docker搭建简单elk日志系统1
docker搭建简单elk日志系统2
docker搭建简单elk日志系统3
如有疑问可以去上面文档找相关内容
filebeat收集日志
1.本地下载filebeat,下载后解压缩
windows版filebeat-8.3.3官方下载地址
2.创建一个最简单的filebeat.yml配置文件filebeat-test.yml
4.编辑filebeat-test.yml
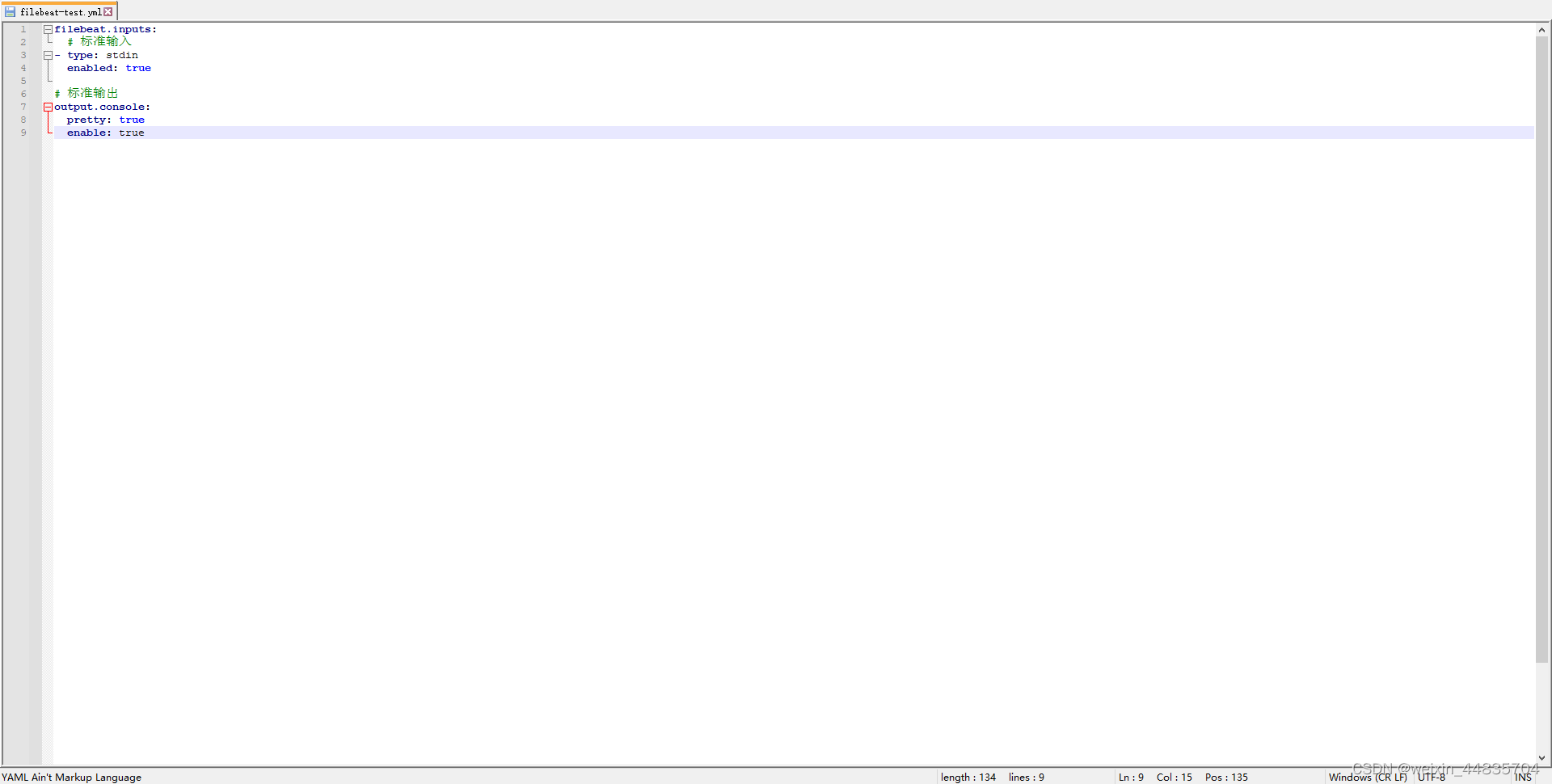
filebeat.inputs:
# 标准输入
- type: stdin
enabled: true
# 标准输出
output.console:
pretty: true
enable: true
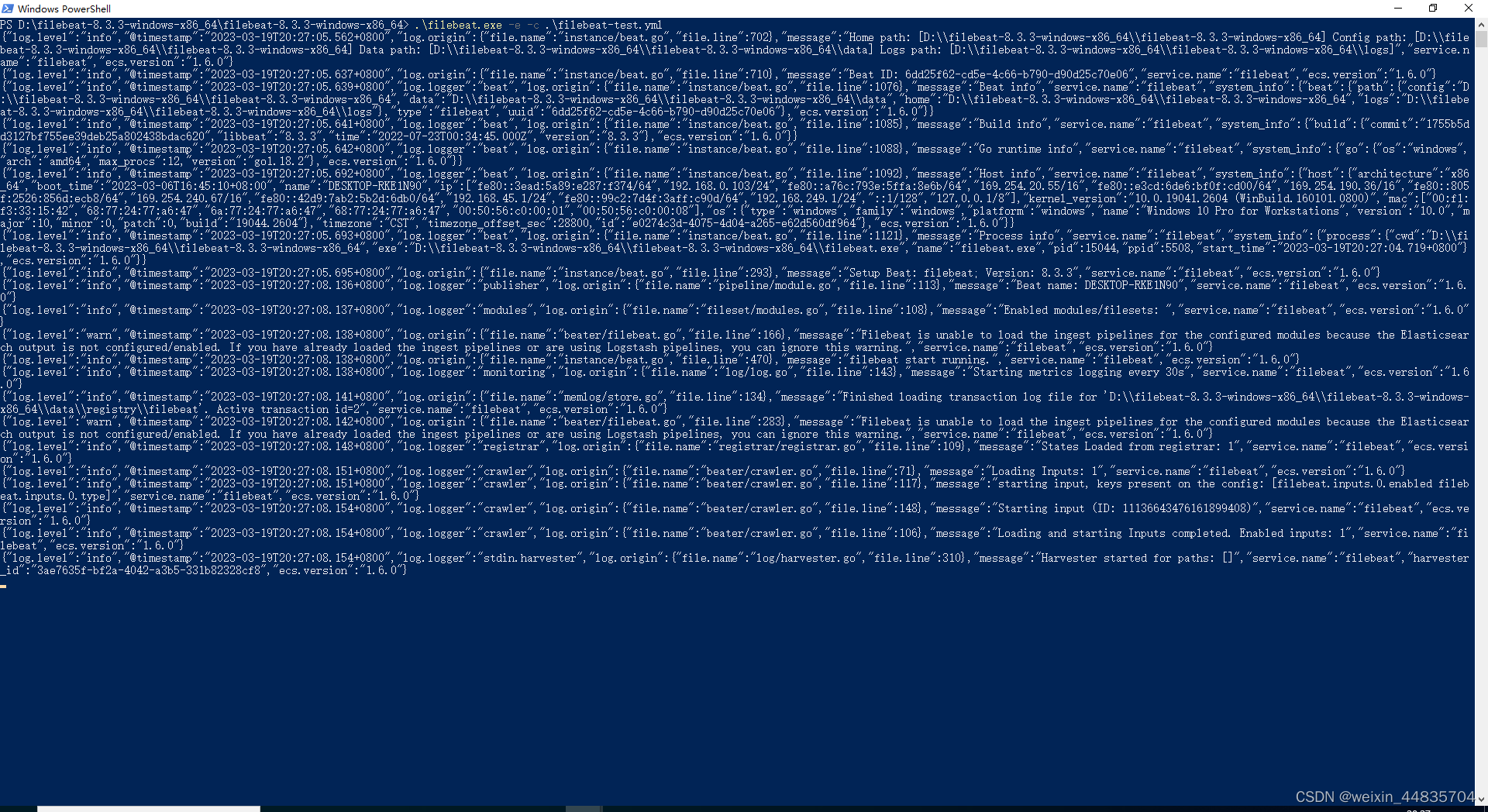
5.进入filebeat目录打开cmd或powershell窗口
执行
.\filebeat.exe -e -c .\filebeat-test.yml
-e 日志发送到标准错误输出而不是syslog文件
-c 指定配置文件启动
6.测试
