学会了分配奖励的机制,这种表示将如何用于其下游任务?多巴胺细胞之间的乐观情绪变异性与大脑中其他已知的可变形式有何关系?
DeepMind的研究人员希望通过提出这样的问题来促进神经科学研究的发展,并在此过程中形成一个良性循环,这也将为人工智能研究带来好处。
论文《基于多巴胺的强化学习中价值的分布代码》是关于自然的。