直接在控制台输入一些测试内容

filebeat收集到一行文本返回的是一个json格式的数据
输入为
filebeat日志测试
输出为
{
"@timestamp": "2023-03-19T12:28:36.480Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "8.3.3"
},
"host": {
"name": "DESKTOP-RKE1N90"
},
"agent": {
"version": "8.3.3",
"ephemeral_id": "22bce021-88d5-4133-a3b6-672bf142c9cf",
"id": "6dd25f62-cd5e-4c66-b790-d90d25c70e06",
"name": "DESKTOP-RKE1N90",
"type": "filebeat"
},
"log": {
"offset": 0,
"file": {
"path": ""
}
},
"message": "filebeat日志测试",
"input": {
"type": "stdin"
},
"ecs": {
"version": "8.0.0"
}
}
其中收集到的文本内容在根节点的message字段中,filebeat输出的json数据不仅包含收集的内容,还默认会收集一些其他信息,如主机名、filebeat版本、收集的时间、收集内容来源等等
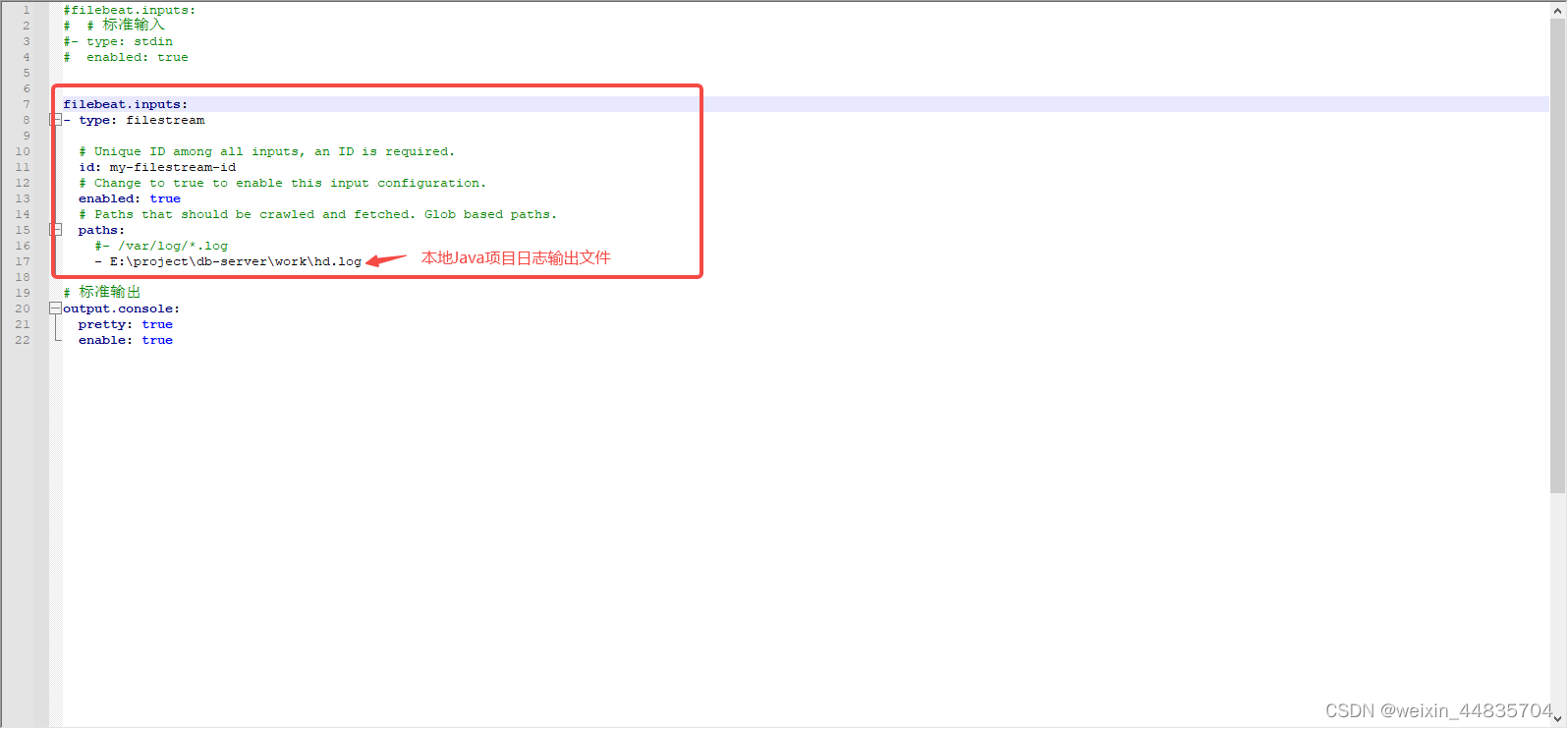
7.将filebeat-test.yml配置文件的输入改成扫描本地java项目日志文件
filebeat.inputs:
- type: filestream
# Unique ID among all inputs, an ID is required.
id: my-filestream-id
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
#- /var/log/*.log
- E:\project\db-server\work\hd.log
重新启动filebeat
.\filebeat.exe -e -c .\filebeat-test.yml
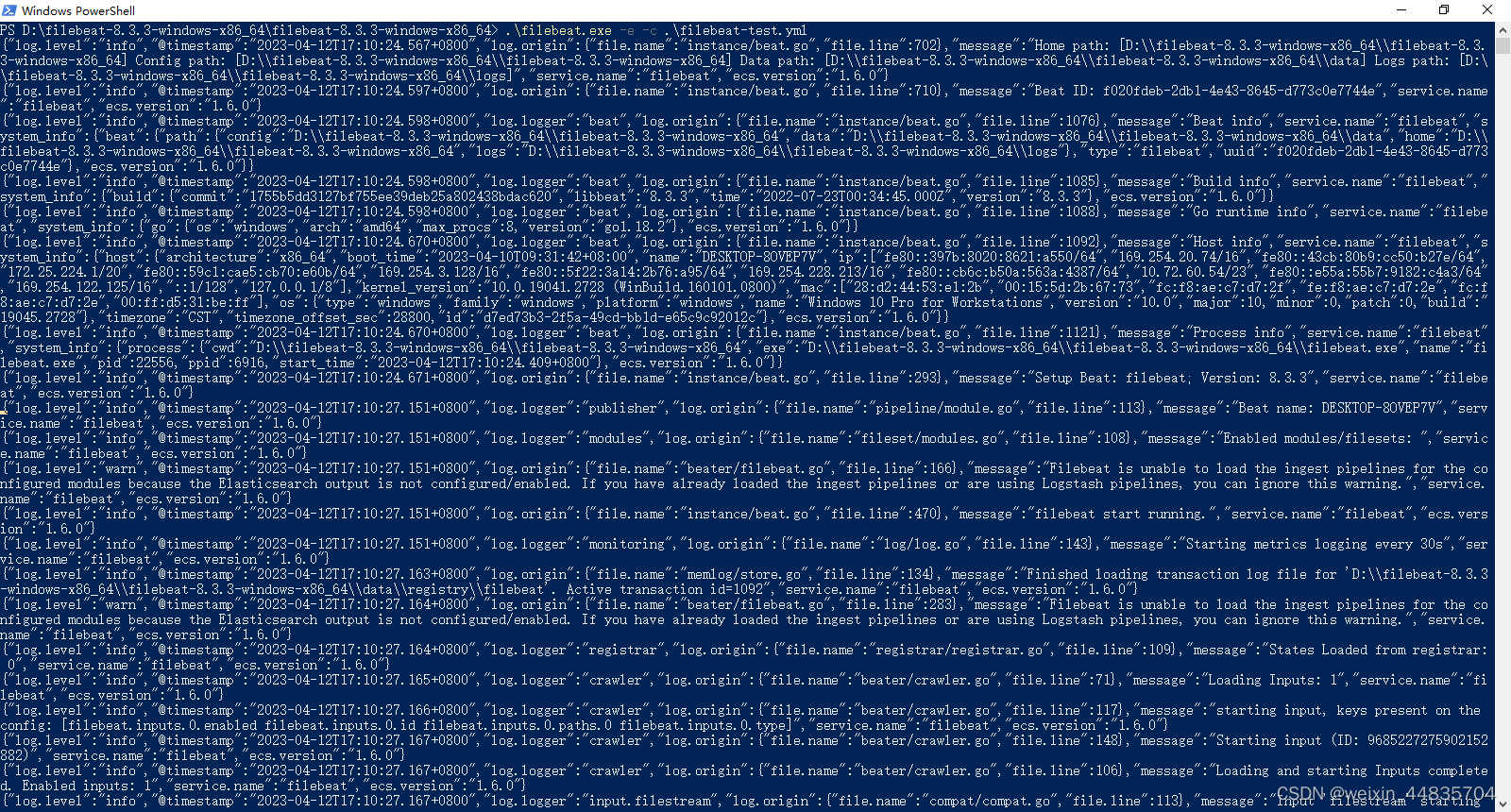
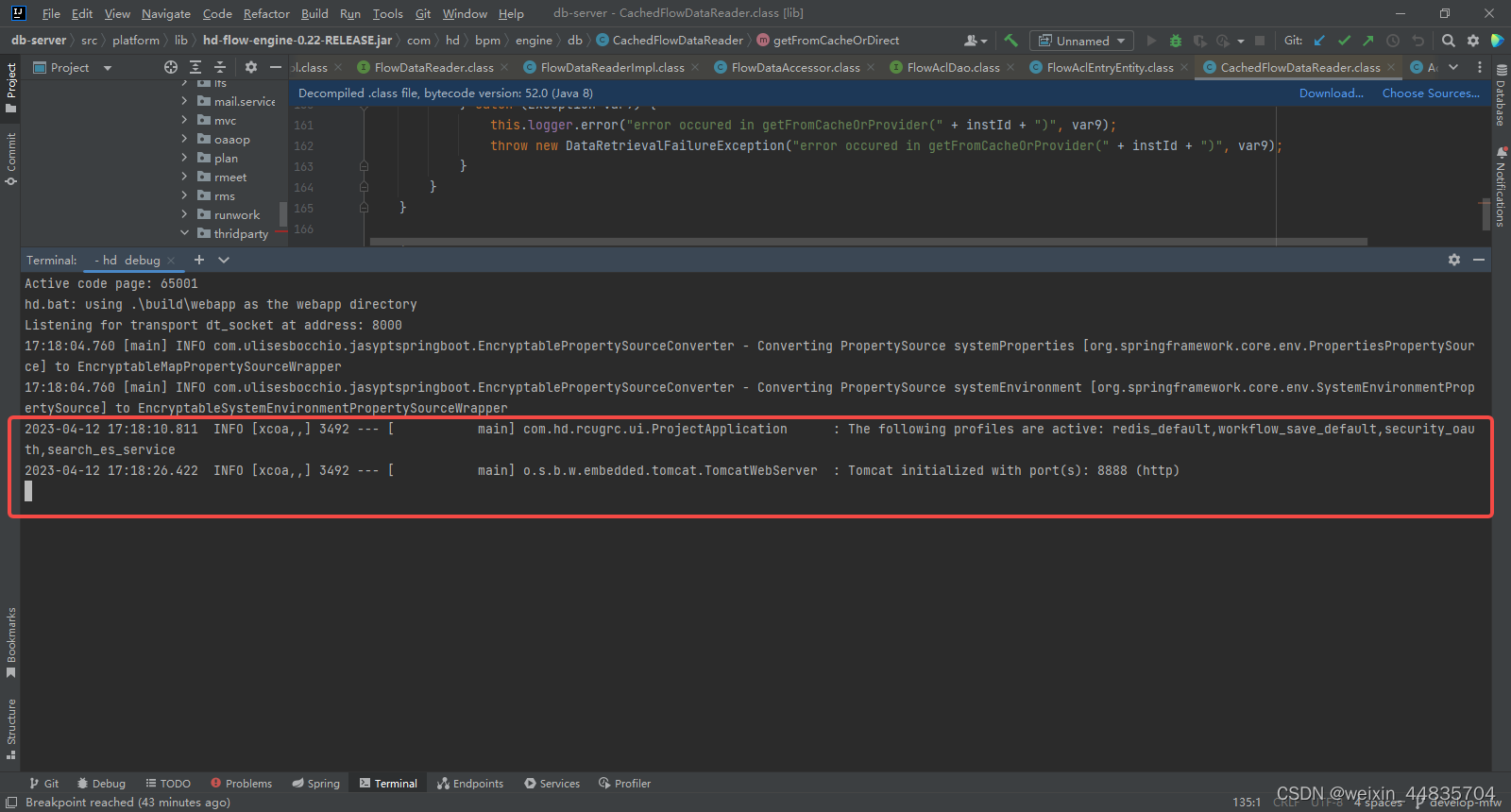
8.启动本地java应用
java应用控制台日志输出:
filebeat控制台日志输出:
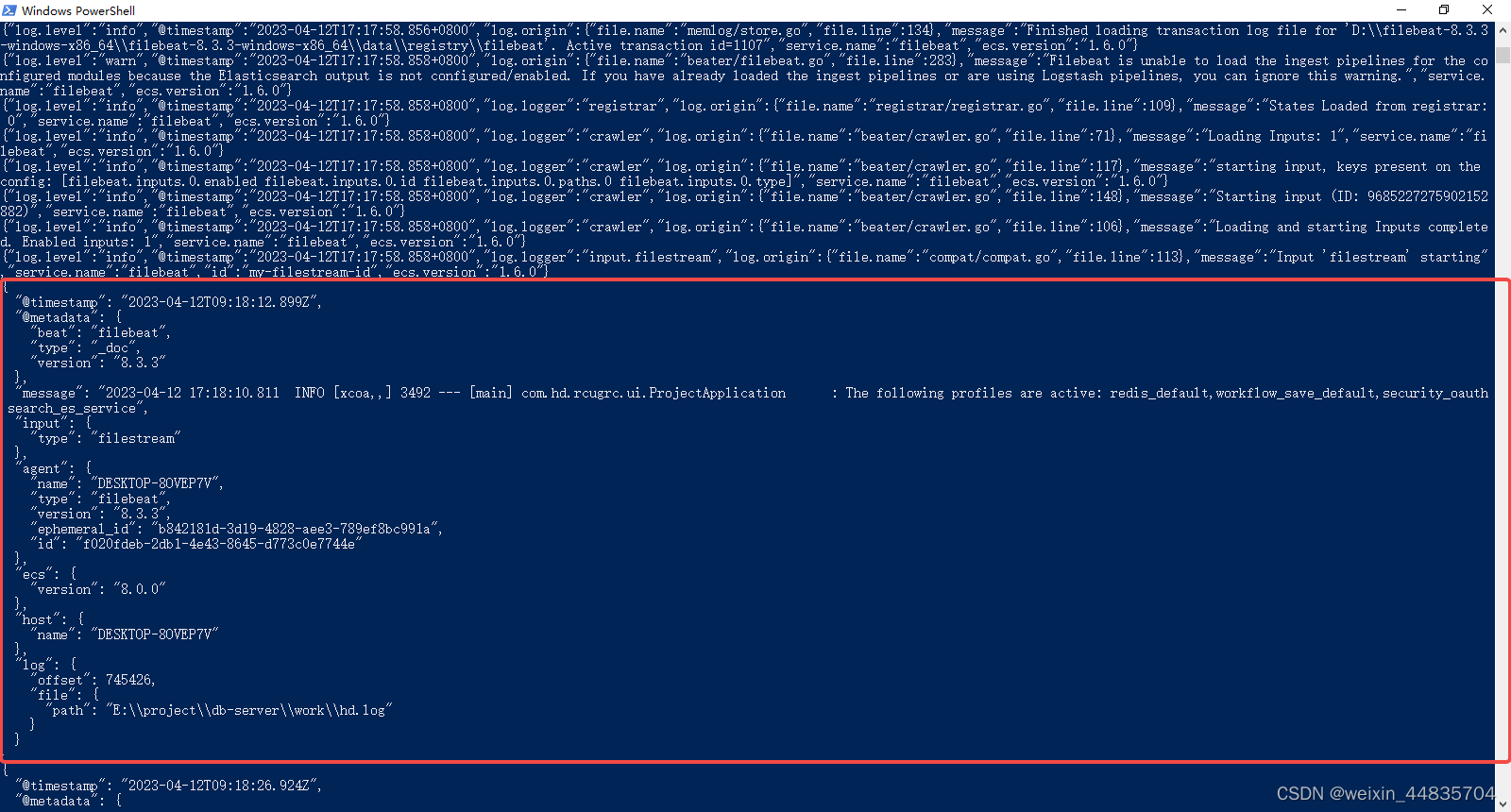
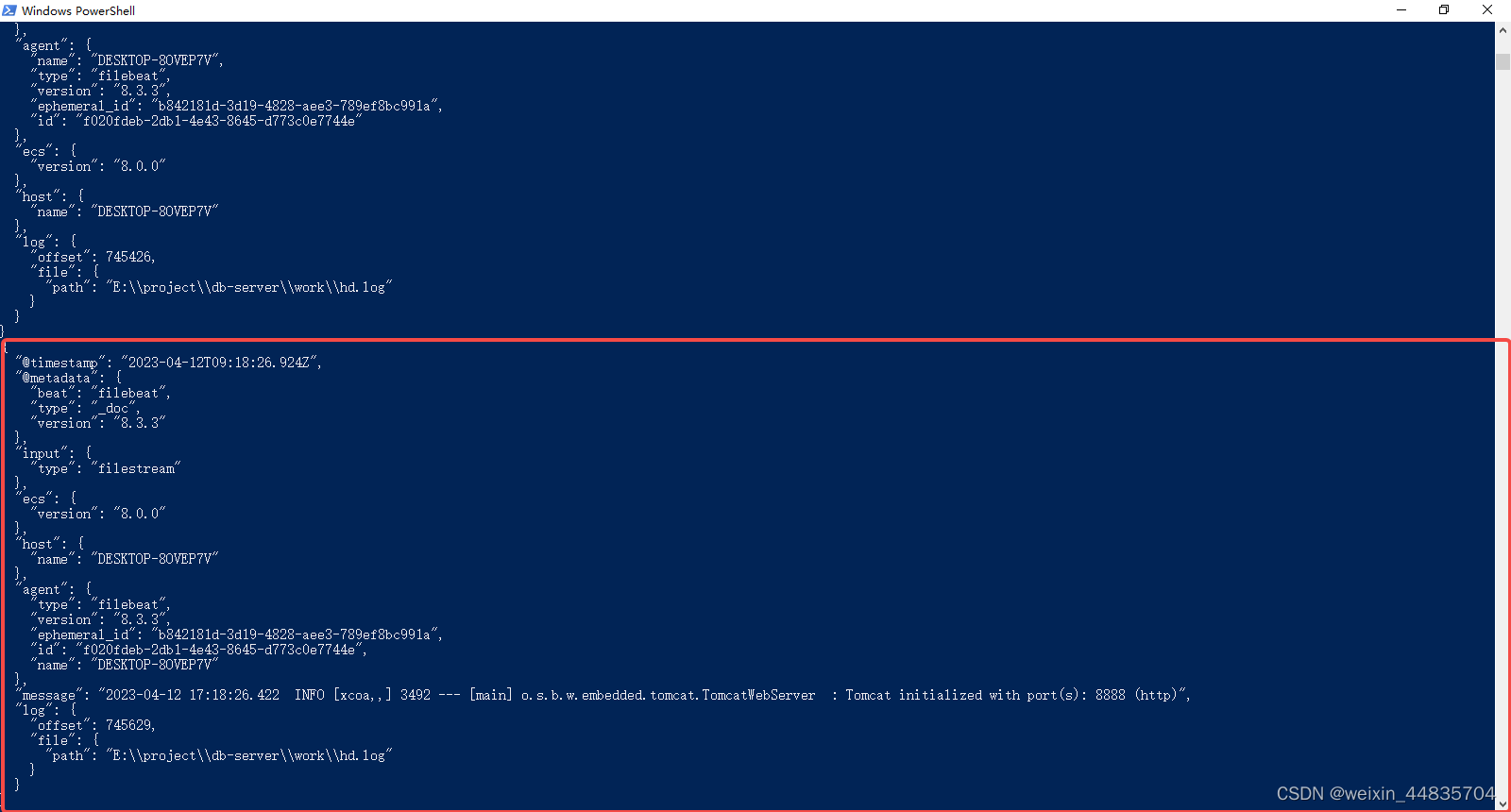
可以看到java应用没一行日志输出被filebeat监听到会在filebeat中形成一个json数据
其中日志的内容在message字段上
9.java异常日志收集问题
filebeat收集日志默认是通过行来收集的,但是java应用程序如果出现报错会在日志中打印出栈信息,就会导致一条日志出现多行内容。
示例如下:
java应用控制台打印了一条错误日志
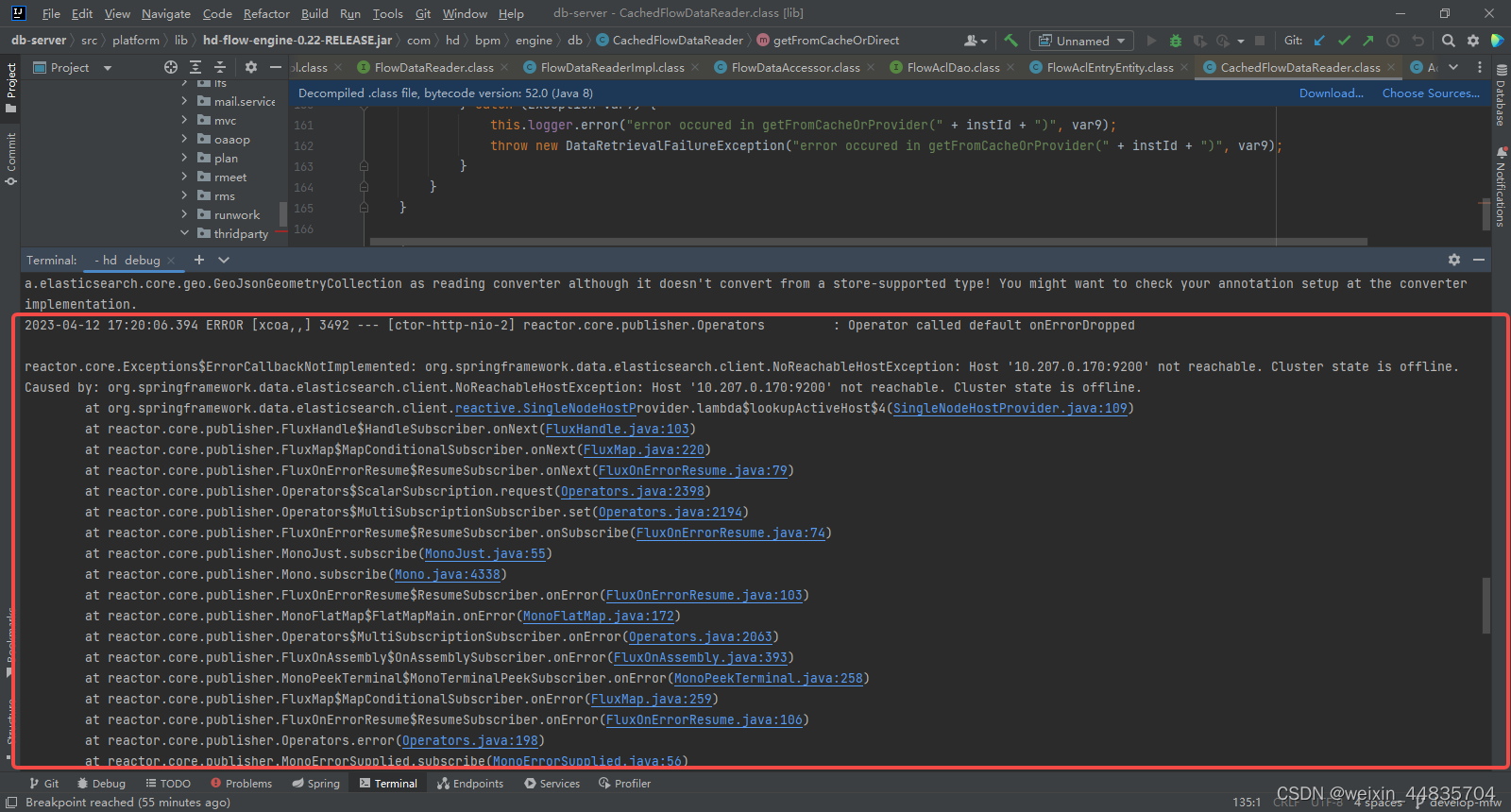
filebeat收集到了多条数据
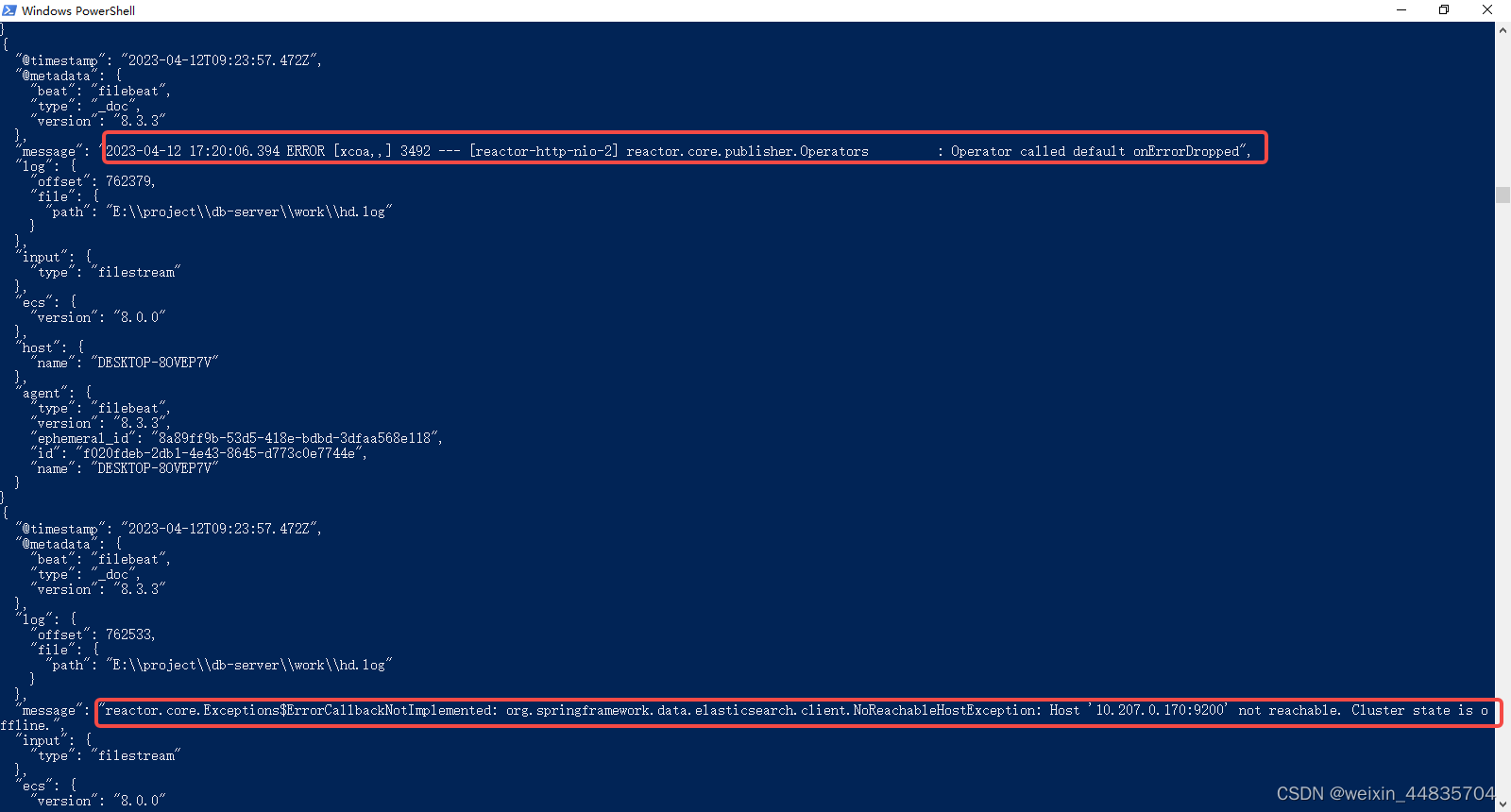
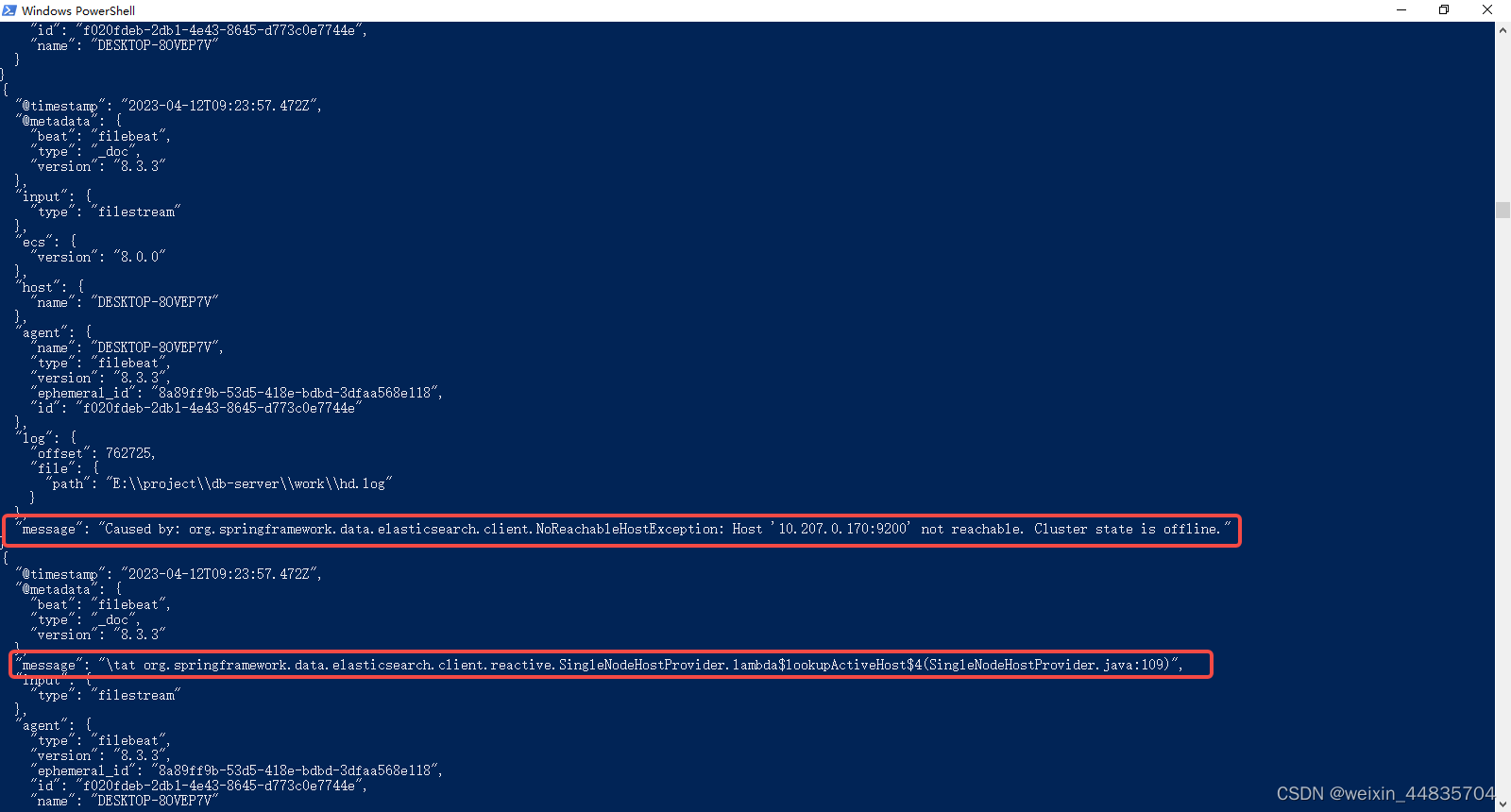
这种情况在大部分场景下是不符合我们的期望的,我们期望每一条数据经过filebeat收集指挥形成一个json数据
9.java异常日志收集问题解决
修改配置文件为:
#filebeat.inputs:
# # 标准输入
#- type: stdin
# enabled: true
filebeat.inputs:
- type: filestream
# Unique ID among all inputs, an ID is required.
id: my-filestream-id
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
#- /var/log/*.log
- E:\project\db-server\work\hd.log
parsers:
- multiline:
type: pattern
pattern: ^[0-9]{4}-[0-9]{2}-[0-9]{2} # 匹配以"年-月-日"时间字符串开始的行
negate: true # 否定上面的匹配;即匹配所有不以"年-月-日"时间字符串开始的行
match: after # 把匹配的行组合到上一个事件中;即将匹配的不以"年-月-日"时间字符串开始的行组合到上一条以"年-月-日"时间字符串开始的行上
# 标准输出
output.console:
pretty: true
enable: true
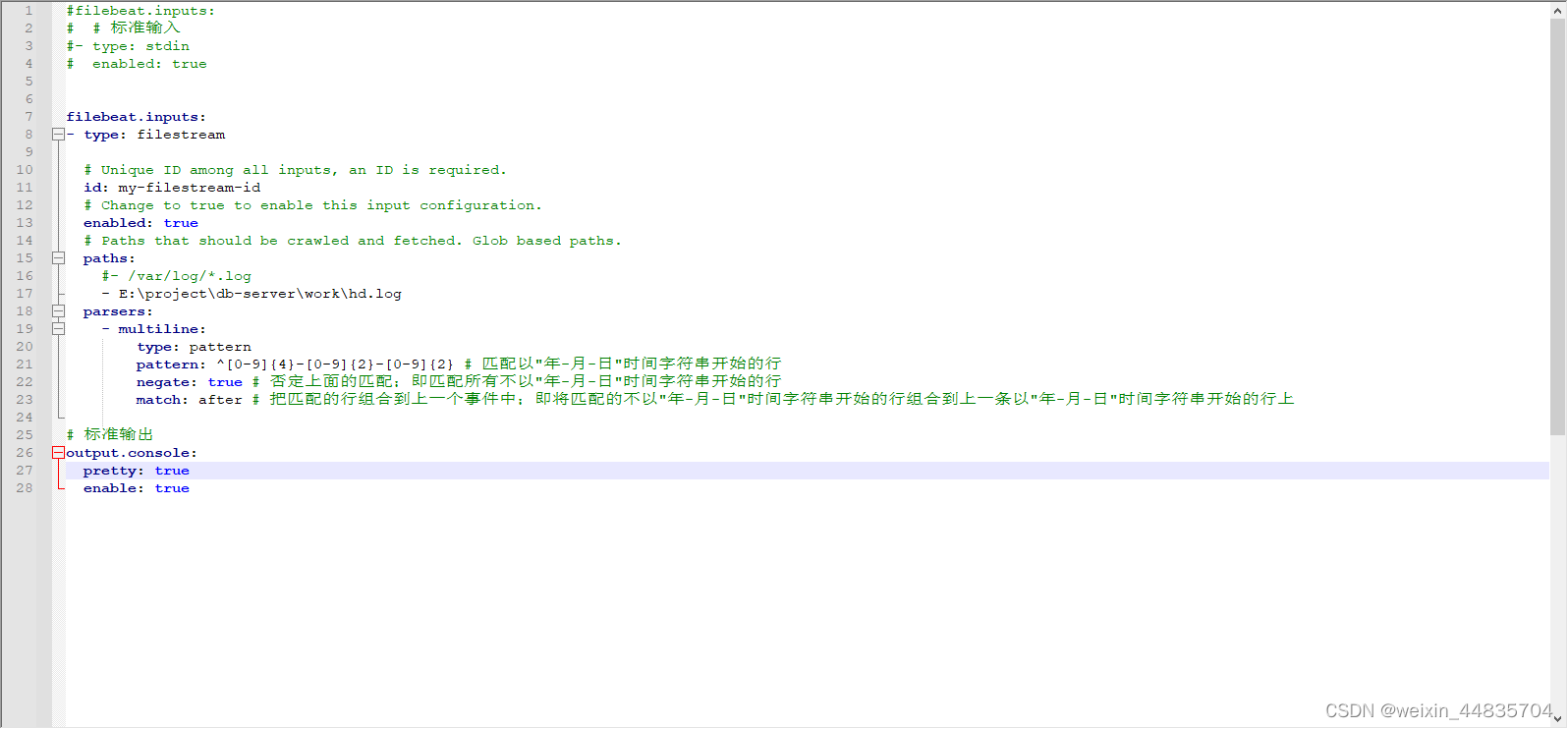
重新启动filebeat
.\filebeat.exe -e -c .\filebeat-test.yml
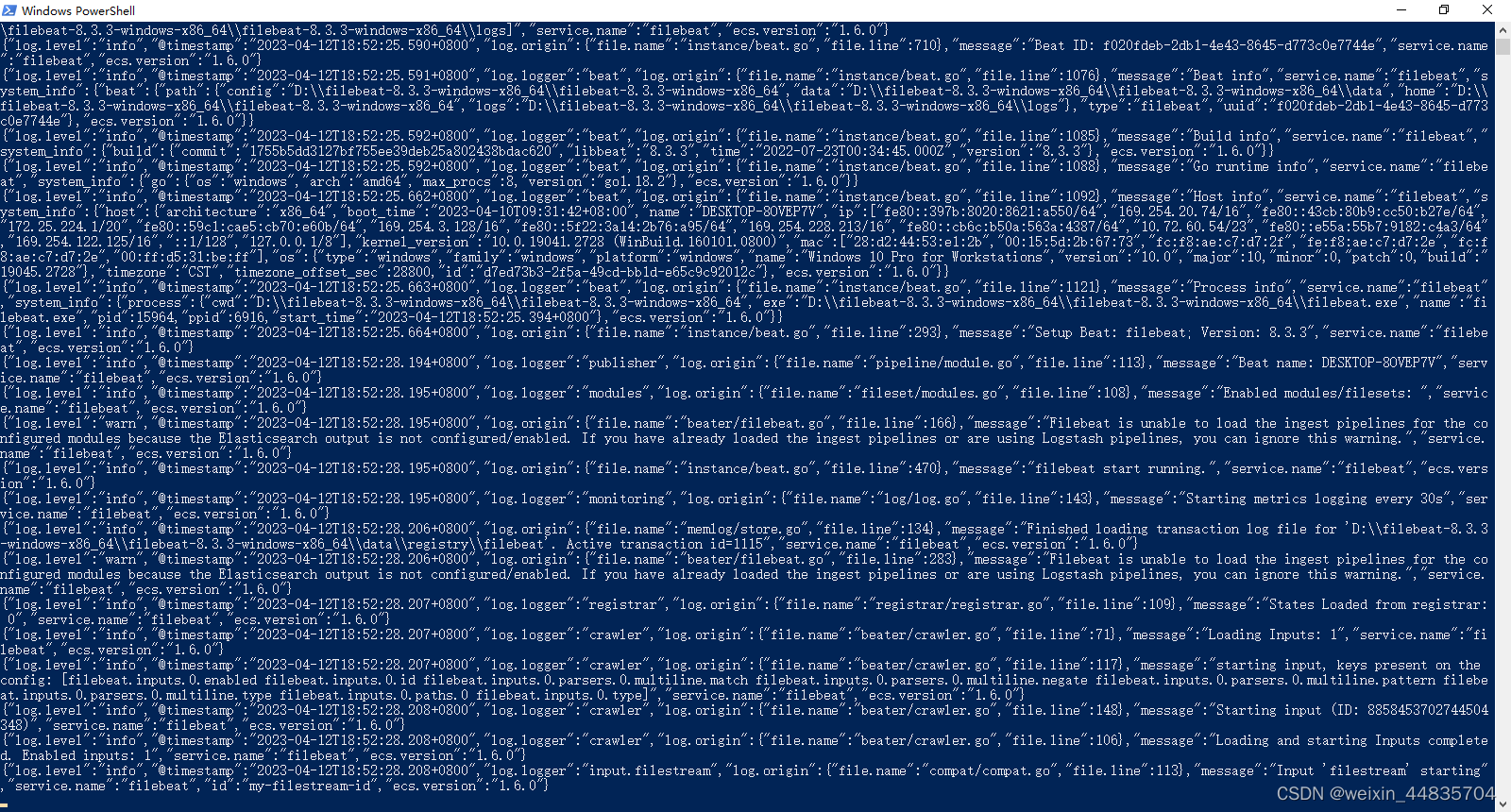
启动java应用,生成错误日志
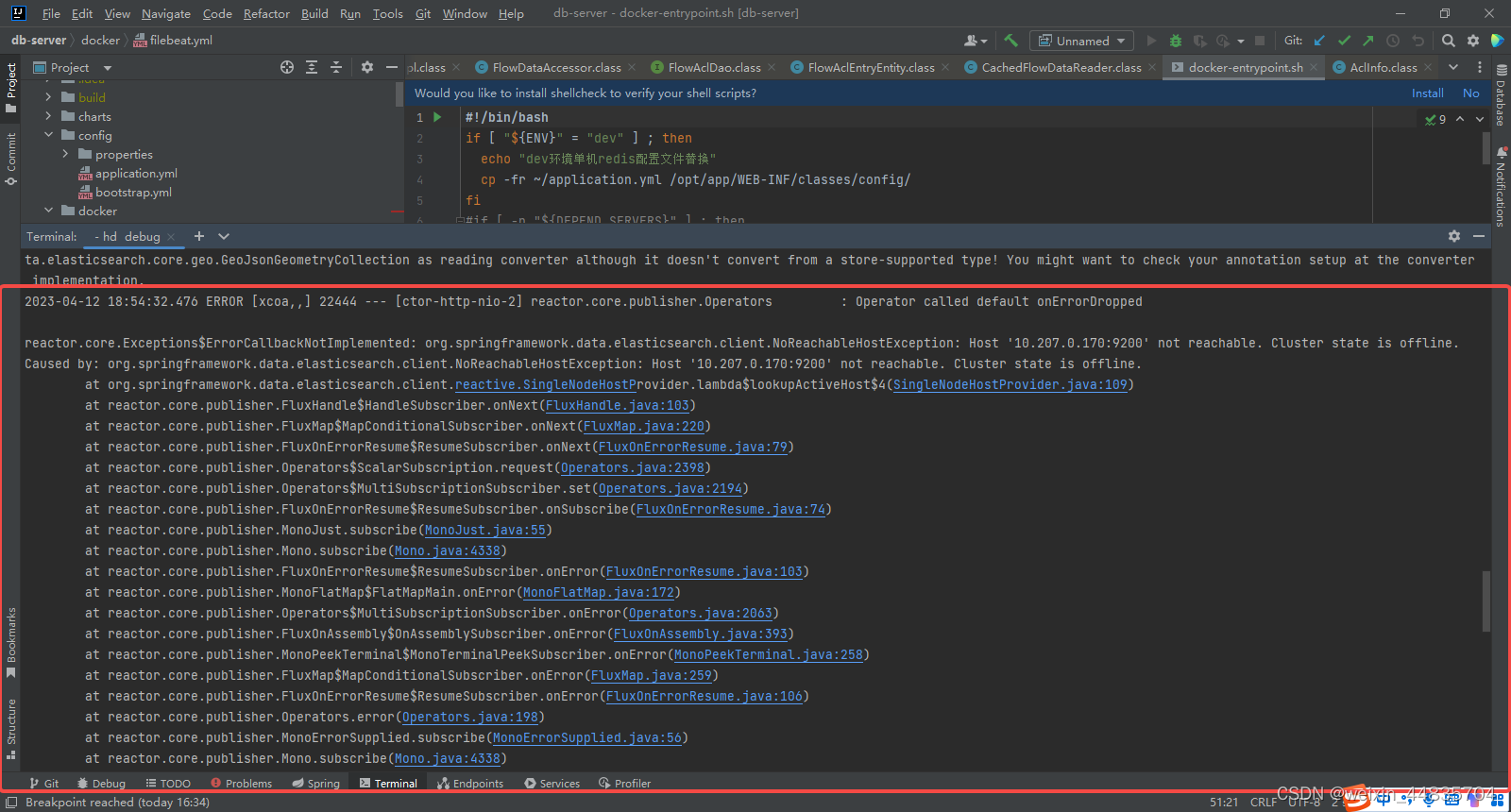
filebeat收集错误日志(此时已经将多行错误日志在filebeat中收集成了一个文档)

10.filebeat输出到logstash
登录服务器查看logstahs输入输出配置

logstash默认监听5044端口的数据作为输入;输出到标准输出流中
修改filebeat配置文件,使其输出到logstash
#filebeat.inputs:
# # 标准输入
#- type: stdin
# enabled: true
filebeat.inputs:
- type: filestream
# Unique ID among all inputs, an ID is required.
id: my-filestream-id
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
#- /var/log/*.log
- E:\project\db-server\work\hd.log
parsers:
- multiline:
type: pattern
pattern: ^[0-9]{4}-[0-9]{2}-[0-9]{2} # 匹配以"年-月-日"时间字符串开始的行
negate: true # 否定上面的匹配;即匹配所有不以"年-月-日"时间字符串开始的行
match: after # 把匹配的行组合到上一个事件中;即将匹配的不以"年-月-日"时间字符串开始的行组合到上一条以"年-月-日"时间字符串开始的行上
# 标准输出
#output.console:
# pretty: true
# enable: true
# 输出到logstash
output.logstash:
# The Logstash hosts
hosts: ["192.168.182.128:5044"]
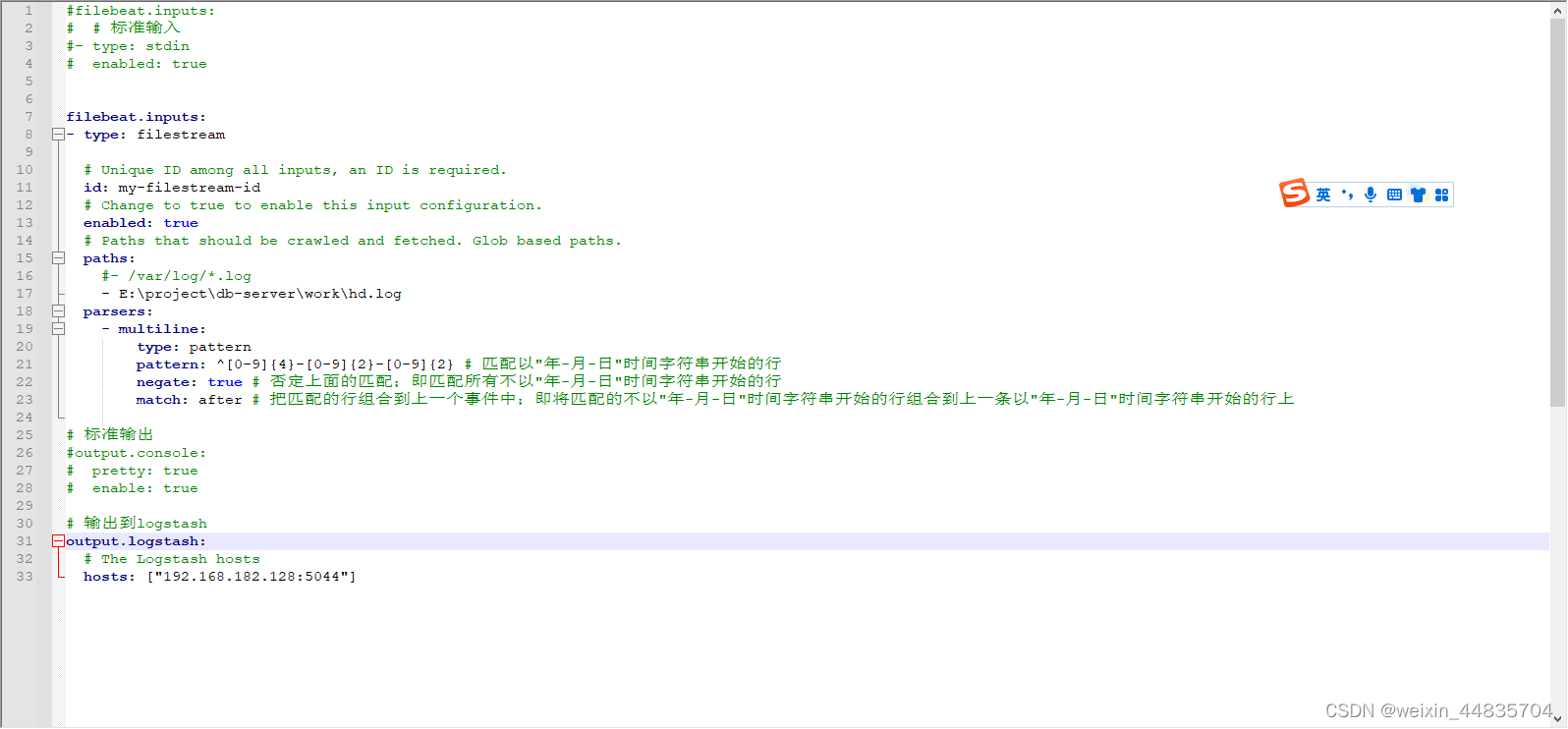
11.重启filebeat
.\filebeat.exe -e -c .\filebeat-test.yml
java应用产生日志
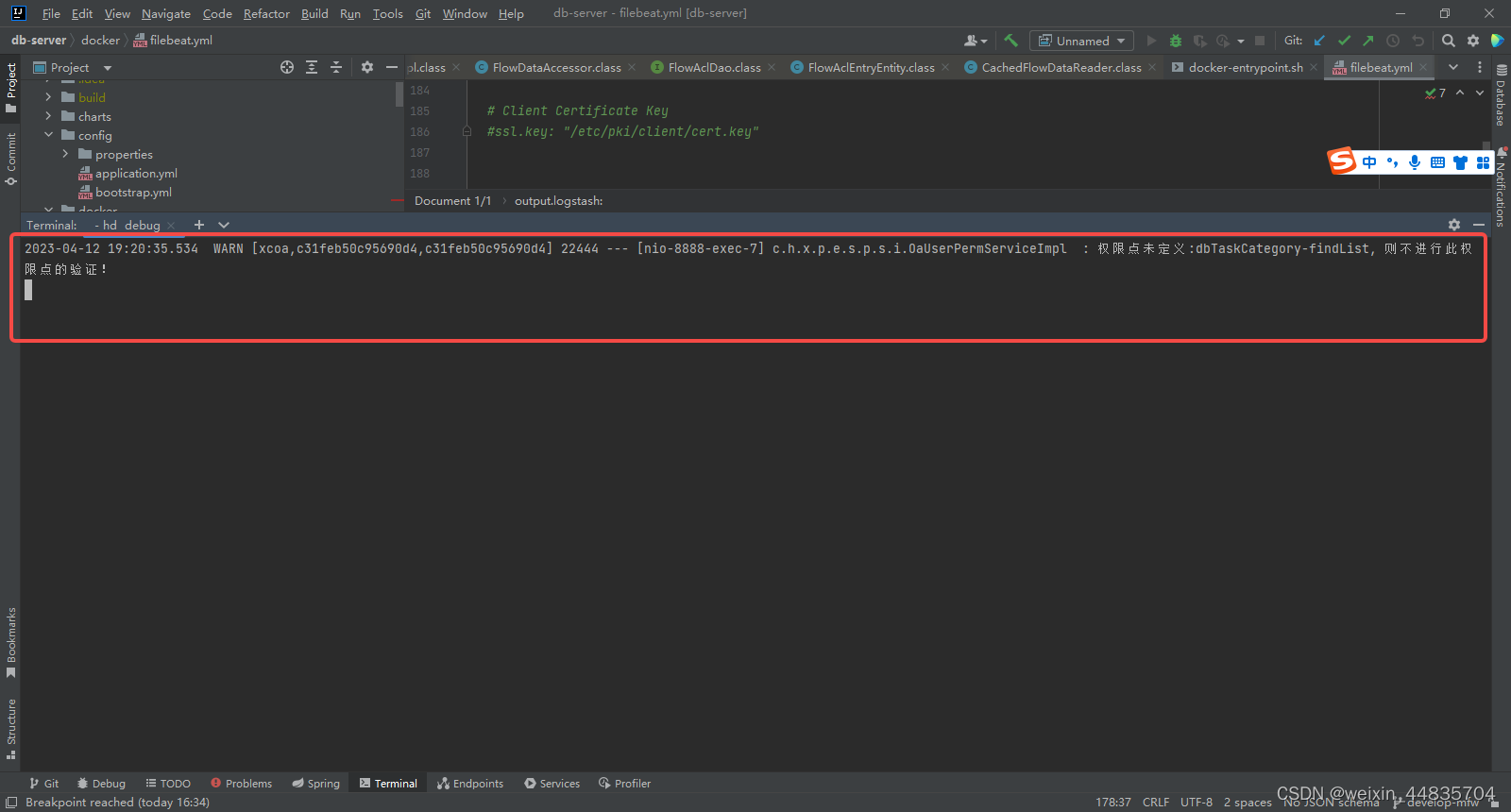
服务器上查看logstash日志
docker logs -f logstash
logstash收到了来自filebeat的日志信息
12.配置自定义化字段
filebeat收集日志的时候还可以添加一些自定义字段添加到json数据中;这些自定义字段在有些时候会很有用,比如想将一个应用在多个环境下的日志存到同一个elasticsearch中,但又希望不同环境的日志生成不同的索引,就可以在收集日志的时候添加对应的字段,然后传到logstahs,在logstash中根据这些自定义字段往不同的索引中存
例如:可以添加如下三个自定义字段
application;代表索引属于那个应用(gatewat,网关服务/user用户服务/auth认证服务等等)
env;环境(dev/sit/uat/prod等等)
log_type;日志类型(access日志/gc日志/普通日志)
配置文件中添加自定义字段位置如下
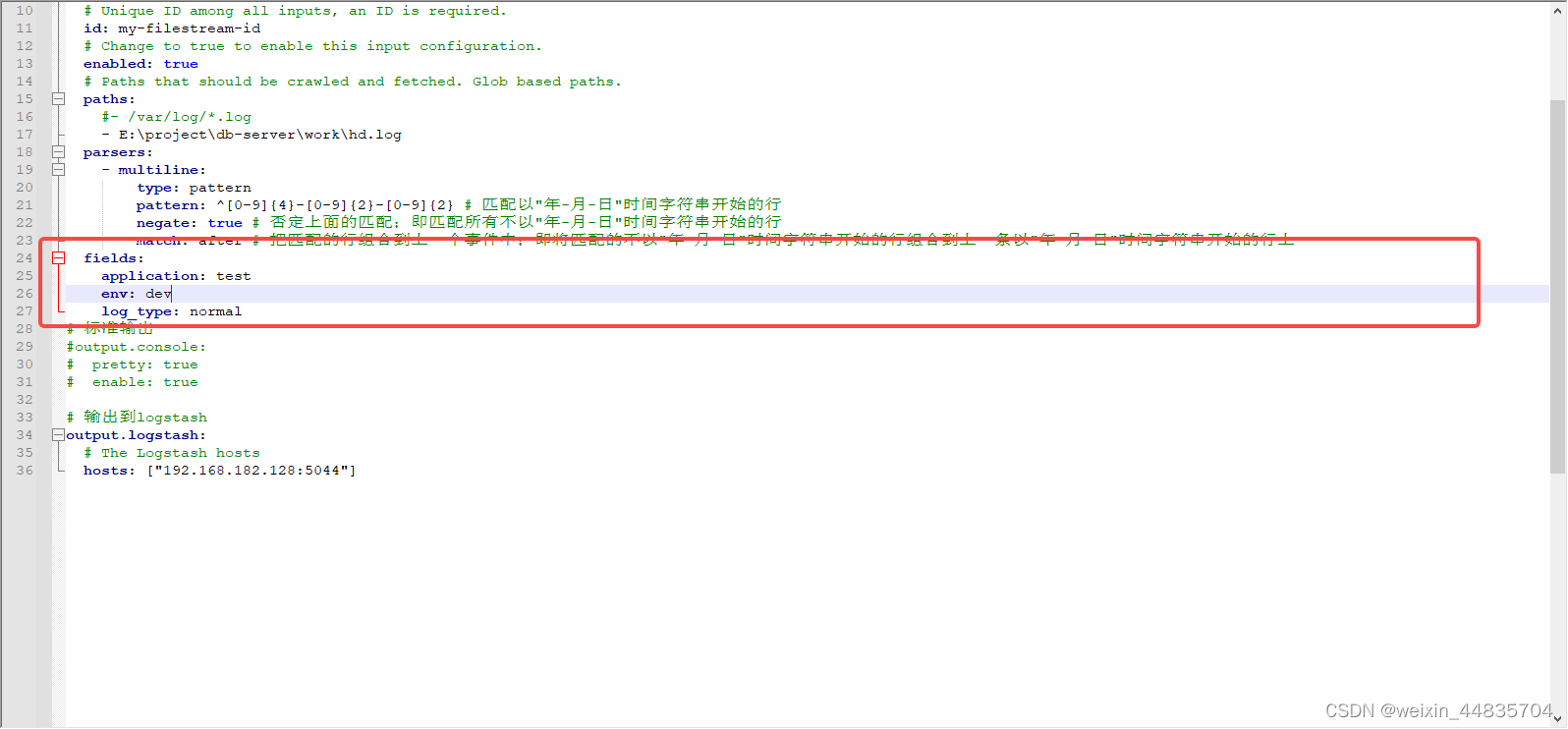
重启filebeat,java后台产生日志,查看logstash日志
可以看到自定义字段已经生效并且正确被logstash所接受,后续就可以在logstah中根据这些自定义字段设置不同的索引
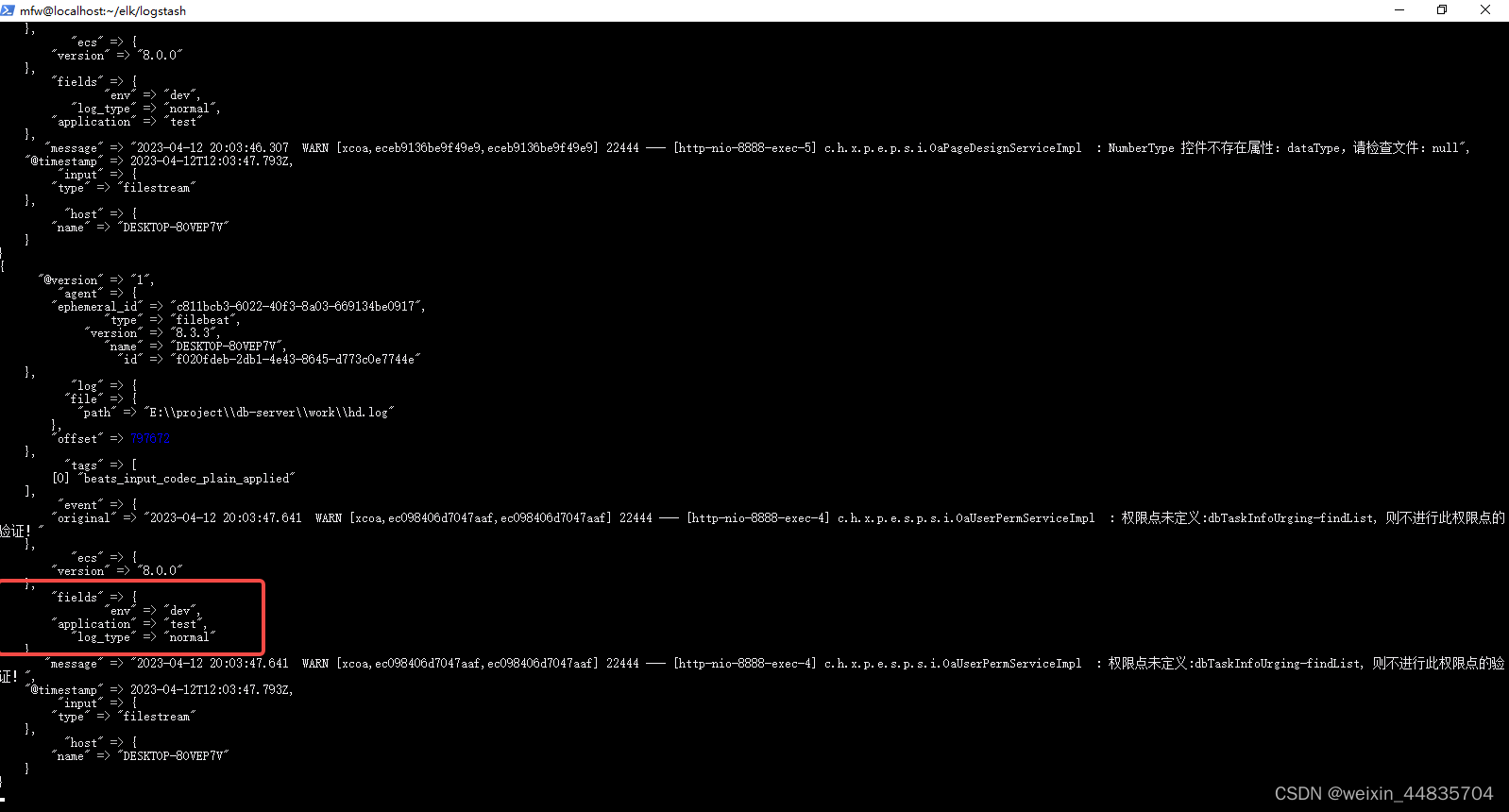
到这里,一个简单的收集java日志的filebeat配置文件就完成了
完整配置内容为
#filebeat.inputs:
# # 标准输入
#- type: stdin
# enabled: true
filebeat.inputs:
- type: filestream
# Unique ID among all inputs, an ID is required.
id: my-filestream-id
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
#- /var/log/*.log
- E:\project\db-server\work\hd.log
parsers:
- multiline:
type: pattern
pattern: ^[0-9]{4}-[0-9]{2}-[0-9]{2} # 匹配以"年-月-日"时间字符串开始的行
negate: true # 否定上面的匹配;即匹配所有不以"年-月-日"时间字符串开始的行
match: after # 把匹配的行组合到上一个事件中;即将匹配的不以"年-月-日"时间字符串开始的行组合到上一条以"年-月-日"时间字符串开始的行上
fields:
application: test
env: dev
log_type: normal
# 标准输出
#output.console:
# pretty: true
# enable: true
# 输出到logstash
output.logstash:
# The Logstash hosts
hosts: ["192.168.182.128:5044"]